Ko je bil svet računalništva še zelo drugačen, smo v 60. letih dobili zmogljivo orodje za iskanje vzorcev v besedilnih nizih. Umetnost regularnih izrazov, ki je bila v času terminalov in besedilnih datotek nepogrešljiva, se zdi danes pozabljena. Grafični vmesniki in umetna inteligenca so njeno poznavanje potisnili na obrobje, a pod površjem modernih nališpanih uporabniških vmesnikov teče več kot pol stoletja star koncept, ki zaradi svoje univerzalnosti in genialnosti alternative nima in je nikoli ne bo imel.

Regularne izraze je v 50. letih izumil Stephen Kleene.
Predstavljajte si, da želite v besedilu poiskati vsa mesta, kjer piki na koncu stavka pomotoma sledita dva presledka. V dobi modernih urejevalnikov besedil to seveda ni težko (Iskanje oziroma Ctrl + F), prav tako jih zlahka zamenjate z enim presledkom. Že če bi želeli na enak način najti vsa mesta, kjer piki, vejici, klicaju, vprašaju, dvopičju ali drugemu ločilu sledita dva presledka, pa bi morali postopek ponoviti (pre)večkrat. Rešitev tega problema ni umetna inteligenca, čeprav bi ga verjetno znala zadovoljivo rešiti, temveč več kot 70 let stara iznajdba. Ameriški matematik Stephen Cole Kleene je leta 1951 opisal koncept regularnih jezikov, ki vsebujejo tudi regularne izraze. Ti so se množičneje začeli uporabljati konec 60. let.
Praštevila - neučinkovito, vendar gre
Z regularnimi izrazi je mogoče storiti marsikaj, kar na prvi pogled sploh ni videti kot iskanje nizov. Znani primer je izraz ^.?$|^(..+?)\1+$, ki se lahko uporabi za preverjanje praštevil. Sestavljata ga dva dela, ki sta ločena z znakom |. Obrnjena strešica pomeni, da se mora vzorec začeti na začetku niza, $ pa da se mora končati pa na koncu. Prvi del, torej ^.?$, pomeni natanko nič ali en znak v celotnem nizu.
Zanimivejši je drugi del ^(..+?)\1+$, kjer ..+ pomeni vsaj dva znaka ali več. Ta zapis torej generira vse mogoče dolžine nizov, od dva dalje. To si lahko predstavljamo kot delitelje števil. Vprašaj v tem primeru ne označuje ponovitve niza, temveč modificira + na način, da postane len (lazy). To pomeni, da vrne najkrajši vzorec iz niza, ki ustreza pravilu. Sledi \1+$, ki poskrbi, da v celotnem nizu iščemo večkratnike niza v prvi skupini.
In to je tudi razlog, da ta trik deluje. Če število pretvorimo v zapis, kjer tolikokrat zapišemo znak 1 – število sedem bi zapisali kot 1111111, petindvajset pa kot prav toliko enic –, bo omenjeni regularni izraz vrnil false za praštevila (ker nimajo nobenega delitelja) in true za sestavljena števila, ker se vsaj en vzorec ponovi.
Seveda je to sila neučinkovit način, ki se v praksi nikoli ne uporablja, a kaže na izjemno moč in prilagodljivost regularnih izrazov. Omenimo še, ker uporablja sklic na prej ujeto skupino \1, to ni več regularni izraz v strogem matematičnem pomenu, temveč razširjena sintaksa, ki jo večina današnjih implementacij podpira.
Regularni izraz je način zapisovanja vzorcev, ki omogoča preprosto iskanje nizov ali njihovo analizo. Opis iz prejšnjega odstavka bi lahko preprosto zapisali kot [.,;:!?]\s{2,}, kjer so v oglatih oklepajih našteti znaki, ki jim sledita dve ponovitvi ali več katerihkoli presledkov (navadnih, tabulatorjev itd.), kar predstavlja \s. Na prvi pogled se zdi takšen zapis sorazmerno nepregleden, a gre za izjemno močno orodje.

Ken Thompson je regularne izraze implementiral v Unixu.
