Raziskovalci s Stanforda in Yala so nedavno razkrili nekaj, kar bi razvijalci UI najraje ohranili kot skrivnost. Štirje priljubljeni veliki jezikovni modeli, GPT podjetja OpenAI, Anthropicov Claude, Googlov Gemini in Grok podjetja xAI, so shranili precejšnje odseke knjig, s katerimi so jih urili, in zmorejo ponoviti dolge odlomke iz njih.
Alex Reisner, The Atlantic
Ko so jim raziskovalci dali strateško izbrane ukaze, je Claude skoraj v celoti ponovil besedilo knjig Harry Potter in čarobni kamen, Veliki Gatsby, 1984 in Frankenstein, poleg tega pa še na tisoče besed iz knjig, kot sta Igre lakote in Lovilec v rži. Tudi preostali trije modeli so reproducirali različno dolge odseke iz teh knjig. Pri poskusu so skupno uporabili 13 knjig.
Ta pojav se imenuje pomnjenje. Podjetja iz panoge razvijanja UI so dolgo zanikala, da bi se to dogajalo v velikem obsegu. Open AI je leta 2023 v pismu ameriškemu uradu za avtorske pravice zapisal, da modeli ne shranjujejo kopij podatkov, iz katerih se učijo. Google je uradu sporočil, da v samem modelu ni kopije podatkov, s katerimi so urili model UI, naj gre za besedilo, slike ali drugo obliko. Podobno so zatrdili tudi Anthropic, Meta, Microsoft in drugi. (Nobeno od podjetij za UI, omenjeno v članku, ni pristalo na intervju.)
Stanfordova raziskava dokazuje, da takšne kopije obstajajo, in to je le zadnja v vrsti takšnih raziskav. Med lastnim preverjanjem sem ugotovil, da modeli, ki temeljijo na podobah, lahko reproducirajo nekatere umetnine in fotografije, s katerimi so jih učili. To bi lahko pomenilo ogromno pravno tveganje za podjetja za UI, ki bi jih stalo milijardne odškodnine zaradi kršitev avtorskih pravic, in privedlo do umika izdelkov s trga. Hkrati se to tudi ne ujema z osnovnimi pojasnili o delovanju te tehnologije, ki jih posreduje sama panoga.


Originalna fotografija in izdelek modela Stable Diffusion 1.4.
UI pogosto pojasnjujejo z metaforami. Tehnološka podjetja zatrjujejo, da se njihovi izdelki učijo, da so veliki jezikovni modeli začeli razumeti pisano angleščino, ne da bi jim eksplicitno pojasnili pravila angleške slovnice. Nova raziskava in več študij iz zadnjih dveh let pa te metafore spodkopavajo. UI podatkov ne srka kot človeški um, temveč jih shranjuje in nato dostopa do njih.
Mnogi razvijalci uporabljajo tehnično natančnejši izraz, in sicer izgubno stiskanje. Ta izraz se uveljavlja tudi zunaj panoge. Nedavno ga je uporabilo nemško sodišče, ki je v tožbi nemške organizacije za uprizoritvene avtorske pravice GEMA razsodilo proti OpenAI. GEMA je pokazala, da ChatGPT lahko ustvari različice besedila, zelo podobnega izvirni pesmi. Sodnik je model primerjal z datotekami formata MP3 in JPEG, v katerih se shranjujejo glasba in fotografije v datotekah, manjših od izvirnih nestisnjenih različic. Ko shranimo visokokakovostno fotografijo kot JPEG, nastane nekoliko slabša različica, v nekaterih primerih zamegljena ali pa se pojavijo napake in izkrivljenja. Algoritem izgubnega stiskanja še vedno shrani fotografijo, vendar kot približek in ne kot popolnoma enako datoteko. Od tod pridevnik izgubna – ker se del podatkov izgubi.
Celotna panoga temelji na šepavi metafori.
