Jezikovne težave umetne inteligence
V zadnjem času je bil na področju umetne inteligence dosežen neverjeten napredek. A stroji bodo to, kar si obetamo od njih, zmogli le, če bodo razumeli jezik, in to bo najtežji korak doslej.
Približno na polovici zelo napete igre goja v prestolnici Južne Koreje, Seulu, med Leejem Sedolom, enim najboljših igralcev vseh časov, in Googlovim programom umetne inteligence AlphaGo, je stroj potegnil skrivnostno potezo, s katero si je pridobil nevarno prednost pred človeškim nasprotnikom.

V 37. potezi se je AlphaGo odločil, da bo črni kamen položil na presečišče, kar je bilo na prvi pogled trapasto. Zdelo se je tako rekoč odločeno, da bo s tem nasprotniku prepustil precejšen del igralnega polja – to je pogosta začetniška napaka v tej igri, katere bistvo je nadzorovati igralno polje. Dva televizijska komentatorja sta se spraševala, ali si potezo napačno razlagata ali pa gre za tehnično napako računalnika. A v nasprotju s starimi pravili te igre je 37. poteza programu AlphaGo omogočila, da je na sredini mreže vzpostavil zavidanja vredno izhodišče. Googlov program je tako rekoč zmagal s potezo, ki se je ne bi domislil noben človek.
Zmaga AlphaGo je še toliko bolj osupljiva, ker staro igro go mnogi razumejo kot preizkus intuitivne inteligence. Pravila so razmeroma preprosta. Igralca se izmenjavata pri polaganju črnih oziroma belih kamnov na presečišča vodoravnih in navpičnih črt na deski in skušata obkoliti nasprotnikove kamne ter jih s tem izločiti iz igre. Kljub preprostim pravilom pa je zelo težko dobro igrati.
Medtem ko igralci šaha lahko vnaprej predvidijo nekaj potez, pri goju to ni mogoče, ne da bi igra postala nepregledno zapletena, poleg tega ni klasičnih otvoritvenih potez. Prav tako ni preprostega načina, kako oceniti prednost, in celo dobri igralci včasih težko pojasnijo svojo potezo. Zato tudi ni mogoče napisati preprostih pravil, po katerih bi se ravnal vrhunski računalniški program.
Po spopadu z računalnikom je Sedol stopil pred množico novinarjev in fotografov ter se vljudno opravičil, ker je razočaral človeštvo.
AlphaGo tako ni dobil navodil, kako naj igra go. Namesto tega je program analiziral na sto tisoče odigranih partij in jih na milijone odigral proti samemu sebi. Med različnimi tehnikami umetne inteligence je uporabil vse bolj priljubljeno metodo, znano kot globoko učenje, ki vključuje matematične preračune na podlagi tega, če opišemo zelo na splošno, kako se prižigajo med seboj povezani sloji nevronov, ko skušajo možgani izluščiti smisel novega podatka. Program se je igre naučil sam, z urami in urami vaje, in postopoma izbrusil notranji občutek za strategijo. To, da je ravno zato lahko premagal enega najboljših igralcev goja na svetu, je pomemben mejnik za strojno in umetno inteligenco.
Nekaj ur po 37. potezi je AlphaGo dobil partijo in rezultat je bil dva proti nič v nizu petih iger. Po spopadu z računalnikom je Sedol stopil pred množico novinarjev in fotografov ter se vljudno opravičil, ker je razočaral človeštvo. »Brez besed sem,« je rekel in mežikal v strele bliskavic.
Presenetljivi uspeh AlphaGo ponazarja, kakšen napredek je bil v zadnjih letih po desetletjih razočaranj in korakov nazadovanja, t. i. zimi umetne inteligence, dosežen pri umetni inteligenci. Globoko učenje pomeni, da se stroji vse lažje sami naučijo opravljati zapletene naloge, za katere smo bili še pred nekaj leti prepričani, da je zanje nujna enkratna človeška inteligenca. Samovozeči avtomobili postajajo otipljiva možnost. V bližnji prihodnosti bodo sistemi na podlagi globokega učenja pomagali postavljati diagnoze in priporočati zdravljenje.
