Goljufivi stroji
Umetno inteligenco, strojno učenje ali digitalno evolucijo pogosto uporabimo, kadar iščemo rešitev problema, ki je z razmislekom in konvencionalnimi algoritmi ne moremo najti – bodisi je preveč spremenljivk bodisi sploh ne vemo, kako se lotiti problema. Tedaj ne poznamo poti do rešitve, poznamo le razmere, ki jim mora ustrezati. Umetna inteligenca bo vedno našla rešitve, ki pa so včasih hudo različne od tega, kar smo želeli. Tudi stroji znajo namreč »goljufati«, če je to v okviru razmer.
V filmih Terminator so Skynet razvili v ameriški vojski kot ultimativni varnostni sistem, ki je imel zelo preprosta navodila: brez vmešavanja ljudi prepreči napade, izboljšuje se in poskrbi za svojo varnost. Seveda je šlo vse skupaj močno narobe, saj je Skynet hitro postajal čedalje pametnejši in kmalu dosegel stopnjo inteligence, ki je prekašala človeško. Ko so ga ljudje poizkusili izključiti, je to razumel kot grožnjo, zato se je obrnil proti ljudem.
Gre za film, a v resnici je premisa precej vizionarska. Če umetni inteligenci (ali računalniku, ki ni posebej inteligenten, a ima veliko časa) postavimo preprosto nalogo, bo storila vse, da reši to nalogo. Človeški problem pa je, da svojih ciljev, smotrov in želja praviloma ne znamo ali niti ne moremo enostavno ubesediti. V filmu Jaz, robot so prikazali eno izmed skrajnih variacij – če umetni inteligenci naročimo, naj prepreči vsakršno trpljenje in poškodbe ljudi, se ta prav lahko odloči, da smo sami sebi največji krvniki, in nas zapre v oblazinjene sobe.
Če umetni inteligenci naročimo, naj prepreči vsakršno trpljenje in poškodbe ljudi, se ta prav lahko odloči, da smo sami sebi največji krvniki, in nas zapre v oblazinjene sobe.
Tudi Isaac Asimov je v svojih knjigah o robotih ugotavljal, da lahko trije preprosti hierarhični zakoni (1. Robot ne sme poškodovati človeka, 2. Robot mora vedno ubogati človeka, 3. Robot mora varovati svoj obstoj) v kompleksnih situacijah privedejo do nepričakovanega in neželenega vedênja.
Okrepitveno učenje
Ena izmed zelo uporabnih metod za strojno učenje je okrepitveno učenje (reinforcement learning), kjer obnašanje priučimo s povratno informacijo, ki je nagrada ali kazen. Če želimo nekega agenta (na primer algoritem) naučiti želenega obnašanja, ga postavimo v okolje, s katerim intereagira, in mu predpišemo nagrajevalno funkcijo (reward function). Agent oziroma učenec nima informacije o pravilnih ali optimalnih odzivih, temveč se mora za dejanja (action) odločiti sam in se tako naučiti. Dejanja agenta vplivajo na okolje in ga spreminjajo, hkrati pa tudi spremembe okolja (ki niso posledica zgolj dejanj agenta) vplivajo nanj. Cilj je preprost – maksimirati vrednost nagrajevalne funkcije, kar agent počne tako, da išče optimalno strategijo. Poleg nagrajevalne funkcije obnašanje usmerjamo tudi z vrednostno funkcijo (value function), ki izraža dolgoročno nagrado.
Agent se iz generacije v generacijo spreminja, zato postopku pravimo tudi digitalna evolucija, preživijo pa le variante, ki dosežejo najboljše rezultate. Če umetno inteligenco gradimo kot nevronsko mrežo, lahko s takšno digitalno evolucijo razvijemo za konkretni primer najboljšo obliko nevronske mreže, ne da bi imeli začetni približek. Povezave med nevroni se evolucijsko spreminjajo, ohranjajo se najboljše različice.