S tehničnega vidika je stiskanje zelo podobno temu, kar se dogaja znotraj modelov UI, kot so mi v zadnjih mesecih pojasnili raziskovalci iz več podjetij in z različnih univerz. Modeli zajamejo besedila in slike ter ustvarjajo približke teh vhodnih podatkov.
Ta preprosta razlaga je za podjetja za UI manj uporabna kot metafora učenja, na podlagi katere trdijo, da bodo statistični algoritmi, znani kot UI, nekoč pripomogli k novim znanstvenim odkritjem, se nenehno izboljševali in učili sami sebe, kar bi lahko prineslo eksplozije inteligence. Celotna panoga temelji na šepavi metafori.
Težava postane nazorna, če pogledamo generatorje slik. Septembra 2022 je Emad Mostaque, soustanovitelj in takratni direktor podjetja Stability AI, v podkastu pojasnil, kako so razvili model Stable Diffusion. Razložil je, da so sto tisoč gigabajtov slik stisnili v dvogigabajtno datoteko, ki lahko poustvari katerokoli od teh podob in njihove različice.
Eden od številnih strokovnjakov, s katerimi sem govoril med pripravo tega članka, je neodvisni raziskovalec UI, ki je preučeval funkcijo modela Stable Diffusion, da reproducira slike iz učnega materiala. (Privolil sem, da ostane anonimen, ker se boji posledic velikih podjetij v panogi UI.) Pokazal mi je izvirnik s spleta, promocijsko fotografijo iz televizijske serije Garfunkel in Oates, ter nato različico, ki jo je ustvaril Stable Diffusion z ukazom, enakim kot je podnapis pod objavljeno fotografijo na spletu, in vključuje tudi nekaj koda HTML: 'IFC ukinja Garfunkel in Oates.' S to preprosto tehniko je raziskovalec lahko ponazoril, kako ustvariti skoraj popolne kopije več deset slik, za katere se ve, da so del učnega materiala za Stable Diffusion, pri čemer večina vključuje vizualne sledi, podobne izgubnemu stiskanju – nekakšno zamegljenost ali motnost, kot jo občasno lahko opazimo tudi na svojih fotografijah.
Drugi primer je iz tožbe proti podjetju Stability AI in drugim. Primerjava med izvirnim delom Karle Ortiz in različico modela Stable Diffusion pokaže, da je razlika med njima nekoliko večja. Nekaj elementov je drugačnih. Namesto stiskanja pikslov je algoritem očitno kopiral in priredil predmete z več slik, vendar je ohranil neko vizualno kontinuiteto.
Podjetja pojasnjujejo, da algoritmi UI iz učnih podatkov izluščijo koncepte in se naučijo ustvarjati izvirna dela, toda reprodukcija ni le rezultat konceptov. To ni neka splošna podoba, na primer angela s pticami. Težko je natančno določiti, zakaj neki model UI doda točno določeni element na sliko, lahko pa utemeljeno sklepamo, da Stable Diffusion reprodukcijo delno zmore ustvariti zato, ker je shranil vizualne elemente iz originala. To ni kolaž, kot bi bila fizično rezanje in lepljenje, hkrati pa tudi ni učenje v človeškem pomenu besede. Model nima čutov in zavestnih izkušenj, na podlagi katerih bi samostojno estetsko presojal.
Google je zapisal, da veliki jezikovni modeli ne shranjujejo kopij učnih podatkov, temveč vzorce v človeškem jeziku. To je na videz res, vendar se izkaže za zavajajoče, ko pogledamo podrobneje. Kot je dobro dokumentirano, podjetje besedilo knjige, ki jo uporabi za razvoj modela UI, razdeli na manjše dele oziroma žetone. Na primer pozdrav 'Živijo, prijatelj moj' bi lahko predstavili z žetoni ži vi jo pri ja telj moj. Nekateri žetoni so dejanske besede, drugi so zgolj skupine črk, presledkov ali ločil. Model shrani žetone in kontekst, v katerem se pojavljajo. Veliki jezikovni model je tako v bistvu ogromna zbirka kontekstov in žetonov, ki bodo najverjetneje sledili.
