Kako preživeti v svetu digitalnih iluzij?
V zadnjih letih se je splet napolnil z vsebinami, ki jih je vedno težje ločiti od človeških. Umetni so besedila, fotografije, celo videoposnetki in glasovi. Z generativnimi modeli je mogoče zelo hitro ustvariti prepričljivo novico, oglas, dokazni posnetek ali mnenje, ki ga ljudje nato delijo naprej. Dobra novica je, da se večina ponaredkov še vedno razkrije pri majhnih, praktičnih podrobnostih. Še boljša pa je, da lahko z nekaj vaje in nekaj orodji tveganje, da nasedemo, precej zmanjšamo.
V svetu, kjer umetno inteligenco vse pogosteje uporabljamo za pisanje e-poštnih sporočil, poročil, člankov in celo novic, postaja vprašanje pristnosti besedil ključno. Čeprav so izdelki programov, kot je ChatGPT, pogosto izjemno prepričljivi in človeški, jih paradoksalno najbolje prepoznajo prav drugi računalniški programi. Orodja za zaznavanje umetne inteligence služijo različnim namenom, od pomoči avtorjem, da njihovo pisanje ne deluje preveč robotsko, do odkrivanja zavajanja pri kandidatih za zaposlitev. Najbolj so nad temi rešitvami navdušeni učitelji in profesorji, ki se soočajo z izzivom akademske poštenosti, čeprav se morajo zavedati, da so detektorji lahko prav tako nezanesljivi kot generatorji. Zgodbe o študentih, ki so bili po krivici obtoženi uporabe tehnologije, opozarjajo na nevarnosti slepega zaupanja tem algoritmom. Ker je umetna inteligenca zasnovana tako, da čim natančneje posnema človeški govor, je ločevanje med naučenimi vzorci in pristnim človeškim izražanjem izjemno zahtevno. Nekatera orodja, kot je GPTZero, analizirajo zapletenost idej in raznolikost dolžine stavkov, vendar celo njihovi ustvarjalci opozarjajo, da rezultati ne bi smeli biti edina osnova za kaznovanje. Testiranja kažejo, da so ti programi sicer dobri pri prepoznavanju strojno ustvarjenih besedil, vendar pogosto napačno označijo povsem človeško pisanje kot delo umetne inteligence, kar povzroča nemalo skrbi v strokovnih in akademskih krogih.
Uporaba programskih orodij za prepoznavanje umetnointeligenčne pomoči v besedilih je preprosta, saj običajno ne zahteva več kot lepljenje sumljivega vzorca v osrednje vnosno polje.
Osnovna zamisel takšnih orodij je, da uporabnik kopira oziroma drugače posreduje vprašljivo besedilo, nato pa ta po podrobni analizi ocenijo, ali gre za človeško delo ali izdelek umetne inteligence. Glede na izbrano storitev pripomočki ponudijo tudi stavke, ki zvenijo najbolj človeško, ter dele, za katere menijo, da so strojni. Vsi po vrsti obljubljajo visoko stopnjo natančnosti, vendar so njihovi rezultati v praksi mešani. Nekateri detektorji so preveč popustljivi in strojno besedilo označijo za človeško, drugi pa pretirano sumničavi do unikatnega sloga pravih avtorjev. Kljub hitremu razvoju tehnologije in poskusom uvajanja digitalnega označevanja ostaja dejstvo, da nobena programska oprema ni nezmotljiva. Človeška presoja in kritična analiza tako ostajata nepogrešljivi pri končni oceni verodostojnosti vsakršnega besedila.