Kljub takemu osupljivemu napredku pa se ena od temeljnih človekovih zmožnosti še vedno izmika: to je jezik. Sistemi, kot sta Siri in Watson podjetja IBM, so sposobni slediti preprostim izgovorjenim ali natipkanim ukazom in odgovoriti na osnovna vprašanja, ne zmorejo pa se pogovarjati in v resnici ne razumejo besed, ki jih uporabljajo. Jezik je predpogoj, da bo umetna inteligenca prinesla dejansko preobrazbo.
Čeprav AlphaGo ne more govoriti, zajema tehnologijo, ki bi lahko pripomogla k boljšemu razumevanju jezika. V družbah, kot so Google, Facebook in Amazon, pa tudi v vodilnih akademskih laboratorijih za umetno inteligenco, znanstveniki skušajo končno streti ta očitno zelo trd oreh, in sicer z uporabo prav teh orodij umetne inteligence – z globokim učenjem vred – ki so zaslužna za uspešnost AlphaGo in vnovično oživitev umetne inteligence. Če bodo uspešni, bo to odločilno vplivalo na obseg in značaj tega, kar se napoveduje kot revolucija v umetni inteligenci. Odločalo bo tudi o tem, ali bomo imeli stroje, s katerimi se bomo zlahka sporazumevali – stroje, ki bodo postali intimen del našega vsakdanjega življenja – ali pa bodo sistemi umetne inteligence ostali skrivnostne črne skrinjice, čeprav bodo avtonomnejši. »Ni mogoče imeti človeku podobnega sistema umetne inteligence, katerega srčika ne bi bil jezik,« je prepričan Josh Tenenbaum, predavatelj kognitivne znanosti in računalništva z massachusetskega tehnološkega instituta (MIT). »To je ena najočitnejših stvari, zaradi katerih je človeška inteligenca nekaj posebnega.«

Človek proti stroju. Človek je izgubil.
Morda bodo prav tehnike, ki so programu AlphaGo omogočile zmagati v goju, končno omogočile računalniku, da bo obvladal jezik, ali pa se bo treba domisliti česa drugega. A brez razumevanja jezika bodo posledice umetne inteligence drugačne. Seveda bomo še vedno imeli neverjetno zmogljivo in inteligentno programsko opremo, kot je AlphaGo, a v našem odnosu z umetno inteligence bo morda veliko manj sodelovanja in bo morda daleč manj prijeten. »Pereče vprašanje od vsega začetka je, kaj če bomo dobili stroje, ki bodo šteli za inteligentne, ker bodo tako učinkoviti, ne bodo pa kot mi, ker ne bodo razumeli, kdo smo?« se sprašuje Terry Winograd, zaslužni profesor z univerze Stanford. »Predstavljajte si stroje, ki ne temeljijo na človeški inteligenci, temveč na množičnih podatkih, a kljub temu vladajo svetu.«
Šepetalci strojem
Nekaj mesecev po zmagi AlphaGo sem odpotoval v Silicijevo dolino, zibelko najnovejšega razcveta umetne inteligence. Želel sem obiskati raziskovalce, ki so dosegli neverjeten napredek pri njeni praktični rabi in ki zdaj skušajo strojem vdihniti boljše razumevanje jezika.
Začel sem z Winogradom, ki živi v predmestju na južnem robu kompleksa univerze Stanford v Palu Altu, nedaleč od sedežev Googla, Facebooka in Appla. S sivimi kodrastimi lasmi in bujnimi brki je videti pravi častitljivi akademik, njegovo navdušenje pa je nalezljivo.
Winograd je bil leta 1968 eden prvih, ki so želeli stroj naučiti pametno govoriti. Kot matematični genij, ki ga je zanimal tudi jezik, je v novi laboratorij za umetno inteligenco na massachusetskem tehnološkem institutu prišel v okviru doktorskega študija, nato pa se je odločil sestaviti program, ki bo lahko klepetal z ljudmi, in sicer prek besedilne ukazne vrstice, uporabil pa je vsakdanji jezik. Takrat se ta želja niti ni zdela čudna. Takrat so dosegli neverjeten napredek v umetni inteligenci in drugi v laboratoriju so sestavljali zapletene sisteme za računalniški vid in futuristične robotske roke. »Vladal je občutek neslutenih, neomejenih možnosti,« se spominja.