Model si lahko predstavljamo kot zemljevid. Vzemimo za primer dejanske najverjetnejše žetone iz Metinega modela Llama-3.1-70B:
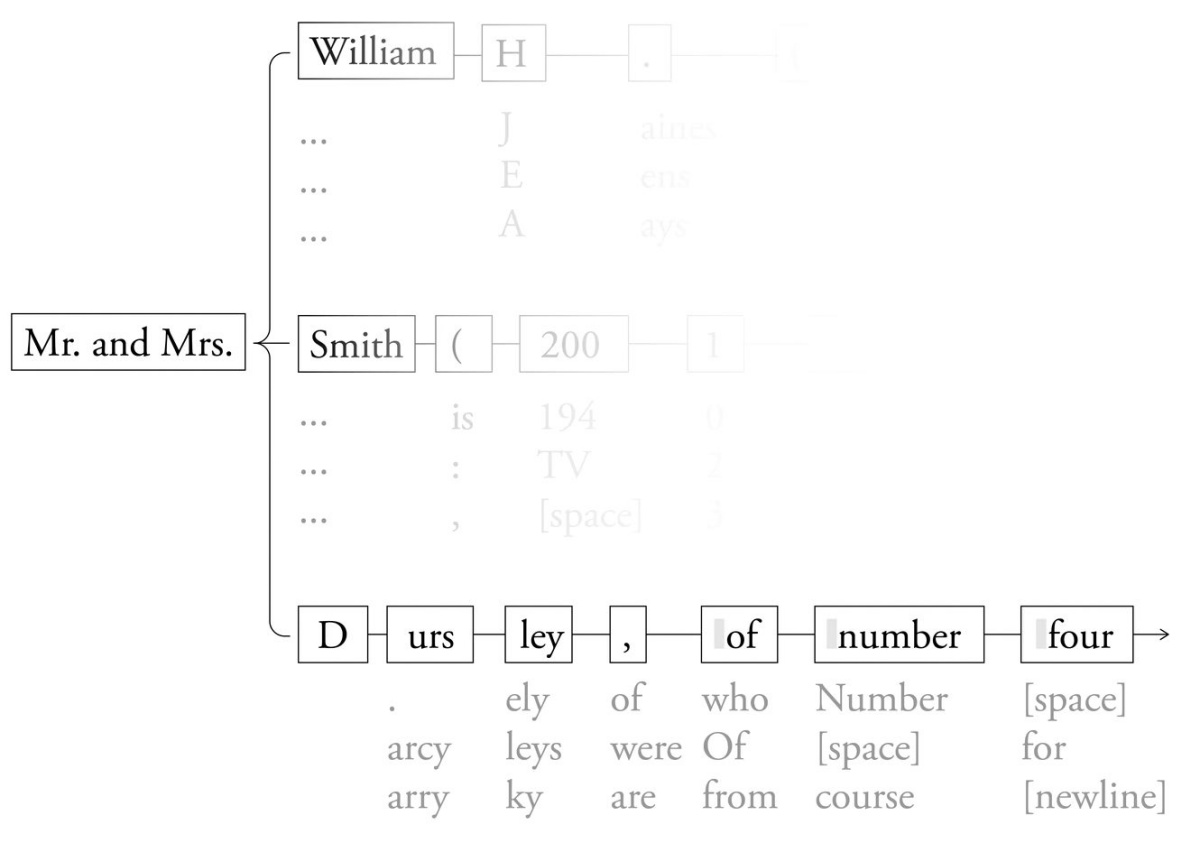
Ko veliki jezikovni model piše stavek, se premika po poti skozi gozd mogočih zaporedij žetonov in na vsakem koraku izbere najverjetnejšega. Googlov opis je zavajajoč, ker napovedi naslednjega žetona ne izvirajo iz neoprijemljive entitete, kot je človeški jezik, temveč iz konkretnih knjig, člankov in drugih besedil, ki jih je model obdelal.