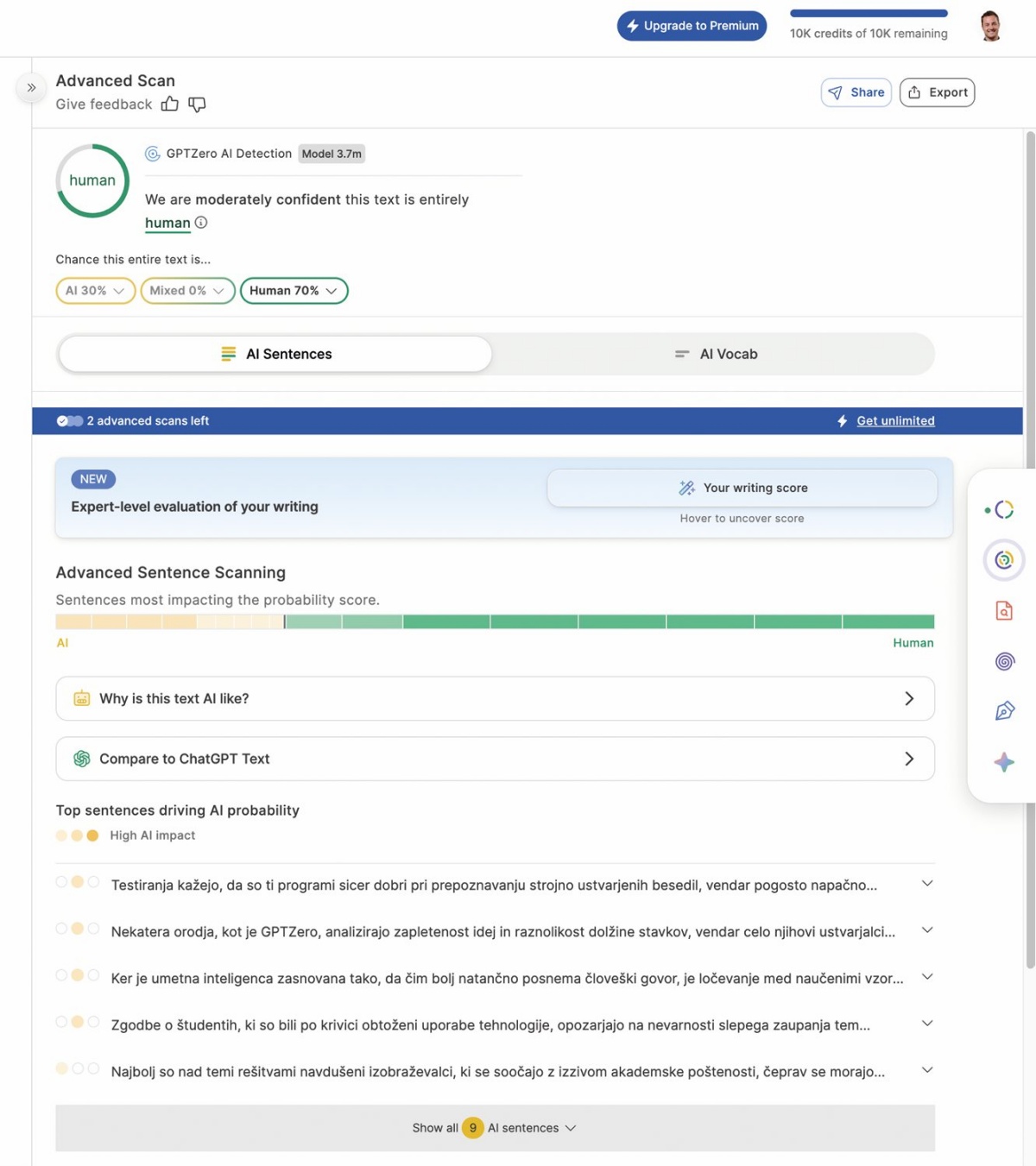
GPTZero poleg samozavestne ocene o pristnosti besedila ponuja tudi podrobnejšo razčlenitev, ki nam pomaga pri končni sodbi.
Presenetljivo dober filter za preverjanje verodostojnosti zapisanega je vprašanje, ali navedeno sploh drži. Generativna umetna inteligenca pogosto zelo gladko piše, a lahko zgreši dejstva, datume, imena, naslove zakonov, citate ali zaporedje dogodkov. V praksi to pomeni, da pri članku, ki se bere preveč popolno in je poln samozavestnih trditev, izberemo dve ključni izjavi ali tri in jih preverimo v primarnih virih. Če piše, da je neka znana igra dobila posebno skrivno funkcijo ali da je posodobitev operacijskega sistema vpeljala neko spremembo, poiščemo uradno dokumentacijo ali zanesljiv medij, ki je to potrdil. Pogosto se zgodi, da je jedro zgodbe resnično, podrobnosti pa so napačne ali zamenjane, prav te pa so večkrat znak, da je besedilo nastalo z izdatno strojno pomočjo. Koristen trik je, da se za trenutek ustavimo pri čudnih podrobnostih. Če članek govori o lokalni temi, a vključi fraze, ki so značilne za drugo državo, ali uporablja regionalne izraze, ki ne sodijo v kontekst, je oboje lahko posledica tega, da je model mešal vzorce iz različnih okolij. Pri tem je pomembno vedeti, da samo preverjanje slovnice ni dovolj. Danes so generatorji besedila večinoma slovnično zelo dobro izurjeni, zato se ne bodo izdali s tipičnimi napakami, ki jih ima slab prevod. Uporabnejši je zato občutek za slog in strukturo. Človeški avtorji ponavadi razvijajo misel z osebnimi poudarki, drobnimi odstopanji, s konkretnimi primeri, s kakšno nepričakovano opazko ali z jasnim stališčem, ki ga podprejo, umetna inteligenca pa pogosto drsi v varno, splošno govorico. Če beremo odstavek, ki je pravilno sestavljen, a zveni kot povzetek povzetka, kjer so vsi stavki podobno dolgi, vsi uvodi podobni in se fraze pogosto ponavljajo, se izplača dvigniti obrv.