Zgodovina
Regularni izrazi se danes morda res pogosto uporabljajo v programiranju in skriptiranju, a nastali so v matematiki in teoriji računalništva. Zamislil si jih je resda Kleene, a v praktično rabo jih je prenesel eden glavnih ustvarjalcev Unixa Ken Thompson. Konec 60. let jih je uporabil v urejevalniku besedil QED. Prvo različico QED sta sicer leta 1967 napisala Butler Lampson in Laurence Peter Deutsch za operacijski sistem Berkeley Timesharing System, ki je tekel na SDS 940. A Thompson je nato v zbirniku za IBM 7090 napisal QED za operacijski sistem CTSS, ki je vseboval regularne izraze. Dotlej so namreč urejevalniki besedil omogočali le iskanje točno določenega niza in njegove zamenjave, ne pa splošnejših vzorcev. Iz QED so se kasneje razvila priljubljena orodja, kot sta sed in ed, ki sta podedovala tudi regularne izraze.
Priljubljeni ukaz grep v Linuxu izvira iz okolja Unix, kjer je v urejevalniku ed skupina ukazov g/re/p pomenila globalno (po celotnem dokumentu) iskanje z regularnimi izrazi in izpis ujemajočih nizov (print).
Priljubljeni ukaz grep v Linuxu izvira iz okolja Unix, kjer je v urejevalniku ed skupina ukazov g/re/p pomenila globalno (po celotnem dokumentu) iskanje z regularnimi izrazi in izpis ujemajočih nizov (print). »Grepamo« zato še danes, ko v besedilnih datotekah iščemo posamezne izraze. Že v 70. letih so regularne izraze podpirali lex, sed, skriptni jezik AWK in urejevalniki besedil, denimo vi in emacs.
Hierarhija jezikov
Regularnih izrazov ne moremo opisati brez razumevanja hierarhije formalnih jezikov, ki jo je leta 1956 postavil Noam Chomsky. Opisal je formalne slovnice, ki omogočajo ustvarjenje formalnih jezikov. Razdelil jih je v štiri skupine, od tipa 0 do tipa 3. Poenostavljeno povedano je jezike razvrstil glede na to, kako zapletena pravila potrebujemo, da jih opišemo. Posredno določajo tudi omejitve, kaj lahko počnemo z regularnimi izrazi.
K najnižjemu, tretjemu tipu sodijo regularne slovnice oziroma jeziki, ki jih je mogoče opisati z regularnimi izrazi. To so jeziki, ki jih prepozna končni avtomat, kakor imenujemo stroj z omejenim številom stanj in brez dodatnega spomina. Ne potrebuje števcev, sklada ali neskončno velikega pomnilnika, saj mora shraniti le nekaj zadnjih znakov oziroma trenutno stanje.
Ali so regularni izrazi standardizirani
Za regularne izraze ni skupnega standarda. Še najbliže temu je ISO/IEC/IEEE 9945, ki opisuje POSIX (Portable Operating System Interface). V njem so med drugim določeni tudi regularni izrazi za Unixova orodja grep, awk in podobna. POSIX opisuje osnovne (BRE) in razširjene (ERE) regularne izraze. Vse kasnejše razširitve za različne programske jezike predstavljajo nestandardne nadgradnje, ki med seboj niso prenosljive.
Pri drugem tipu so kontekstno neodvisni jeziki, ki za prepoznavo potrebujejo sklad (stack) kot podatkovni tip, zato si lahko zapomnijo neomejeno gnezdene strukture. Prvi tip so kontekstno odvisni jeziki, najvišje (na ničtem tipu) pa so rekurzivni preštevni jeziki, ki jih prepozna in izvaja Turingov stroj. Ti vsebujejo tudi vse preprostejše slovnice. Za potrebe tega prispevka zadostuje vedeti, da so regularni izrazi omejeni in da z njimi ne moremo opisati Turingovih strojev. To je tudi logično, saj so namenjeni manipulaciji z nizi, ne pa aritmetiki.