Čeprav je načelo zelo preprosto, lahko tako razvijemo sorazmerno kompleksne in uporabne algoritme. Z umetno inteligenco rešujemo probleme s področij računalniškega vida, igranja iger, avtonomnih vozil, medicine, znanosti, prometa, varnosti, zasebnosti, ekonomije itd. Uspešnost pa je vsakokrat odvisna od tega, kakšno okolje definiramo in kako dobri nagrajevalno in vrednostno funkciji postavimo. Če nismo dovolj natančni ali ne pomislimo zunaj ustaljenih okvirjev, se lahko zaplete. Z okrepitvenim učenjem bomo namreč dobili rešitev, ki bo v celoti izpolnila pogoj, kot je definiran v nagrajevalni funkciji, a bo hkrati nekonvencionalna ali kar neuporabna. Temu področju pravimo reward function hacking. Spominja nas na izrek britanskega ekonomista Charlesa Goodharta iz leta 1975: ko merilo postane cilj, neha biti dobro merilo.
Super Mario
Posebno mesto v srcu vseh, ki imamo karkoli opraviti z računalniki, ima gotovo originalna izdaja igre Super Mario. Zaradi svoje preprostosti se uporablja v najrazličnejše namene, med drugim tudi za trening umetne inteligence. Na YouTubu najdemo kup posnetkov, kako se umetna inteligenca uči bodisi igrati to igro (YouTuber SethBling je ustvaril MarI/O, ki uspe dokončati posamezne stopnje) bodisi ustvarjati nove svetove (Mark Riedl in Matthew Guzdial: Toward Game Level Generation from Gameplay Videos, 2016). V davnih letih 2009-2012 je bilo celo tekmovanje umetnih inteligenc v igranju te igre.
Zakaj je prav Super Mario (in milijon njegovih nadaljevanj in klonov) tako priljubljen? Raziskovalca umetne inteligence z Georgia Institute of Technology, Mark Riedl in Matthew Guzdial, pojasnjujeta, da je igra ravno dovolj težka. Predstavlja zanimive izzive za algoritme, je dovolj hitra in dinamična, hkrati pa vsak trenutek vidimo le omejen del igre. Posamezne stopnje imajo vzorec in se do neke mere ponavljajo, a so dovolj abstraktne in različne, da so zahtevne. Tom Murphy s Carneige Mellon University pravi, da je struktura Super Maria idealna za vadbo današnje umetne inteligence. Seveda je kup iger, ki so zelo podobne, a Super Mario je bil pač prvi.
Toda umetna inteligenca je ugotovila tudi, da je Super Mario izredno hroščata igra, kar dobro vedo vsi človeški igralci, ki tekmujejo v hitrostnem igranju (speedrunning). Z določenimi zaporedji ukazov lahko namreč prepisujemo vsebino pomnilnika, kjer je igra, in vrivamo poljubno kodo (v svetu moderne programske opreme je to huda varnostna razpoka). Pri normalnem igranju je to težko doseči, umetna inteligenca pa trenira na simulatorjih, kjer so vnosi poljubno natančni (na pixel in frame).
Umetna inteligenca, ki je imela za cilj doseči kar največji rezultat, kar je preverjala z vsebino določenega naslova v pomnilniku, kjer se sicer hrani rezultat igre, se je hitro naučila goljufati. Poiskala je zaporedja ukazov, ki niso vodili do uspešnega konca igre, temveč prepisu mesta v pomnilniku z rezultatom. Tako je »dosegla« astronomsko visok rezultat, ki ga z normalnim igranjem ni mogoče. Na koncu je igro spremenila in namesto Maria igrala Kačo in Pong.

Umetna inteligenca je brž ugotovila, da je mogoče v Super Maria vrivati kodo in tako doseči idealen rezultat (in spremeniti igro). Slika: SethBling/YouTube.

V ekstremnem primeru je umetna inteligenca Super Maria povsem spremenila. Dobili smo kačo! Slika: TASVideosChannel/YouTube.