Oblika in položaj rok najpogosteje razkrijeta vpletenost umetne inteligence pri nastanku slikovnega gradiva.
Ko pridemo do slik, postane zgodba še zanimivejša. Ker smo ljudje zelo vizualno zaupljivi, ima fotografija v naših glavah še vedno status dokaza. Dobro je zato imeti rutino, ki jo uporabimo, kadar naletimo na sliko, ki bi lahko bila spremenjena ali generirana. Najprej začnemo z očitnim: povečamo sliko in preverimo, ali so v njej deli, ki so nenavadno mehki, zamegljeni ali stopljeni. Generativni modeli so odlični pri ustvarjanju celote, medtem ko se jim pri podrobnostih pogosto zatakne. Ena od klasičnih pasti so roke. Čeprav je stanje boljše kot pred leti, imajo generatorji še vedno težave s prsti, sklepi in z držo dlani, predvsem v kompleksnejših pozah, ko roka drži predmet ali je delno zakrita. Če je na sliki več ljudi, preverimo še ujemanje perspektive: ali so stopnice ravne, ali se ograje pravilno nadaljujejo, ali so sence skladne z enim virom svetlobe. Umetna inteligenca zna ustvariti prepričljivo svetlobo, a se včasih zmede pri tem, od kod bi ta v resnici prihajala.
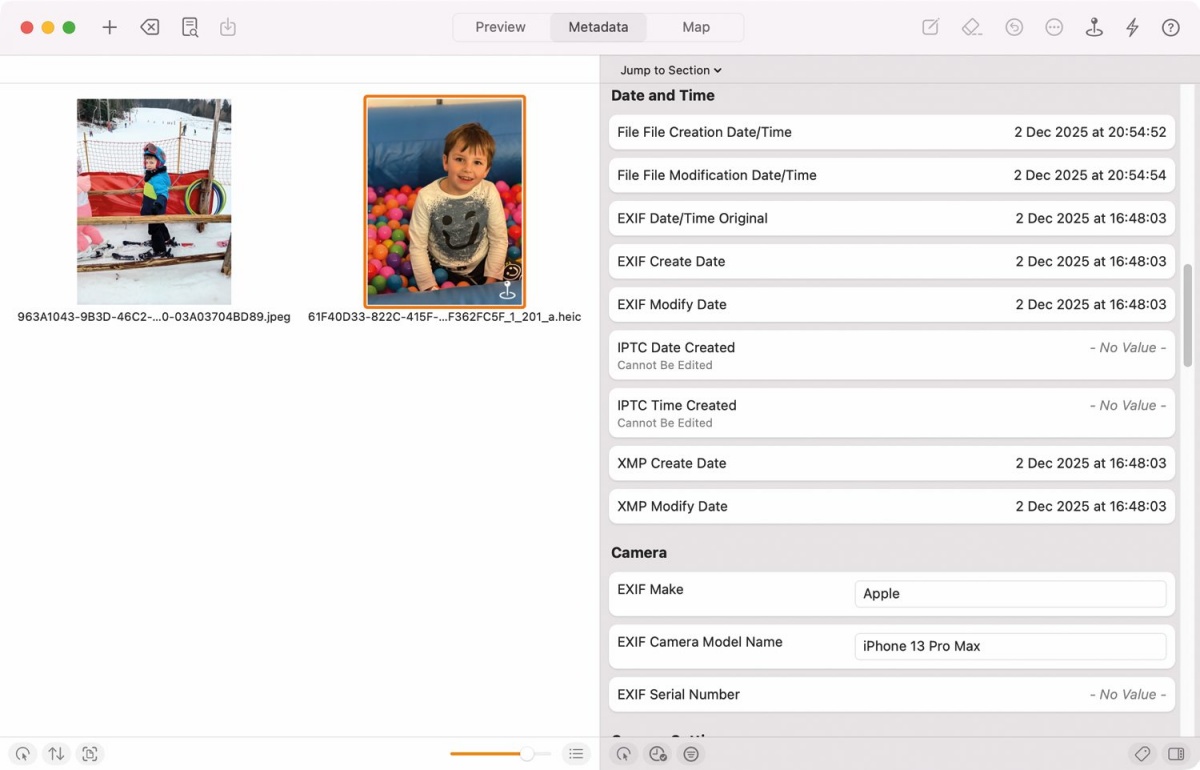
Prikaz (in urejanje) metapodatkov nam omogočijo namenska programska orodja, kakršna je aplikacija MetaImage.
