DeepMind po šahu, goju in šogiju obvlada tudi igre za Atari
Morda se ne zdi tako, a igrati šah je bistveno laže od igranja še tako primitivne videoigre, kot je na primer Pac-Man. Zato ni presenetljivo, da je umetna inteligenca šah obvladala že leta 1997, igro go leta 2016, videoigre pa – DeepMind pravi, da sedaj.
Razlika je predvsem v togosti okolja, v številu možnih potez, v možnih izidih. Pri šahu in goju so dovoljene poteze zelo dobro znane, njihovo število pa obvladljivo. Go je seveda bistveno kompleksnejši od šaha, a osnovni koncept ostaja enak. Iz zelo jasno določenih pravil se da hitro ugotoviti, katere poteze so dovoljene, od tod pa ostane le premislek, katera bo vodila do najboljšega izida.
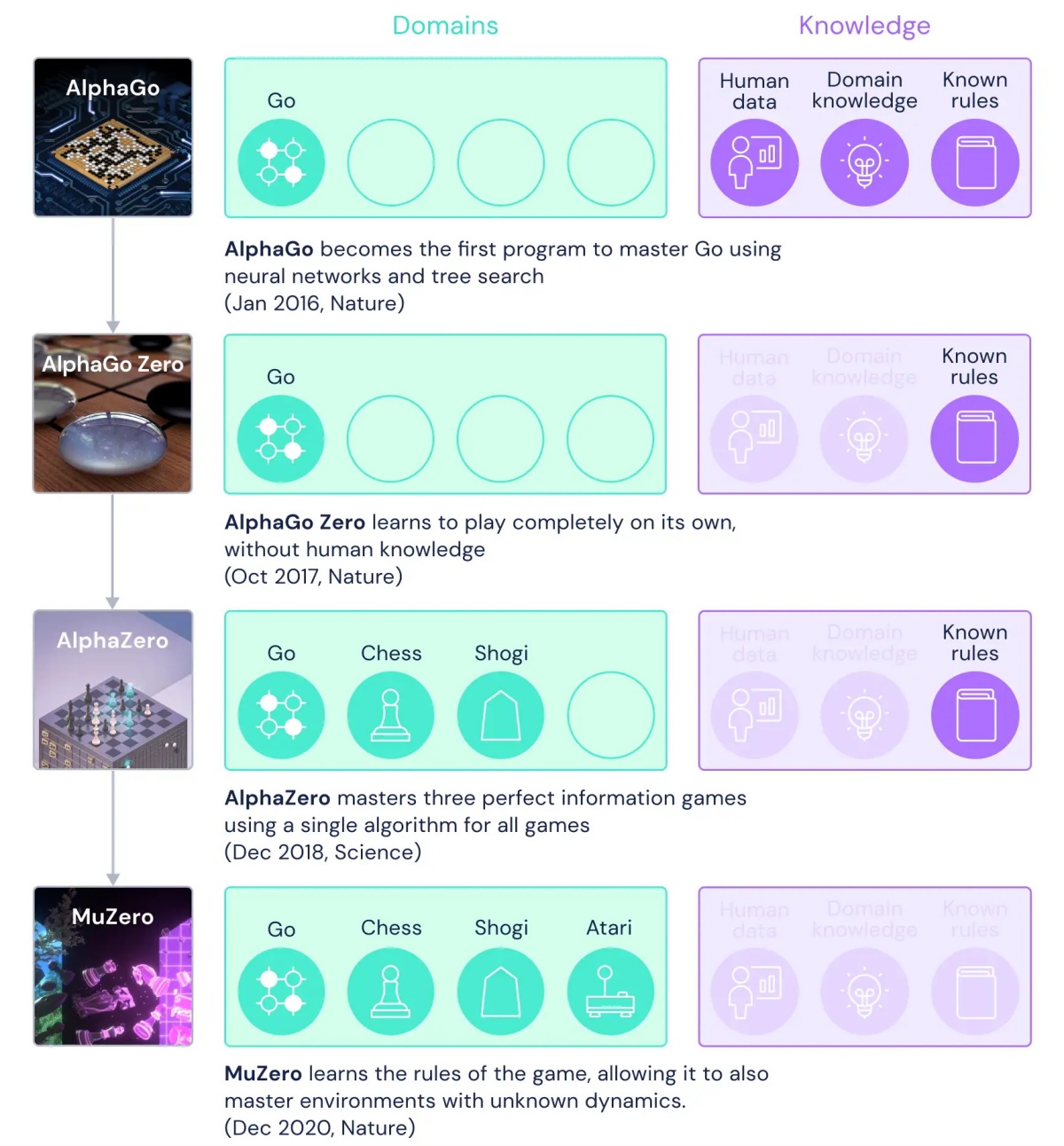
Googlova podružnica DeepMind je že leta 2016 predstavila AlphaGo, ki je v goju zmlel človeškega prvaka. AlphaGo Zero je bil naslednja inačica, ki se ni učila iz tisočerih dobro odigranih partij ljudi, temveč je igrala sama s seboj in se izboljševala. AlphaZero je to kasneje še razširil na druge probleme.
Naslednji korak pa so predstavljale manj definirane igre, kot že omenjeni Pac-Man. Novi algoritem so predstavili te dni in ga poimenovali MuZero. V Nature so znanstveni članek objavili 23. decembra, kar seveda pomeni, da je bil algoritem nared že pred meseci, sedaj pa je še boljši.
MuZero uporablja kombinacijo metod, ki so jih izmojstrili njegovi predhodniki, in dodaja nove. Igranja se uči podobno kot otroci, torej najprej brez pravil, kasneje pa sproti osvaja pravila, dokler ne pozna vseh. Sproti se uči čim boljše strategije. Ko je odigral milijon partij, je bil podobno dober kot AlphaZero v šahu, goju in šogiju.
Ključna novost pa je, da se je naučil tudi 42 iger za Atari. To so bistveno bolj odprti problemi, kjer so pravila ohlapnejša, konfiguracijski prostor dopustnih potez širši, končni cilj pa bolj oddaljen. Končni cilj seveda ni izdelati algoritma, ki bo igral igre za Atari, temveč reševanje realnih problemov. Zvijanje proteinov, optimizacija problema trgovskega potnika, stiskanje podatkov itd. To so problemi, kjer pravil v igri ni, le končni rezultat mora biti v skladu z začetnimi predpostavkami in potrebami. Kompleksne probleme iz realnega sveta je lažje reševati, če pravil ne poznamo, saj nas pravila lahko vkalupijo in usmerijo na suboptimalne poti ali celo v slepe ulice.