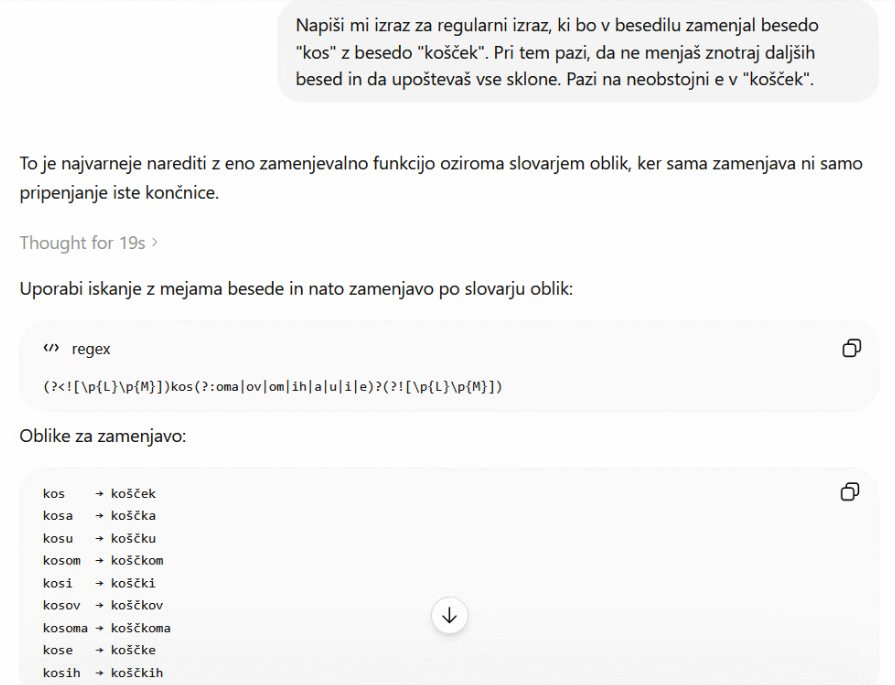
Regularne izraze nam lahko napiše umetna inteligenca, ki predlaga tudi uporabo slovarja.
Moderne implementacije regularnih izrazov sicer presegajo strogo regularne jezike, saj vsebujejo nekatere razširitve, ki formalno niso več opisljive samo pri tretjem tipu. Tak primer je primerjava niza z nečim, kar je regularni izraz našel prej v istem nizu.
Sestavni deli
Regularni izrazi opisujejo nize, pri čemer je najpreprostejši način preprosto navedba niza. Če zapišemo mačka, bo temu zapisu ustrezal samo dobesedno tak naziv. Če bi želeli poloviti še vse nize, kjer pisec ni uporabil strešic, bi zapisali ma(c|č)ka ali ma[cč]ka. V prvem primeru oklepaj predstavlja skupino, in sicer c ali č, saj znak | pomeni ali. V drugem primeru pa so v oglatih oklepajih navedeni vsi mogoči znaki. Zapisa sta torej enakovredna. Pika predstavlja katerikoli znak, obrnjena strešica ^ začetek niza, $ pa konec niza.
Druga, zelo pomembna sintaktična enota so kvantifikatorji, ki se uporabljajo za štetje. Tako ? predstavlja nič ali eno ponovitev, * nič ponovitev ali več, + pa vsaj eno ponovitev. V zavitih oklepajih navajamo točno številko ponovitev, na primer {2}, ali intervale, na primer {2,}, {,2} ali {2,3}.
Če vse to zveni abstraktno, si lahko ogledamo nekaj primerov, ki bodo hitro odpravili številne dvome. Če nam ni mar za končnice, zapišemo mačk.*, ki polovi vse nize, ki se začnejo z mačk in nadaljujejo s poljubnim številom ponovitev (*) kateregakoli (.) znaka. Ker bi se tu znašle tudi besede, kot je mačkojed, lahko omejimo število ponovitev znakov v končnici mačk.{0,3} na največ 3. Prva črka je lahko tudi velika, kar upoštevamo z [Mm]a[cč]k.{0,3} itd., a bi v tem primeru pobrali tudi začetke daljših besed. Omejitev na cele besede omogoča oznaka \b, torej bo \bmačka\b poiskal ponovitve besede »mačka«, ne pa na primer »mačkast«.