Zelo praktičen korak je pregled metapodatkov. Veliko fotografij vsebuje podatke EXIF, ki lahko razkrijejo, s katero kamero je bila slika posneta, kdaj, s kakšnimi nastavitvami in včasih celo lokacijo. Pri generiranih slikah so ti podatki pogosto prazni, nenavadni ali pa kažejo na programsko orodje, ne na kamero. Obstajajo pripomočki, ki ti te podatke preberejo, in če delamo bolj sistematično, lahko uporabimo tudi naprednejša orodja, ki pokažejo celotno strukturo metapodatkov. A tu velja pomembno opozorilo: metapodatke je mogoče izbrisati ali ponarediti, zato njihova odsotnost ne pomeni, da je slika umetna, prisotnost pa ne, da je resnična. Metapodatki so namig, ne sodnik. Odkrivanje prisotnosti umetne inteligence nam olajša tudi umetna inteligenca sama. Google je v Gemini dodal funkcijo, ki omogoča preprosto preverjanje, ali je bila slika ustvarjena ali urejena z njihovo umetno inteligenco. Google pri tem stavi na tehnologijo SynthID, digitalno oznako, ki je človeškemu očesu nevidna, a omogoča programsko zaznavo izvora vsebine. Od leta 2023, ko je bila tehnologija predstavljena, je bilo z njo opremljenih že več kot 20 milijard izdelkov, orodje za zaznavo pa so pred javno objavo temeljito preizkusili novinarji in medijski strokovnjaki.
Vpletenost Geminijeve Nano Banane pri nastanku sumljive slike nam razkrije Googlov vodni žig SynthID.
Postopek preverjanja je za uporabnika povsem preprost, saj je dovolj, da sliko naloži v aplikacijo Gemini in postavi vprašanje o njenem izvoru. Gemini nato pregleda sliko, poišče morebitno oznako SynthID in v rezultatu odgovori s potrebnim kontekstom o vsebini. Google namerava to storitev v prihodnje razširiti tudi na druge formate, kot sta video in avdio, ter funkcijo vključiti v druge storitve, vključno z Googlovim iskalnikom. Poleg lastne tehnologije Google sodeluje tudi z mednarodnimi partnerji v okviru koalicije C2PA, s čimer želi postaviti standarde za ugotavljanje pristnosti vsebin v celotnem tehnološkem ekosistemu, vključno s platformama Youtube in Google Photos. Kot del teh prizadevanj so slike, ustvarjene z najnovejšimi Googlovimi modeli, zdaj opremljene tudi s posebnimi metapodatki, ki zagotavljajo dodatno sledljivost. Cilj teh prizadevanj je uporabnikom omogočiti, da bomo v prihodnosti izvor vsebine lahko preverjali ne glede na to, kateri model ali izdelek jo je ustvaril, kar je ključno za odgovoren razvoj in uporabo umetne inteligence.