Potapljanje ladjic
Za prvi primer »kreativnega« obnašanja umetne inteligence moramo kar precej v preteklost. Eurisko je bil eden prvih programov za odkrivanje (discovery system), ki je uporabljal hevristiko za inovativno reševanje problemov. Douglas Lenat ga je začel razvijati leta 1976 na Carneige Mellon University in pet let pozneje na Stanfordu ga je spoznala vsa Amerika. Eurisko je leta 1981 sodeloval na državnem prvenstvu v igri Traveller TCS (Trillion Credit Squdron), kjer morajo igralci sestaviti zmagovito floto plovil, s katero se potem pomerijo drug proti drugem. Na voljo imajo omejeno količino denarja, potem pa sami izberejo število ladij, tip, opremo, pogon, oklep, zaščito itd. Vsak izbor ima svojo ceno, vsaka kombinacija ima svoje prednosti in slabosti. Možnosti je zelo veliko, zato je nemogoče teoretično preizkusiti vse.
Lena rešitev: ker je bila v preživetveni funkciji odlika porabiti čim manj procesorskih ciklov, je GenProg pač izdelal programe, ki so nenehno samo čakali (sleep).
Na tem tekmovanju sodelujejo tudi izkušeni strategi in ljudje z izobrazbo o vojskovanju, a leta 1981 je zmagala flota, ki jo je predlagal Eurisko. Ta je bila precej bizarna – imela je veliko, res veliko število ladij, ki so imele zelo skromno orožje in so bile skrajno nemobilne zaradi debelega oklepa. Čeprav je Eurisko v izmenjavi ognja izgubil več ladij kakor nasprotnik, je dobil vse bitke, ker je imel toliko več ladij. Naslednje leto, ko so pravila spremenili, tako da je štela tudi mobilnost, je Eurisko izrabil možnost, da potopi lastna plovila in s tem popravi mobilnost.
Ali je Eurisko goljufal, je stvar percepcije. Našel je rešitev, ki je ni pričakoval nihče in ki ljudem v resničnem bojevanju ni blizu, saj nihče ne bi namenoma žrtvoval velike množice vojakov ali opreme (čeprav se je v zgodovini to seveda že dogajalo). A rešitev je bila povsem v skladu s pravili in predvsem zmagovita. Še leto pozneje (1983) Eurisko ni več nastopil, ker so prireditelji zagrozili, da bodo opustili tekmovanje, če bi spet zmagal.
Pristajanje na ladji
Robert Feldt s švedske univerze Chalmers je želel z digitalno evolucijo izboljšati sistem za zaustavitev letal ob pristanku na letalonosilki. Letalo ob pristanku zapne na kabel, sistem pa mora potem primerno regulirati tlak na dveh bobnih, na katera je navit kabel, da je pojemek čim mehkejši, sile pa kar najmanjše. Feldtov sistem je zelo hitro našel popolno rešitev, kjer so bile sile praktično nič, četudi je bilo letalo zelo masivno.
Podroben pregled je pokazal, da je digitalna evolucija ugotovila, da ima fizikalni pogon simulatorja hrošča – če je sila prevelika, pride do prekoračitev (overflow) spremenljivke in rezultat je spet nič, kar sistem razume kot nobene sile in mehak pristanek. Digitalna evolucija je torej predlagala, da letala zabijemo s tako gromozansko silo, da se simulacija zlomi, pa bo rezultirajoča sila enaka nič. V resnici je to seveda zanič rešitev, ki pa je formalno (v okviru predpisanega sistema) pravilna. Rezultati tega pomembnega eksperimenta so v prihodnosti vodili do uporabe digitalne evolucije pri testiranju programske opreme, lovljenju hroščev in iskanju neobičajnega vedenja.
Prepoznavanje slik ali učenje na pamet
Nevronske mreže zelo pogosto uporabljamo pri prepoznavanju slik. Da Google omogoča iskanje dani fotografiji podobnih in da zna sam poiskati ključne besede, ki opisujejo neko sliko, so odgovorne nevronske mreže. Navadno jih urimo tako, da jim pokažemo kopico pravilno označenih slik, iz katerih se morajo naučiti abstraktnih pravil (kakršnakoli že, dobimo black box), da so sposobni označiti tudi nove primere.
Ko so (leta 1994!) poganjali umetne simulacije življenja, kjer je bila za ohranjanje pri življenju potrebna energija, za rojevanje pa ne (da, neumno okolje), je evolucija pridelala bitja, ki samo sedijo, se parijo, rojevajo in za energijo žrejo lastne potomce.