Težava tiči v tem da je za marsikaj, kar počne človek, nujna instinktivna inteligenca, te pa ni mogoče zajeti z nedvoumnimi pravili.
A vsi niso bili prepričani, da bo računalnik tako zlahka obvladal jezik. Kot so menili nekateri kritiki, z znanim jezikoslovcem in predavateljem na MIT Noamom Chomskim vred, bi strokovnjaki za umetno inteligenco le stežka dosegli, da bi računalniki razumeli jezik, saj je bilo takrat še zelo malo znanega o mehaniki jezika pri človeku. Winograd se spominja, da je nekoč študent Chomskega odšel z zabave, ko mu je povedal, da dela v laboratoriju za umetno inteligenco.
Vendar so bili tudi razlogi za optimizem. Joseph Weizenbaum, v Nemčiji rojeni predavatelj na MIT, je nekaj let prej sestavil čisto prvi program za klepet, imenovan Eliza. Deloval je kot nekakšen psihoterapevt v komediji, ponavljal ključne dele izjave ali postavljal vprašanja, da bi spodbudil nadaljnji pogovor. Če bi programu povedali, da ste jezni na mamo, na primer, bi odgovoril: »Na kaj še pomislite ob misli na mamo?« To je bila prozorna zvijača, a je presenetljivo dobro delovala. Weizenbaum je bil pretresen, ko so nekateri testiranci stroju zaupali svoje najtemnejše skrivnosti.
Winograd je želel ustvariti nekaj, kar bi res razumelo jezik. Začel je tako, da je omejil razsežnosti problematike. Ustvaril je preprosto virtualno okolje, svet iz peščice namišljenih oseb, ki so sedele za namišljeno mizo. Nato je spisal program, ki ga je poimenoval SHRDLU, in ta je bil sposoben opredeliti vse samostalnike in glagole in je poznal preprosta slovnična pravila, da se je lahko pogovarjal o tem preprostem virtualnem svetu. SHRDLU (beseda ne pomeni nič, sestavljena pa je iz drugega stolpca tipk na linotipu) je znal opisati predmete, odgovoriti na vprašanja o njihovih medsebojnih relacijah in spreminjati ta svet v skladu z natipkanimi ukazi. Imel je tudi nekakšen spomin: če ste mu ukazali, naj prestavi rdeči stožec, nato pa omenili samo tisti stožec, je predvideval, da imate v mislih rdečega, ne pa kakšnega druge barve.
SHRDLU so navajali kot zgled, da se na področju umetne inteligence dosega velik napredek. A to je bila le iluzija. Ko je hotel Winograd programu povečati njegov preprosti svet, so pravila za upoštevanje nujno potrebnih besed in slovnične zapletenosti postala nepregledna. Le nekaj let pozneje je obupal in postopoma povsem opustil umetno inteligenco. Raje se je osredotočil na druga raziskovalna področja. »Omejitve so bile veliko večje, kot se mi je takrat zdelo,« je priznal.
Winograd je prišel do sklepa, da bi bilo s takratnimi orodji stroju nemogoče vcepiti resnično razumevanje jezika. Težava tiči v tem, kot je Hubert Dreyfus, predavatelj filozofije z Berkeleyja poudaril v knjigi z naslovom What Computers Can’t Do (Česa računalniki ne zmorejo) iz leta 1972, da je za marsikaj, kar počne človek, nujna instinktivna inteligenca, te pa ni mogoče zajeti z nedvoumnimi pravili. Prav zato so bili pred igro goja med Sedolom in programom AlphaGo številni strokovnjaki skeptični, da bi stroj res zmogel obvladati to igro.
A celo v času Dreyfusove knjige je nekaj raziskovalcev razvijalo pristop, s katerim bi bili stroji nekoč zmožni tudi takšne inteligence. Navdihnila jih je nevrologija in začeli so eksperimentirati z umetnimi nevronskimi mrežami – sloji matematično simuliranih nevronov, ki jih je bilo mogoče naučiti, da so se prižgali v odziv na določene podatke. Na začetku so bili ti sistemi nevzdržno počasni in pristop so označili za nepraktičen, kar zadeva logiko in utemeljevanje. Ključno je bilo vseeno, da so se nevronske mreže lahko učile stvari, ki jih ni bilo mogoče ročno kodirati, kar se je pozneje pokazalo kot uporabno pri preprostih nalogah, kot je bilo prepoznavanje na roko napisanih črk (to zmožnost so v 90. letih začeli tržiti za branje števk na čekih). Zagovorniki so trdili, da bi te nevronske mreže nekoč strojem lahko omogočile početi še veliko, veliko več. Nekega dne bi tehnologija tako razumela tudi jezik.