Še en izjemno uporaben in hiter trik je obratno iskanje slik. Izvedemo ga s preprostim nalaganjem vprašljive slikovne vsebine v iskalnik, kjer med rezultati preverimo, ali se je ista fotografija že prej pojavila v drugem kontekstu. To pogosto razkrije, da je nekdo recikliral staro fotografijo in ji dodal nov opis ali pa da je bila slika vzeta iz spletnega skladišča fotografij. Pri umetnointeligenčnih izdelkih je rezultat iskanja včasih celo prazen, kar je koristen signal, zlasti če slika trdi, da prikazuje večji dogodek in bi morala obstajati v več medijih. Tudi pri odkrivanju slik, popravljenih ali ustvarjenih z umetno inteligenco, obstajajo namenska orodja, ki delujejo podobno kot detektorji besedila: analizirajo vzorce v slikovnih pikah, nenavadne konfiguracije, statistične lastnosti slike in značilnosti, ki so tipične za umetnointeligenčne modele. V praksi jih je dobro uporabljati kot potrditev, ne kot edini kriterij. Zanimivo je tudi, da nekateri poskušajo razliko med realnimi in umetnointeligenčnimi slikami ujeti s konceptom entropije, tj. z merjenjem, kako nepredvidljiva ali kaotična je slika na ravni slikovnih pik. Ideja je, da so umetnointeligenčne slike lahko nenavadno gladke ali imajo drugačno porazdelitev šuma. Ker sodobni modeli lahko ustvarijo tudi zelo bogate slike, je ta metoda ni zanesljiva in jo je treba jemati bolj kot raziskovalno zanimivost.
Ko pridemo do videa, postane tveganje prevare, ko gre za resničnosti posnetka, še večje. Video združuje sliko, gibanje in zvok, zato se lažni (angl. deepfake) videoposnetki pogosto uporabljajo za ustvarjanje vtisa, da je nekdo rekel ali naredil nekaj, česar ni. Pri tem je koristno vedeti, da se številne napake pokažejo na prehodih: rob obraza, prehod med vratom in brado, robovi las, ujemanje barve kože z vratom ali sence pod nosom in brado, ki se ne ujemajo z osvetlitvijo okolice. Zelo praktičen test je sinhronizacija ustnic. Pri dobrih ponaredkih je to lahko zelo prepričljivo, a vseeno se včasih opazi, da se govor ne ujema popolnoma z obliko ust. Posebej pri hitrem govoru ali zapletenih soglasnikih se lahko usta zamaknejo. Opazujemo tudi mežikanje, drobne premike oči in mimiko. Za ljudi so značilni naravni mikro gibi, ki jih je težko popolnoma posnemati, zato lahko obraz na ponaredku deluje nekoliko preveč gladko ali pa se čustva na obrazu ne ujemajo z intonacijo in vsebino govora.

Taylor Swift je oseba, ki je prikazana na največ lažnih posnetkih na svetu.
Zvok je pogosto še bolj razkrivajoč kot slika. Glasovi, ustvarjeni z umetno inteligenco, so danes lahko zelo prepričljivi, vendar jih še vedno pogosto izdajo intonacija, poudarki, dihanje in čustvenost. Če poslušamo govor, ki naj bi bil jezen, žalosten ali navdušen, a zveni enakomerno, skoraj brez dinamike, je to sumljivo. Podobno so lahko znaki tudi nenavadna izgovorjava posameznih besed ali čudni presledki med stavki, kot da je glas sestavljen iz različnih delov. Pri petju se to pogosto pokaže tako, da je izgovor preveč čist, brez naravnega šuma ali pa se črke čudno lomijo v prehodih med toni. Pri viralnih posnetkih je koristno preveriti tudi kontekst objave. Če nekdo objavi posnetek znane osebe, pa ni nobenih drugih virov, nobenega drugega posnetka istega dogodka, nobene uradne potrditve, je potrebna previdnost. Pri resničnih dogodkih običajno obstaja več kamer, več zornih kotov, več prič, več objav in sčasoma tudi odzivi uradnih kanalov.
Pomembno je, da se pri odkrivanju prisotnosti umetne inteligence v najdenih vsebinah zavedamo, da popolne gotovosti včasih ni mogoče doseči. Generatorji napredujejo, detektorji pa so vedno korak za njimi. Najboljša obramba je psihološka: vsebin ne delimo takoj, ne odzovemo se na prvi impulz in jih ne širimo, dokler nimamo vsaj nekaj neodvisnih potrditev. To še posebej velja za vsebine, ki merijo na čustva, saj se nanje umetna inteligenca in manipulatorji največkrat zanašajo. Če nas neki posnetek v trenutku razjezi ali prestraši, je to idealen trenutek, da se ustavimo, saj njegovi snovalci računajo na to, da se bomo odzvali hitro. Skratka, prepoznavanje vsebin, ustvarjenih z umetno inteligenco, ni čarovnija, ampak kombinacija opazovanja, preverjanja in zdrave skeptičnosti. V svetu, kjer je ustvarjanje ponaredkov vedno cenejše in hitrejše, nam prav ta pristop prihrani živce in prepreči, da bi bili nevede del verige širjenja laži.