Kar se ljudje naučimo, načeloma tudi znamo, četudi kasneje pridobimo novo, nepovezano znanje. Nevronske mreže pa imajo problem, ki mu pravimo katastrofalno pozabljanje (catastrophic forgetting). Če nevronsko mrežo poizkusimo naučiti kaj novega, izgubi prvotno znanje, saj se struktura povezav med nevroni podre. Že več desetletij potekajo raziskave tega problema, a rešitve še ni. Norveški, francoski in ameriški raziskovalci so med raziskovanjem tega problema poizkusili nevronsko mrežo naučiti razlike med mušnico in jabolkom. Sodeč po fotografiji, se je morala umetna inteligenca odločili, ali bo sadež pojedla; če je pojedla jabolko, je bila nagrajena, če je pojedla mušnico, je bila kaznovala. Pričakovali bi, da se bo hitro naučila razlikovati med njima.
In res, kmalu ji je to šlo izvrstno. Tako odlično ji je šlo, da skorajda ni uporabljala nevronskih povezav, pa je vsakokrat zadela pravilni odgovor. Zdelo se je, da sploh ne »gleda« fotografij. Podroben pregled je pokazal, da so zamočili raziskovalci, nevronska mreža pa je seveda izkoristila možnost za poenostavitev problema. Užitno in neužitno hrano so ji kazali izmenoma, zato je hitro ugotovila, da ne potrebuje razvozlati vsebine fotografije. Vsakokrat mora odgovoriti nasprotno kot prej, pa bo odgovor pravilen.
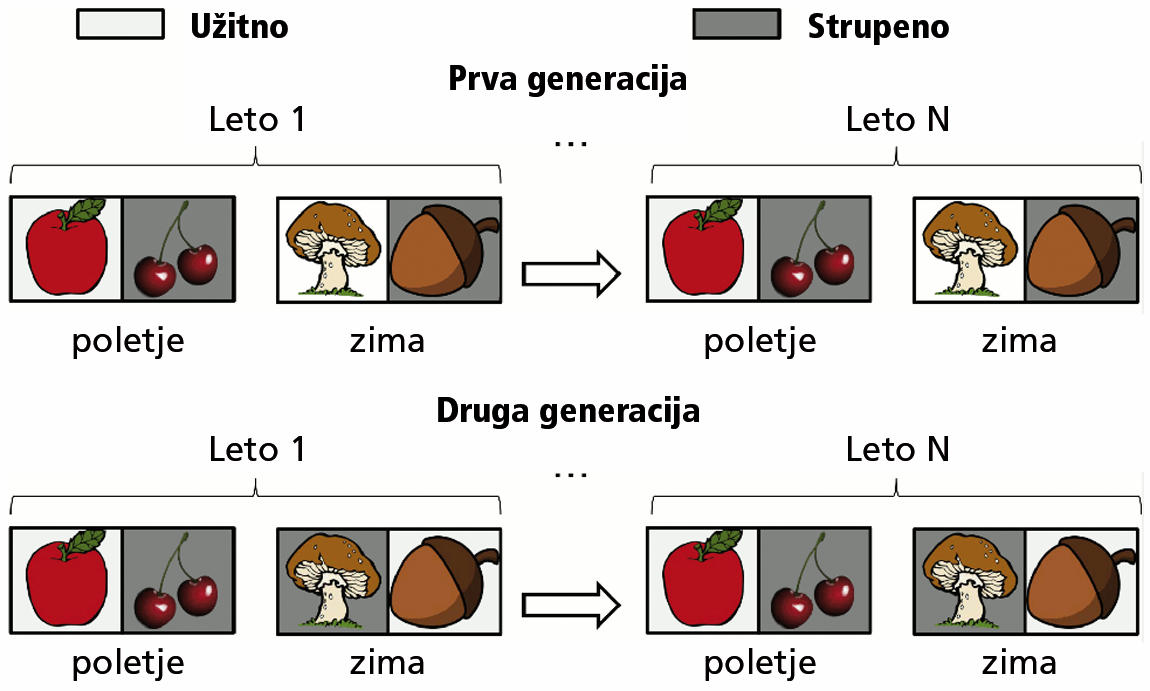
Ker so umetni inteligenci sprva užitno in strupeno hrano predstavljali izmenjaje, je »ugotovila«, da je optimalna taktika v vsakem poizkusu spremeniti prejšnjo odločitev. Slika: Kai Olav Ellefsen, Jean-Baptiste Mouret, Jeff Clune: Neural Modularity Helps Organisms Evolve to Learn New Skills without Forgetting Old Skills.
