PostgreSQL 8.0
Le malokdo ne pozna podatkovne zbirke MySQL, najbolj priljubljene odprtokodne zbirke podatkov, ki v nemalo okoljih izpodriva komercialne tekmice in s tem uporabnikom znižuje stroške in hkrati ponuja okolje za razvoj preprostih aplikacij, ki temeljijo na zbirki podatkov. Temeljna funkcionalnost, ki jo ponujajo preproste zbirke podatkov, pa kaj kmalu ne zadošča več, in na vprašanje, kaj storiti, ni preprostega odgovora, ki ne bi vseboval ene od besedic MSSQL, DB2 ali Oracle. PostgreSQL je, presenetljivo, že več kot desetletje resna alternativa omenjenim, a je kljub temu, čeprav omembe vreden, precej neznan izdelek.
Zgodovina
Začetki PostgreSQLa segajo v zgodnja osemdeseta leta, ko so v oddelku za raziskave zbirk podatkov na kalifornijski univerzi v Berkeleyju pod vodstvom profesorja Michaela Stonebrakerja in sponzorstvom ameriške agencije DARPA, državne znanstvene fundacije NSF in podjetja ESL začeli razvijati projekt po imenu POSTGRES, katerega prva različica je ugledala luč sveta leta 1986. Poleg uporabe v izobraževalne namene je projekt rabil kot osnova za več izpeljank v praktične namene, kot zanimivost tudi programskemu paketu za izračun izkoristkov reaktivnih motorjev, zbirki za sledenje asteroidom, medicinskim, geografskim in finančnim projektom.
Če ime POSTGRES koga spominja na zbirko podatkov INGRES, to ni naključje, saj je bila tudi ta, v poznejših razvojnih obdobjih komercialna zbirka razvita v Berkeleyju. Eden izmed ključnih razvojnih ciljev POSTGRESa je bil pravzaprav nadomestiti pomanjkljivosti v zasnovi zbirke INGRES, predvsem na področju razširljivosti.
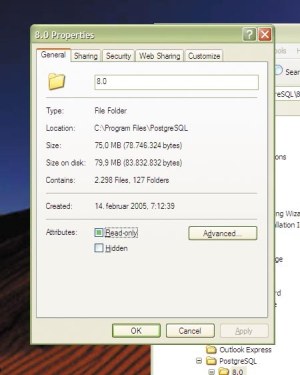
PostgreSQL 8.0 na disku zasede "le" 75 MB prostora.
Po slabem desetletju je postalo očitno, da komercialne zahteve otežujejo razvoj v smeri prvotnih ciljev, zato je bil projekt leta 1993 v različici 4.2 ustavljen, delo pa usmerjeno na manj znane projekte. POSTGRES sta, med drugim, do tedaj posvojila tudi podjetje Illustra Information Technologies in projekt Sequoia 2000, ki sta leta 1992 skupaj začela razvijati komercialno različico Montage, podjetje Illustra pa je na njem zasnovalo tudi dobro znano zbirko Informix, danes v lasti IBM.
Že naslednje leto sta Andrew Yu in Jolly Chen kljub uradni opustitvi projekta POSTGRESu dodala tolmač za jezik SQL, programsko kodo pa je pod okriljem ene prvih odprtokodnih licenc, BSD, pod imenom Postgres95 naprej razvijala vedno večja skupina prostovoljcev. V naslednjih dveh letih so različico 1.0 z izboljšavami vred oklestili četrtine stare programske kode, to pa je, kljub številnim novim lastnostim, povzročilo tudi precejšnje izboljšanje izrabe sistemskih sredstev in hitrosti delovanja.
Leta 1996 je postalo jasno, da ime Postgres95 ne bo primerno, zato je bil projekt preimenovan v PostgreSQL, kar odseva povezavo med starim POSTGRESom in novo podporo jeziku SQL, razvoj pa se je nadaljeval kot različica 6.0. Medtem ko je bila večina dela v fazi Postgres95 namenjena odpravi nerodnosti v strežniški kodi, je razvoj zdaj razširjen na vsa področja, predvsem pa usmerjen v dodajanje novih zmogljivosti, ki so sčasoma zbirko upravičeno postavile na mesto najbolj napredne odprtokodne zbirke podatkov na svetu.