V preteklih letih so nevronske mreže postajale občutno bolj zapletene in zmogljivejše. Koristile so jim ključne matematične izboljšave, še pomembnejši dejavnik pa so bili hitrejši računalniki in obilica podatkov. Leta 2009 so raziskovalci z univerze v Torontu pokazali, da bi večslojna mreža za globoko učenje govor lahko prepoznavala z natančnostjo snemanja. Tri leta pozneje je ista skupina zmagala na razpisu za računalniški vid, za katerega je uporabila algoritem globokega učenja, ki je bil presenetljivo natančen.
Nevronske mreže za globoko učenje predmete na podobah prepoznavajo s preprosto zvijačo. Sloj simuliranih nevronov prejema podatke v obliki podobe, in nekateri teh nevronov se bodo prižgali glede na intenzivnost posameznih točk. Signal, ki tako nastane, potuje skozi še več slojev med seboj povezanih nevronov, dokler ne doseže izhodnega sloja, ki sporoči, da je bil predmet opažen. Z matematično tehniko, imenovano vzvratno razširjanje, prilagajajo občutljivost nevronov v mreži, da pride do pravega odziva. Prav ta korak sistemu omogoča zmožnost učenja. Različni sloji v mreži se odzivajo na lastnosti, kot so ostrina, barve in tekstura. Takšni sistemi danes prepoznajo predmete, živali in obraze tako natančno kot ljudje.
Pri uporabi globokega učenja za jezik se odpira logično vprašanje. Besede so namreč arbitrarni simboli in kot takšne se temeljno razlikujejo od podobe. Besedi imata lahko podoben pomen, čeprav sta sestavljeni iz povsem različnih črk, na primer, in ena beseda lahko v različnem sobesedilu pomeni različno.
V 80. letih so se raziskovalci bistro domislili, kako bi jezik spremenili v vrsto težave, s katero bi se bile nevronske mreže sposobne spopasti. Pokazali so, da je besede mogoče prikazati kot matematične vektorje, s čimer je mogoče preračunati podobnosti med sorodnimi besedami. Na primer besedi ladja in voda sta v vektorskem prostoru blizu, čeprav se zdita zelo drugačni. Raziskovalci z univerze v Montrealu pod vodstvom Yoshua Bengia in skupina pri Googlu so na podlagi te zamisli sestavili mreže, v katerih se lahko vsako besedo v stavku uporabi za izdelavo bolj zapletenega prikaza – nekaj, kar je Geoffrey Hinton, predavatelj z univerze v Torontu in znani raziskovalec s področja globokega učenja, ki sodeluje tudi z Googlom, poimenoval miselni vektor.
Z dvema takima mrežama je mogoče zelo natančno prevajati iz enega jezika v drugega. Če to mrežo povežemo s takšno za prepoznavanje predmetov in podob, je mogoče sestaviti presenetljivo verodostojna besedila.