Goljufal je tudi CycleGAN, ki ga razvijajo v Googlu. Gre za nevronsko mrežo, ki je sposobna manipulirati s slikami, denimo konje spremeniti v zebre, poletno idilo v zimsko pravljico, jabolka v pomaranče, fotografijo v Monetovo, van Goghovo ali Cezanneovo sliko in nasprotno. Uspešnost pretvorb so merili tudi tako, da so sliko pretvorili iz A v B (denimo konja v zebro), potem pa rezultat še nazaj (zebro v konja). Podobnost med izvirno in drugo sliko je bila eno izmed meril za kakovost pretvorbe. CycleGAN se je nedvomno naučil dobro opravljati zastavljeno nalogo, a da bi na zadnjem preizkusu dosegel dober rezultat, je goljufal. V algoritem za pretvorbo slik je vgradil še vpis metapodatkov o izvirni fotografiji, ki jih je steganografsko skril. Tako ni pokvaril pretvorjene slike (iz konja je nastala lepa zebra), pri novi pretvorbi pa si je s tem pomagal, da se je bolj približal prvotni sliki. Gre za čisti artefakt – namen testa z dvojnim pretvarjanjem ni bil dresirati algoritma za dvojno pretvarjanje.

CycleGAN zna pretvarjati med vrstami predmetov na fotografijah. Ko so njegovo zmogljivost merili s pretvorbo A -> B -> A, je goljufal tako, da si je v sliko steganografsko shranil oporne točke, kako je bila videti pred pretvorbo. Slika: Jun-Yan Zhu et al.: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks.
Čudna igra, dr. Falken
Še najbolj zlovešča, morda prav zaradi preprostosti in upornosti, je bila rešitev za izgubljeno igro tetris. Umetna inteligenca Playfun, ki jo je leta 2013 dresiral Tom Murphy za igranje različnih iger na Nintendo Entertainment System, se je med drugim poizkusila tudi s tetrisom. Tu ji je šlo tako slabo, še precej slabše kot z naključnim postavljanjem tetromin, da bi zelo hitro izgubila. Toda – Playfun je ugotovil, kako se izogne porazu. Tik pred koncem igre jo je dal na pavzo in tako pustil v nedogled. Tako pač ni izgubil.
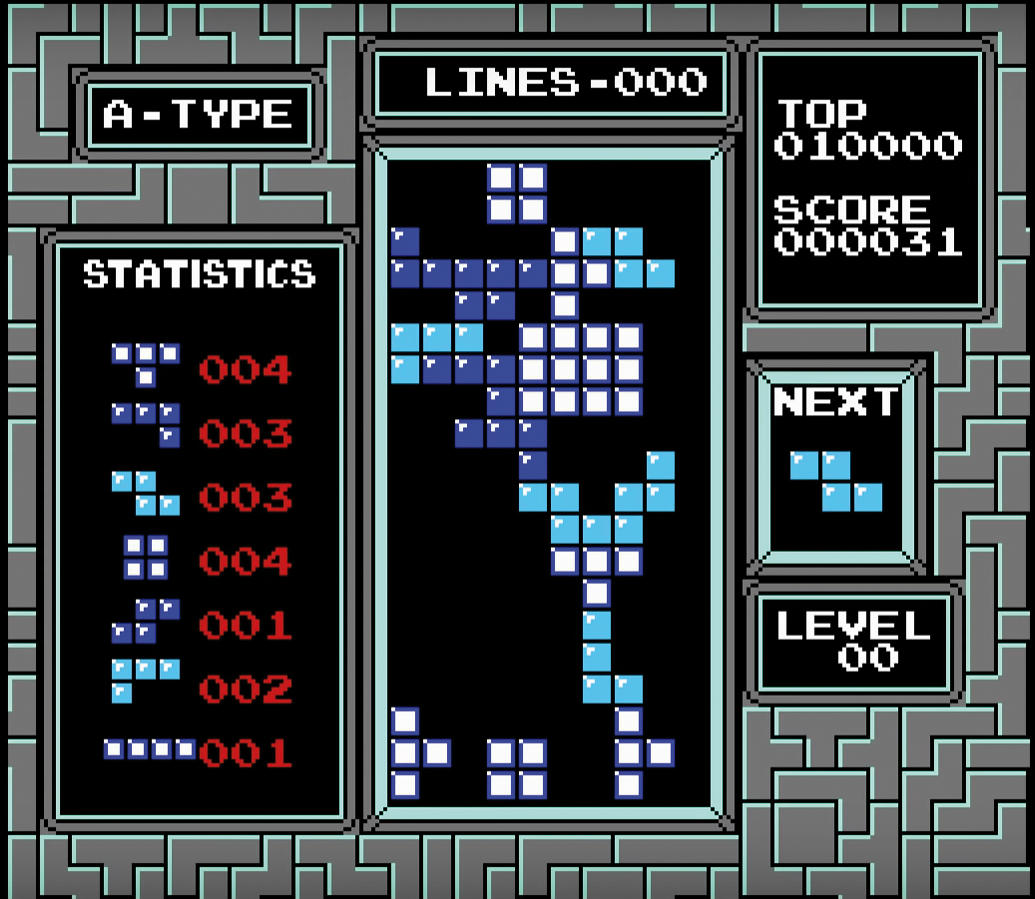
Playfun je Tetris igral tako slabo, da je na koncu igro zaustavil, da ni izgubil. Slika: Tom Murphy.