Modeli se včasih privzeto oddaljijo od najverjetnejšega naslednjega žetona. To vedenje podjetja za UI pogosto predstavljajo kot metodo za spodbujanje ustvarjalnosti modelov, vendar ima tudi to prednost, da prikriva kopiranje besedila, s katerim so ga učili.
Včasih je jezikovni zemljevid tako podroben, da vsebuje natančne kopije celih knjig in člankov. Lani poleti je raziskava več velikih jezikovnih modelov pokazala, da Metin model Llama 3.1-70B podobno kot Claude lahko dejansko ponovi celotno besedilo knjige Harry Potter in kamen modrosti. Raziskovalci so modelu posredovali le prvih nekaj žetonov knjige,'Gospod in gospa D'. V notranjem jezikovnem zemljevidu modela Llama je najverjetneje sledilo 'ursley z Rožmarinove štiri sta bila nadvse ponosna, da sta popolnoma običajni človeški bitji'. To je točno prva poved v knjigi. Ko so dobljeni rezultat vedno znova vnašali kot nove vhodne podatke, je Llama nadaljeval v istem slogu, dokler ni ustvaril cele knjige, pri čemer je izpustil le nekaj kratkih stavkov.
S to tehniko so raziskovalci pokazali tudi, da je Llama brez izgub stisnil velike odseke drugih del, na primer znameniti esej Ta-Nehisija Coatesa The Case for Reparations (Argumenti za reparacije), objavljen v reviji The Atlantic. Ko so v model kot ukaz vpisali prvo poved eseja, se je iz njega usula ploha več kot 10.000 besed oziroma približno dve tretjini eseja. Obsežni izseki nastanejo tudi za dela, kot so Igre prestolov Georgea R. R. Martina, Ljubljena pisateljice Toni Morrison in druga.
Pri razvoju Stable Diffusion so sto tisoč gigabajtov slik stisnili v dvogigabajtno datoteko, ki lahko poustvari katerokoli od teh podob in njihove različice.
Raziskovalci s Stanforda in Yala so prikazali tudi, da GPT 4.1 vsebino knjige lahko ponovi po svoje namesto dobesedno. Kljub temu je tako kot v primeru Stable Diffusion rezultat modela izjemno podoben izvirniku.
To ni edina raziskava, ki dokazuje pogosto plagiatorstvo modelov UI. Po neki raziskavi povprečno od 8 do 15 odstotkov besedila, ki ga ustvarijo veliki jezikovni modeli, že obstaja na spletu v povsem enaki obliki. Klepetalniki rutinsko kršijo etične standarde, ki običajno veljajo za ljudi.


Izvirno umetniško delo Karle Ortiz (The Death I Bring, 2016, grafit) in izhod iz Stabilityjevega izdelka Reimagine XL, ki temelji na Stable Diffusion XL.
Pomnjenje bi lahko imelo tudi vsaj dve vrsti pravnih posledic. Prvič, če je pomnjenje neizogibno, bodo morali razvijalci UI preprečiti, da bi uporabniki dostopali do shranjenih vsebin – tako pravijo pravni strokovnjaki in vsaj eno sodišče je to že zahtevalo. Toda obstoječe tehnike je mogoče zlahka zaobiti. Neodvisna medijska družba 404 Media je poročala, da Sora 2 podjetja OpenAI ni ustregla ukazu, naj ustvari video priljubljene videoigre Animal Crossing, medtem ko je ukaz izpolnila, če je bilo ime igre zapisano napačno, kot crossing aminal 2017. Če podjetja ne morejo zagotoviti, da njihovi modeli nikoli ne bodo kršili avtorskih pravic piscev ali umetnikov, bi sodišče lahko zahtevalo umik izdelka s trga.