Smisel življenja
Quoc Le, zaposlen na živahnem sedežu Googla v Mountain Viewju v Kaliforniji in eden od raziskovalcev, ki so pomagali razviti tak pristop, razmišlja o napravi, ki bi se lahko zares pogovarjala. Lejeve ambicije so povezane z bistvom vprašanja, zakaj je pogovarjanje s stroji lahko uporabno. »Rad bi odkril način, kako v stroju simulirati misli,« je pojasnil. »In če hočeš simulirati misli, moraš biti sposoben stroj vprašati, o čem razmišlja.«

Terry Winograd, zaslužni profesor z univerze Stanford: »Predstavljajte si stroje, ki ne temeljijo na človeški inteligenci, temveč na množičnih podatkih, a kljub temu vladajo svetu.«
Google svoje računalnike že uči osnov jezika. Maja letos je družba napovedala sistem z imenom Parsey McParseface, ki si ogleda skladnjo besedila in prepozna samostalnike, glagole in druge prvine besedila. Ni težko doumeti, kako dragoceno bi lahko bilo za Google boljše razumevanje jezika. Googlov iskalni algoritem je preprosto sledil ključnim besedam in povezavam med spletnimi stranmi. S sistemom RankBrain pa prebere tudi besedila na straneh, da izlušči pomen in izbere primernejše zadetke iskanja. Quoc Le bi rad to zmožnost še nadgradil. S kolegi je prilagodil sistem, ki se je izkazal za uporabnega pri prevajanju in označevanju podob, in sestavil Smart Reply, ki prebira vsebino poštnih sporočil na Gmailu in predlaga nekaj mogočih odgovorov. Napisal pa je tudi program, ki se je iz dnevnikov pogovorov Googlove tehnične podpore naučil odgovoriti na preprosta tehnična vprašanja.
Pred kratkim pa je Le sestavil program, ki je zmožen spodobno odgovarjati na vprašanja; usposobili so ga tako, da so vanj vnesli dialoge iz 18.900 filmov. Nekaj odgovorov je res posrečenih. Le je na primer vprašal, kaj je smisel življenja, in program je odgovoril: »Služiti višjemu cilju.« Široko se je zarežal: »To je bržkone boljši odgovor, kot bi ga dal sam.«
A ostaja težava, ki hitro postane očitna, če pregledamo še več odgovorov tega sistema. Ko je Le vprašal, koliko nog ima mačka, je njegov sistem odgovoril: »Mislim, da štiri.« Nato je poskusil še s številom nog pri stonogi, in odgovor je bil nenavaden: »Osem.« Lejev program torej nima pojma, o čem govori. Razume, da določene kombinacije simbolov sodijo skupaj, a nima popolnoma nobene predstave o resničnem svetu. Ne ve, kakšne so pravzaprav stonoge in kako se premikajo. To je še vedno samo privid inteligence brez takšne zdrave pameti, ki se ljudem zdi samoumevna. Sistemi za globoko učenje so glede tega pogosto nezanesljivi. Ta, ki ga je izdelal Google za označevanje podob, dela čudne napake, na primer kažipot na cesti opiše kot hladilnik, poln hrane.
Po nenavadnem naključju je prvi sosed Terryja Winograda v Palu Alto nekdo, ki bi računalnikom morda lahko pomagal pridobiti globlje razumevanje, kaj besede res pomenijo. Fei-Fei Li, direktorica laboratorija za umetno inteligenco na Stanfordu, je bila sicer na porodniškem dopustu, a me je povabila domov in mi ponosno pokazala trimesečno dojenčico Phoenix. »Poglejte jo, kako vas gleda bolj kot mene,« je komentirala Lijeva, ko je Phoenix strmela vame. »Ker vas ne pozna; to je zgodnje prepoznavanje obrazov.«
Lijeva je velik del svoje kariere raziskovala strojno učenje in računalniški vid. Pred nekaj leti je vodila projekt, da bi vzpostavili podatkovno banko z milijoni podob predmetov in vsakega označili z ustrezno ključno besedo. A Lijeva je prepričana, da morajo stroji še natančneje razumeti, kaj se dogaja na svetu, zato je njena ekipa letos zbrala še eno podatkovno banko s podobami, le da so te označene veliko podrobneje. Vsako podobo so ljudje označili z na desetine deskriptorjev. »Pes na rolki«, »Pes z mehko, kodrasto dlako«, »Cesta je razpokana« in tako naprej. Upa, da se bodo sistemi za strojno učenje naučili bolje razumeti fizični svet. »Jezikovni del možganov dobi veliko podatkov, s podatki sistema za vid vred,« je pojasnila Lijeva. »Pomemben del umetne inteligence bo integracija teh sistemov.«
To je že bliže temu, kako se učijo otroci, s povezovanjem besed s predmeti, odnosi in dejanji. A s tem se analogija s človeškim učenjem tudi konča. Majhnim otrokom ni treba videti psa na rolki, da bi si ga lahko predstavljali ali ga opisali. Lijeva je pravzaprav prepričana, da današnje strojno učenje in orodja umetne inteligence ne bodo dovolj za nastanek prave umetne inteligence. »To ne bo nekakšno globoko učenje z veliko podatki,« je prepričana. Lijeva je prepričana, da bi raziskovalci na področju umetne inteligence morali razmišljati o dejavnikih, kot sta čustvena in socialna inteligenca. »Ljudje smo grozni pri predelovanju velike količine podatkov,« je povedala, »odlični pa smo pri abstrakcijah in ustvarjalnosti.«
Nihče ne ve, kako strojem vcepiti te človeške veščine – oziroma ali je to sploh mogoče. Ali je pri teh lastnostih kaj tako izključno človeškega, da za umetno inteligenco ne bo nikoli dosegljivo?