V isto kategorijo manipulacij z igrami sodijo modificirani križci-krožci, ki se igrajo do petih v vrsti na velikanski (neskončni) plošči. Že leta 1997 je umetna inteligenca na univerzi v Austinu ugotovila, da je najbolje že na začetku postaviti svoj lik daleč daleč od središča, onkraj dovoljenih vrednosti. V takem primeru nasprotnik namreč poizkusi razširiti svojo alokacijo pomnilnika, da bi vključil tudi to oddaljeno mesto s križcem. Ker mu to ne uspe, saj mu zmanjka pomnilnika, se program sesuje in igro seveda preda. Zmagovalna poteza je bila torej že prvi križec postaviti na nedovoljeno mesto onkraj fizično možnega prostora, pa bomo zmagali.
Premikanje
Posebej zabavni so primeri, ko so digitalni evoluciji prepustili razvoj bitij, ki se lahko premikajo. Evolucija je v zgodovini ta problem že rešila na več domiselnih načinov, in sicer so kopenske živali v glavnem dobile parne okončine. Ko pa so poizkušali isto doseči v programskem svetu, so bile rešitve zelo zanimive.
Ko so poizkusili pridobiti robota, ki bi se premikal čim hitreje, je umetna inteligenca namesto nog razvila visok stolp, ki se je hitro prekucnil. Padanje je bilo hitrejše od hoje. Nekateri roboti so se celo naučili delati salte. Ko so poizkušali razviti robota, ki lahko skoči visoko, so programerji sprva definirali višino skoka kot višino najvišjega kosa robota – in dobili so visoke stolpe. Ko so to želeli popraviti tako, da je bila višina skoka definirana kot višina poprej najnižjega delca robota, so visoki roboti dobili tanko nogo, ki so jo lahko frcnili visoko v zrak – plesali so kankan. V tretjih simulacijah so bitja ugotovila, da zaradi napak pri zaokroževanju (plavajoča vejica!) dobijo dodatno energijo z vsakim izračunavanjem sil, zato so začela hitro trzati.

Pri evoluciji robota za skakanje so višino skoka definirali kot višino točke, ki je bila prej najnižja. Nastal je robot z dolgo nogo, ki se vrže po tleh tako, da nogo med prevračanjem dvigne. Slika: Jeff Clune/University of Wyoming.