Regularni izrazi imajo še vrsto uporabnih podrobnosti, denimo zastavice. Med njimi je pomembna /i, ki ignorira razliko med velikimi in malimi črkami, /g za globalno iskanje (in ne le prve ponovitve) itd. Nekateri so univerzalni, drugi pa so odvisni od implementacije regularnih izrazov.
Zanimiva lastnost kvantifikatorjev je tudi požrešnost (greedy) ali lenost (lazy). V osnovi so kvantifikatorji požrešni, kar pomeni, da poskušajo ujeti najdaljši mogoči niz. Tako bo v nizu »črna mačka« izraz č.*a vrnil najdaljši ujemajoči vzorec, ki se začne s »č« in konča z »a«, torej »črna mačka«. Včasih pa bi želeli najti najkrajši niz. Tedaj mora biti kvantifikator len, kar vključimo z dodatnim vprašajem č.*?a, ki vrne »črna«.
Meje
Na prvi pogled so regularni izrazi videti kot vsemogočno orodje, pravi švicarski nož, s katerim lahko postorimo vse. To je razumljiva skušnjava, a regularni izrazi – kot je jasno že iz hierarhije jezikov, kjer so na najnižji stopnji – niso primerni za vse namene. Z njimi lahko iščemo vzorce, denimo številke računov ali podvojene presledke, ne moremo pa analizirati ali razumeti celotne strukture dokumenta. Kadar je ta odvisna od gnezdenja, medsebojnih referenc, konteksta in slovnice, regularni izrazi ne bodo primerna rešitev.
Formalno bi dejali, da regularni izrazi niso razčlenjevalnik (parser). Če želimo v kodi HTML poiskati vse oznake za začetek hiperpovezav, torej , lahko to hitro storimo. Prav tako lahko (glej okvir) enostavno izluščimo elektronske naslove ali spletne naslove. Po drugi strani pa za analizo poljubnega dokumenta HTML, XML, JSON, programske kode ali tudi matematičnih izrazov niso primerni. Regularni izrazi niso švicarski nož, temveč prej skalpel za natančno odmerjene operacije, ne pa popravljanje celotne stavbe.
Regularnih izrazov je več
Regularni izrazi niso enotni jezik, temveč družina zelo sorodnih izvedb, ki imajo enako osnovo, a nekaj različnih dodatkov in razširitev. Imajo teoretično matematični izvor in so svoje prvo mesto našli v Unixu, kjer so jih uporabljali programi za delo z besedilnimi datotekami v terminalu in skriptah, kot so ed, grep, sed in awk. Osnovni regularni izrazi oziroma BRE (basic regular expression) so bili videti precej drugače od modernih različic, ker smo morali ubežati številnim znakom.
Ubežanje je splošen koncept v programskih jezikih in se uporablja za posebne znake, ki bi jih prevajalnik sicer razumel kot posebne. V regularnih izrazih je * poseben znak, če pa želimo iskati zvezdico v besedilu, ji moramo ubežati. Zapišemo \*. Seveda lahko ubežimo tudi znaku \, kar zapišemo kot \\.
V BRE je bilo treba ubežati nekaterim znakom, ki jih danes lahko normalno uporabljamo. ERE (extended regular expression) je že precej bolj podoben današnjim. Ti so se razcepili oziroma razvili za različne programske jezike in niso povsem enaki. Regularni izrazi za Perl, JavaScript, Python, Javo ali POSIX se razlikujejo v dodatnih funkcionalnostih. To so oziranje na znake pred nizom (lookbehind), podpora za Unicode, poimenovanje skupin in podobno.
Skriti sloj modernih sistemov
Velika verjetnost je, da povprečni uporabnik računalnikov za regularne izraze ni nikoli niti slišal, a jih hkrati verjetno uporablja vsak dan. Ne gre le za programiranje, česar večina ne počne, temveč za iskanje in zamenjevanje nizov v urejevalnikih besedil (Ctrl + F, Ctrl + H). Vsakokrat ko moramo v spletni obrazec vpisati elektronski naslov, datum ali geslo, sistem ustreznost vnosov preveri z regularnimi izrazi. Naprednejši uporabniki, administratorji in podobni jih vsaj v oskubljeni obliki uporabljajo, ko iščejo vnose v dnevniških datotekah in jih filtrirajo, ko pregledujejo velike zbirke podatkov itd. Zapis \d{4}-\d{2}-\d{2} bo našel datume v standardni obliki 2026-01-01, https?://[^\s]+ pa naslove spletnih strani.