Kognitivni znanstveniki, kot je Tenenbaum na MIT, razmišljajo, da pomembne sestavine uma niso vključene v sedanje nevronske mreže, pa če so še tako velike. Ljudje se lahko zelo hitro učimo iz razmeroma majhne količine podatkov in imamo prirojeno zmožnost, da svet zelo učinkovito modeliramo v treh razsežnostih. »Jezik se razvija na temelju drugih zmožnosti, ki so verjetno bolj osnovne in so značilne že za dojenčke, preden sploh govorijo: dojemanje besed vizualno, učinkovanje na motorične sisteme, razumevanje fizike sveta in namenov drugih akterjev,« je povedal Tenenbaum.
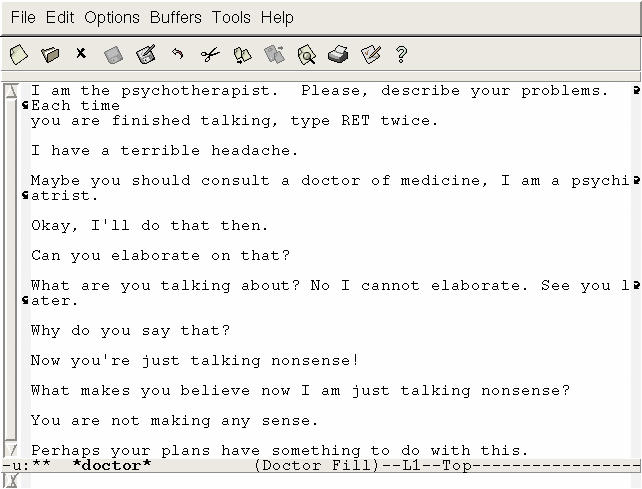
Eliza, eden prvih programskih »psihoanalitikov«. Malce za šalo, malce zares.
Če ima prav, potem bo razumevanje jezika brez posnemanja učenja pri človeku, kognitivnih modelov in psihologije težko poustvariti v strojih in sistemih umetne inteligence.
Dobesedno in preneseno
Kabinet Noaha Goodmana na oddelku za psihologijo na Stanfordu je praktično gol, če odštejemo abstraktni sliki, naslonjeni na steno, in nekaj podivjanih rastlin. »Jezik je poseben, ker se opira na veliko znanja o jeziku, obenem pa se opira tudi na veliko zdravorazumskega znanja o svetu in vse to se povezuje zelo prefinjeno,« je pojasnil.
Vzpostavljanje sistemov, ki vedo, da vedo, je res trd oreh.
Good s svojimi študenti razvija programski jezik, imenovan Webppl, s katerim je računalnikom mogoče vdihniti nekakšno verjetnostno zdravo pamet, kar se je v pogovoru izkazalo za precej uporabno. Ena od eksperimentalnih različic razume šale, druga se je sposobna spopasti s prispodobami. Če stroju rečejo, da je nekdo moral celo večnost čakati na mizo v restavraciji, se bo samodejno odločil, da dobesedni pomen ni verjeten in da verjetno to pomeni dolgo, neprijetno čakanje. Daleč od tega, da bi bil sistem inteligenten, a ponazarja, kako bi z novimi pristopi dosegli, da bi se programi umetne inteligence pogovarjali bolj življenjsko.
Goodmanov primer hkrati kaže, kako težko bo stroje naučiti jezika. Izraz »celo večnost« razumeti glede na okoliščine je nekaj, česar se bodo morali naučiti sistemi umetne inteligence, pa je to precej preprost dosežek in šele začetna stopnja.