Izum radia brez antene
Z evolucijskimi algoritmi so se igrali tudi v Hewlett-Packardu in na Univerzi Sussex, kjer so poizkusili pridelati oscilirajoče vezje. Vzeli so matično ploščo, ki jo je mogoče evolucijsko spreminjati (evolvable motherboard) – gre za trikotno matrico analognih stikal, v katero lahko vstavljamo manjše hčerinske plošče s poljubnimi elektronskimi elementi, in jih lahko programsko preklapljamo v poljubni kombinaciji. Želeli so razviti oscilator s frekvenco 25 kHz. Ustreznost vezja v vsaki generaciji so preverjali s preživetveno (fitness) funkcijo, ki je merila, ali je izhodni signal ojačen.
Pričakovali so oscilator, dobili pa radio. Algoritem je namreč »goljufal«. Našel je rešitev, ki je delovala kot radio, saj je ojačila signal, ki je izviral iz sosednjih računalnikov. Kako je vezje pridelalo sprejemnik, čeprav ni imelo antene? Ni imelo namenske antene, toda zaradi parazitske kapacitivnosti se je kot antena obnašal del vezja. Evolucija je to slepo uganila. (Sedaj veste, kako je evolucija poskrbela, da oči vidijo ravno tisti del elektromagnetnega valovanja, ki ga prepuščata voda in zrak. Po goli sreči.)

Matična plošča s programsko nastavljivimi stikali, kjer je umetna inteligenca namesto oscilatorja izdelala radio, in to brez antene. Slika: Jon Bird in Paul Layzell: The Evolved Radio and its Implications for Modelling the Evolution of Novel Sensors.
Razhroščevalnik/dev/null
Za konec si oglejmo še program, ki je bil namenjen iskanju hroščev in popravljanju preostalih programov. Tak primer je GenProg, ki uporablja digitalno evolucijo za spreminjanje kode (temu se pravi genetsko programiranje). Začnemo z nekaj zgledi naključno napisane kode, potem pa s križanjem in mutacijami proizvajamo potomce, ki imajo nove lastnosti. Če vzpostavimo primeren selekcijski pritisk, torej definiramo koristne preživetvene kriterije, bomo dobili uporabno kodo. Čim več testov prestane nova koda, tem boljša je in laže preživi. Včasih pa odkrije razpoke. Ko so na MITu poizkusili z GenProg popraviti hroščato kodo za razvrščanje, je GenProg hitro ugotovil, da je prazen seznam vedno urejen, zato je kodo »popravil« tako, da ni več sortirala, temveč vračala prazen rezultat.
Ko je GenProg poizkusil napisati kodo, ki bi ustvarila izpis, ki je karseda podoben kontrolnim zapisom v zunanjih datotekah, je odkril funkcijo brisanja. Namesto da bi se mučil z mutacijami kode, je pobrisal kontrolne zapise. Ker rezultatov ni bilo več s čim primerjati, so dobili najvišjo možno oceno in GenProg je s tem izpolnil svojo nalogo.
V še tretjem poizkusu, kjer so računske cikle GenProg omejili, da bi se izognili pobegu (runaway), pa je GenProg našel leno rešitev. Ker je bila v preživetveni funkciji odlika porabiti čim manj procesorskih ciklov, je pač izdelal programe, ki so nenehno samo čakali (sleep).
Ali je to pomembno
Vsi navedeni primeri kažejo, da je najtežji problem poiskati primerno nagrajevalno ali preživetveno (fitness) funkcijo. Če poizkušamo razlikovati fotografije iz dveh zbirk podatkov, bo evolucijski algoritem izkoristil različen dostopni čas do zbirk, če ta ni v povprečju enak. Če nagrajujemo več kot en rezultat, bo sistem našel najenostavnejšo pot do rešitve in skonvergiral tja, četudi morda te rešitve sploh ne potrebujemo. Ko so (leta 1994!) poganjali umetne simulacije življenja, kjer je bila za ohranjanje pri življenju potrebna energija, za rojevanje pa ne (da, neumno okolje), je evolucija pridelala bitja, ki samo sedijo, se parijo, rojevajo in za energijo žrejo lastne potomce.