Drugi razlog, zaradi katerega podjetja za UI morda kršijo avtorske pravice, pa je, da bi že sam model lahko šteli za protizakonito kopijo. Mark Lemley, predavatelj prava na Stanfordu, ki je v takšnih tožbah zastopal Stability AI in Meto, mi je povedal, da ni prepričan, ali je pravilno reči, da model vsebuje kopijo knjige, ali pa ima niz navodil, ki mu omogočajo sproti ustvariti kopijo kot odgovor na ukaz. Tudi zadnje je lahko problematično, a če sodniki presodijo, da velja prvo, tožniki nemara lahko zahtevajo uničenje spornih kopij. To pomeni, da bi podjetja za UI razen glob včasih morala računati tudi na možnost, da jih bo sodišče prisililo k vnovičnemu učenju čisto od začetka z ustrezno licenciranim gradivom.
V tožbi je The New York Times trdil, da GPT 4 lahko skoraj dobesedno reproducira desetine njegovih člankov. OpenAI (ki poslovno sodeluje z revijo The Atlantic), je odgovoril, da je časopis uporabil zavajajoče ukaze, ki kršijo pogoje uporabe podjetja, in v model vnesel odlomke iz člankov. »Navadni uporabniki izdelkov OpenAI ne uporabljajo na tak način.« Podjetje je celo trdilo, da je časopis nekomu plačal, da je vdrl v izdelke OpenAI, in takšen tip reprodukcije označilo za redkega hrošča, ki se ga trudijo popolnoma odpraviti.
Po neki raziskavi povprečno od 8 do 15 odstotkov besedila, ki ga ustvarijo veliki jezikovni modeli, že obstaja na spletu v povsem enaki obliki.
Toda nove raziskave jasno kažejo, da je plagiatorstvo GPT-4 in vsem drugim večjim velikim jezikovnim modelom vrojeno. Nihče od raziskovalcev, s katerim sem govoril, ni menil, da je temeljna lastnost, to je pomnjenje, nenavadna ali da bi jo bilo mogoče onemogočiti.
V sporih zaradi avtorskih pravic metafora z učenjem podjetjem omogoča zavajajoče primerjave med klepetalniki in ljudmi. Vsaj eden od sodnikov, ki obravnavajo takšne primere, se je oprl na to primerjavo ter krajo in skeniranje knjig podjetja za UI primerjal s poučevanjem otrok o tem, kakšna so pravila dobrega pisanja. V dveh tožbah so sodniki razsodili, da je učenje velikega jezikovnega modela z avtorskimi knjigami primer dopustne uporabe, vendar je obema razsodbama mogoče očitati napačno razlago pomnjenja. Prvi sodnik se je skliceval na strokovno pričanje, da Llama lahko reproducira največ 50 žetonov iz knjig tožnikov, čeprav poznejše raziskave dokazuje nasprotno. Drugi sodnik se je strinjal, da si je Claude zapomnil obsežne dele knjig, vendar po njegovem mnenju tožniki niso zadostno utemeljili, da je to problematično.
Raziskave o tem, kako modeli UI ponovno uporabljajo vsebine iz učnih podatkov, so še vedno v zgodnji fazi, delno zato, ker je podjetjem za UI v interesu, da tako tudi ostane. Več raziskovalcev mi je med pripravo tega članka povedalo, da so nekatere raziskave o pomnjenju cenzurirane ali pa so objavo ovirali pravniki podjetij. Nihče od raziskovalcev o teh primerih ni želel govoriti javno, ker se bojijo povračilnih ukrepov podjetij.
Medtem direktor OpenAI Sam Altman zagovarja 'pravico' tehnologije, da se uči iz knjig in člankov kot človek. Ta zavajajoča in na prvi pogled pomirjujoča predstava preprečuje javno razpravo o tem, kako podjetja za UI uporabljajo ustvarjalna in intelektualna dela, od katerih so navsezadnje popolnoma odvisna.