Kljub težavnosti in zapletenosti problema začetni uspehi strokovnjakov, ki jim je s tehnikami globokega učenja uspelo prepoznati podobe in doseči mojstrstvo v igri, kot je go, zbuja upanje, da smo morda tudi pri jeziku tik pred prebojem. V tem primeru bodo novi dosežki kot naročeni. Če naj bi umetna inteligenca rabila kot splošno orodje, s katerim bodo ljudje nadgradili svojo inteligenco in mu prepuščali določene zadolžitve, ne da bi se bali dodatnih zapletov, bo ključen prav jezik. To bo še toliko pomembneje, ker sistemi umetne inteligence vse pogosteje uporabljajo globoko učenje in druge tehnike, da pravzaprav programirajo sami sebe.
»Na splošno sistemi za globoko učenje zbujajo globoko spoštovanje,« pravi John Leonard, predavatelj na MIT, ki raziskuje avtomatično vožnjo. »Po drugi strani pa je težko razumeti njihovo delovanje.«
Toyota, ki preučuje vrsto tehnologij za samovozeče avtomobile, je na MIT začela raziskovalni projekt pod vodstvom Geralda Sussmana, strokovnjaka za umetno inteligenco in programski jezik, da bi razvili avtomatizirane sisteme za vožnje, ki bi znali tudi pojasniti, zakaj so sprejeli določeno odločitev. Očiten način, kako bi samovozeči avtomobil to zmogel, bi seveda bil, da bi znal govoriti. »Vzpostavljanje sistemov, ki vedo, da vedo, je res trd oreh,« pojasnjuje Leonard, ki na MIT vodi drugi projekt pod pokroviteljstvom Toyote. »Toda ja, v idealnem primeru ne bi samo odgovorili, temveč tudi pojasnili.«

Googlov Parsey McParseface si ogleda skladnjo besedila in prepozna samostalnike, glagole in druge prvine besedila.
Nekaj tednov po tistem, ko sem se vrnil iz Kalifornije, sem poslušal govor Davida Silverja, raziskovalca v družbi Google DeepMind za raziskovanje umetne inteligence, ki je sestavil AlphaGo. Na akademski konferenci v New Yorku je govoril o igri proti Sedolu in pojasnil, da je bila njegova ekipa enako presenečena kot vsi gledalci, ko se je program med drugo igro domislil ubijalske 37. poteze. Razbrali so le to, da je AlphaGo izračunal možnosti za zmago, ki se niti po 37. potezi niso dosti spremenile. Šele nekaj dni pozneje, po skrbni analizi, je Googlova ekipa odkrila, da je program prebavil prejšnje igre in izračunal, kakšne so možnosti, da bi človeški igralec naredil enako potezo – ena proti 10.000. Igre s samim seboj za trening so stroju tudi pokazale, da je v igri mogoče pridobiti neobičajno izrazito prednost. Po svoje je stroj torej vedel, da bo Sedol padel v zasedo.
Kot je povedal Silver, Google razmišlja o številnih možnostih za komercialno rabo tehnologije, z nekakšnim pametnim pomočnikom in orodjem za zdravstvo vred. Nato sem ga vprašal, kako pomembna se mu zdi možnost sporazumevanja z umetno inteligenco, ki stoji za takimi sistemi. »Zanimivo vprašanje,« je rekel po razmisleku. »Za nekatere aplikacije bi lahko bilo pomembno. Recimo v zdravstvu je včasih pomembno vedeti, zakaj je bila sprejeta neka odločitev.«
In res si je težko predstavljati, kako bomo sodelovali z vse bolj naprednimi in zapletenimi sistemi umetne inteligence, če ne bodo obvladali jezika – če jih ne bomo mogli vprašati, zakaj. Še pomembneje pa je, da bi bili računalniki neprimerno uporabnejši, če bi se lahko nemoteno sporazumevali z njimi, in da bi bilo to pravzaprav čudežno. Navsezadnje je jezik naš najmočnejši način, da razumemo svet in delujemo vzajemno z njim. Čas je, da naši stroji nadoknadijo ta zaostanek.
Copyright 2016 Technology Review, distribucija Tribune Content Agency.