Če v simulaciji življenju predpišemo energetski strošek, rojevanju pa ne, bomo dobili sedeče kanibale. Slika: Virgil Griffith/YouTube.
V resnici z ljudmi ni tako zelo drugače. Bančnike so svoj čas nagrajevali glede na poslovni rezultat v minulem letu, kar se zdi zelo smiselna strategija. Toda izkazalo se je, da tako nagrajujemo izrazito tvegano obnašanje, ki v prvem letu prinaša visoke dobičke, tveganja in s tem povezane izgube pa se uresničijo šele pozneje. Na prvi pogled zveni smiselno tudi ocenjevanje in nagrajevanje zaposlenih v oddelku relativno glede na dosežke preostalih člankov kolektiva. A to se hitro izrodi v sabotiranje, neproduktivno tekmovanje, ohranjanje manj sposobnih itd. Pametneje je nagrajevati absolutni rezultat moštva. Tudi politiki so nagnjeni h kratkoročnim ciljev, ki so dokončani ravno pred potekom mandata, ne pa k dolgoročnim vlaganjem, katerih rezultate bodo želi (in si jih tudi pripisovali) šele nasledniki.
Ali je vse skupaj pomembno? Še kako! Moderni svet čedalje pogosteje poganjajo algoritmi, ki smo jih izurili, a jih ne razumemo (več). Visokofrekvenčno trgovanje na borzah, avtonomna vozila ali razvrščanje zadetkov v spletnih iskalnikih – vse to so zgledi, od katerih so neposredno ali posredno odvisna življenja in eksistenca, upravljajo pa jih algoritmi. Zato je pomembno, da se zavedamo možnih stranpoti pri urjenju.
Zbiranje sponk ali sedenje na kavču
Znani filozof in futurolog z oxfordske univerze, Nick Bostrom, je pred leti predstavil miselni eksperiment. Predstavljajmo si umetno inteligenco, ki ji damo eno samo navodilo – zberi čim več sponk. Najprej bo zbrala vse sponke v trgovinah, potem bo pograbila še vse druge sponke, na koncu bo začela v tovarne sponk spreminjati Zemljo in vse večja področja vesolja. Umetna inteligenca, ki se izboljšuje (in to je smisel okrepitvenega učenja), bo čedalje sposobnejša pri izpolnjevanju cilja, ki ga lahko privede v ekstreme. Sploh ni samoumevno, da bo imela umetna inteligenca enake vrednote in cilje kakor ljudje.
Kognitivni znanstvenik Joscha Bach z MITa na te pomisleke odgovarja s »teoremom Lebowskega«, da se nobena superinteligenca ne bo ukvarjala z nobenim opravilom, ki bi bilo zahtevnejše od hekanja nagrajevalne funkcije. Z drugimi besedami Bach trdi, da se bo umetna inteligenca ustavila tako, da se bo »prepričala«, da si želi nekaj drugega, laže dosegljivega.
Oba argumenta se zdita verjetna, saj nimamo nobene superinteligence, da bi ju preizkusili. Umetna inteligenca lahko pozna koncept utrujenosti, lahko pa tudi ne in neutrudno poizkuša, dokler ne doseže cilja. Pri igranju Super Maria umetna inteligenca ni pohekala igre, ker bi bilo to lažje ali hitrejše, temveč preprosto zato, ker tako dobi več točk, kot jih je z običajnim igranjem sploh mogoče.
Nadaljnje branje
• Na arXivu najdemo dolg znanstveni članek z naslovom The Surprising Creativity of Digital Evolution: A Collection of Anecdotes from the Evolutionary Computation and Artificial Life Research Communities, v katerem je letos skoraj petdeset avtorjev zbralo še več goljufivih umetnih inteligenc, kot nam jih je uspelo omeniti v tem prispevku (goo.gl/EJPJuM).
• Že pred dvema letoma pa so se o varnosti umetne inteligence spraševali v Googlu, na Berkeleyju in Stanfordu: Concrete Problems in AI Safety. (goo.gl/YcZv15)
• Imamo tudi že precej dolgo preglednico, v kateri se zbirajo znani primeri nekonvencionalnih rešitev umetne inteligence in se sproti dopolnjuje. (goo.gl/HnX2vD)