Regularni izrazi so zato vgrajeni v praktično vse resne programske jezike, urejevalnike besedil, terminale, iskalna orodja in programe za analizo podatkov, četudi jih morda na prvi pogled ne opazimo. V Linuxu in macOS (ki je tudi unixovski sistem) so regularni izrazi jasno prisotni, a najdemo jih tudi v Windows. Najbolj neposredno so vgrajeni v napredno ukazno vrstico PowerShell, kjer ukazi -match, -replace, Select-String uporabljajo različico regularnih izrazov za .NET. Leta 2024 jih je dobil tudi novi Excel 365, ki ima funkcije REGEXTEST, REGEXEXTRACT in REGEXREPLACE za iskanje (true/false), izpis in zamenjavo nizov na tak način. Zanimivo je, kako Microsoft v svoje programe vgrajuje čedalje več rešitev iz sveta Unix/Linux – navsezadnje je Windows 10 in 11 dobil tudi poln podsistem za Linux.
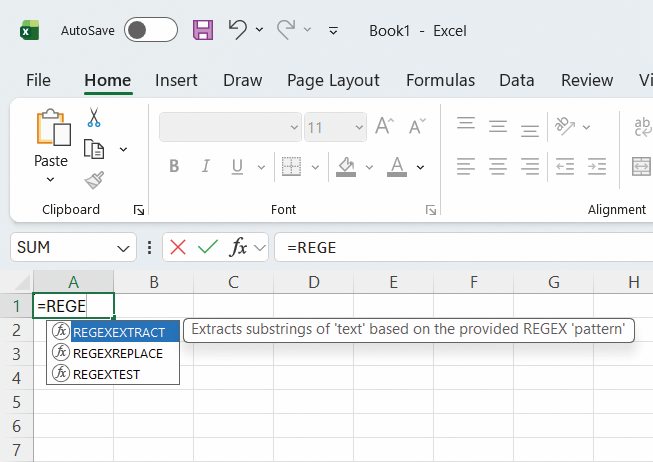
Novi Excel 365 »že« podpira regularne izraze.
Seveda lahko živimo tudi brez regularnih izrazov, saj za veliko večino uporabnikov zadostuje povsem običajni najdi in zamenjaj, le da se moramo znajti. Če bi želeli v besedilu zamenjati vse ponovitve besede »kos« z besedo »košček« v vseh sklonih, bi potrebovali več korakov. Naivna zamenjava bi se namreč izrazila v zelo štajerskih rezultatih, kot so »koščeka« in »koščeku«. Namesto tega bi najprej zamenjali »kosa« s »koščka«, »kosu« s »koščku«, na koncu pa preostali »kos« s »košček«. Da ne bi menjali delov besed, bi iskali » kos « in »kos.«, torej s presledki in z ločili. Vse to je z regularnimi izrazi mogoče storiti bistveno enostavneje, a jih vsi urejevalniki besedil tudi ne podpirajo.
Na koncu se lahko vprašamo, kam sodi v tej zgodbi umetna inteligenca. Seveda ji lahko naročimo, da takšno kompleksno operacijo za nas opravi sama, a drugo vprašanje je, ali ji zaupamo. Precej varnejši način je, da ji naročimo, naj napiše regularni izraz. Tega lahko potem analiziramo sami – ali pa v drugem pogovoru jezikovni model prosimo, naj nam raztolmači regularni izraz. Če smo z njim zadovoljni, ga potem uporabimo na besedilu. S tem obdržimo popoln nadzor, hkrati pa si pohitrimo delo.
In ravno pohitritev ter poenostavitev dela sta žlahtni namen regularnih izrazov. V tem pogledu so podobni matematiki, ki je vedno uporabljamo toliko, kot je poznamo. Škoda bi bilo ostati pri iskanju temena parabole, če obstajajo odvodi. Enako bi se bilo škoda mučiti z Najdi-Zamenjaj, če obstajajo regularni izrazi.