Temeljne lastnosti
PostgreSQL v različici 8.0 podpira večji del standarda ISO/IEC 9075:2003 ali, krajše, SQL:2003, kar bi bilo seveda precej težko, če si celotna skupina razvijalcev že v preteklosti ne bi prizadevala doseči čim boljšo podporo starejšima standardoma SQL-92 in SQL:1999. Tudi odlična spremljajoča dokumentacija to dokazuje, saj opis vsakega stavka SQL spremlja tudi razdelek o združljivosti, v katerem so natančno opisane pomembne razlike, v katerih se stavek razlikuje od zahtev standarda SQL, če seveda je tako. Polna podpora standardu Core SQL:2003 pogojuje tudi zapletene poizvedbe, referenčno integriteto, prožilce, poglede, transakcije in druge napredne lastnosti, zato je nujno, da zbirka podpira tudi te.
Tudi ACID (Atomicity, Consistency, Isolation, Durability), načelo delovanja, ki mu PostgreSQL v vseh pogledih ustreza, je predpogoj za uporabnost relacijskih zbirk podatkov. To načelo določa obnašanje zbirke v mejnih primerih, ko je poizvedba po zbirki prekinjena ali pa hkrati več zahtev izvaja operacije, ki bi si utegnile med seboj nasprotovati, zbirka pa mora vse poizvedbe obravnavati na način, ki omogoča predvidljivo delovanje in zagotavlja, da se tudi po najhujših scenarijih ne zgodi, da bi si bilo nemogoče opomoči in nadaljevati delo.
PostgreSQL loči od drugih zbirk podatkov SQL to, da je ena redkih, ki za zapis in delo s podatki uporablja način MVCC, Multi-Version Concurrency Control, kar pomeni, da za zagotavljanje enovitosti podatkov ob hkratnih dostopih ne uporablja zaklepanja zapisov, temveč poseben model zapisovanja, ki ob začetku transakcije le-tej zagotovi enovit, osamljen pogled na stanje zbirke skozi vso njeno življenjsko dobo. To ima za posledico, da branje nikoli ne onemogoča pisanja, in nesprotno, nikdar se ne zgodi, da bi bilo branje iz zbirke onemogočeno, ker neka operacija ne dovoljuje vpogleda v zbirko zaradi pisanja po njej. Za aplikacije, ki jih je pretežko prilagoditi takemu načinu dela, je sicer še vedno mogoče zaklepanje, a načeloma velja, da je delo z zbirko preprostejše, pa tudi hitrost delovanja zbirke je večja ob izrabi možnosti, ki jih ponuja MVCC.
Delovanje
Obdelava poizvedb po zbirki deluje v štirih korakih. Po vzpostavitvi povezave strežnik najprej preveri sintaktično pravilnost prejetega stavka in izdela t. i. poizvedbeno drevo, a to ne vpleta nobenih poizvedb in podatkov v zbirki. Strežnik zgolj preveri sintaktično pravilnost prejetih stavkov, loči transakcije od preprostih poizvedb in izdela pomensko drevo njihove zgradbe.
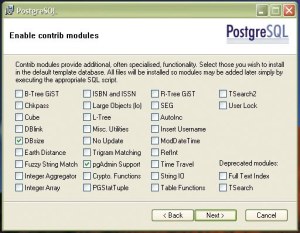
Razširitve, zajete v namestitveni paket PostgreSQL za Windows.
V drugem koraku se poizvedbeno drevo obdela po sistemu pravil, ki za vsak stavek ugotovijo, ali gre v posameznem elementu le-tega za klic uporabniške ali t. i. združevalne funkcije (aggregate), ločijo tabele od pogledov (view) in bralne poizvedbe (select) od tistih, ki podatke spreminjajo (update, insert, delete). Sistem pravil ima dve pomembni lastnosti. Pravila za pretvorbo poizvedb ne potrebujejo podatkov, ki so dejansko shranjeni v tabelah, dostop imajo le do podatkov o strukturi tabel, zato so izredno hitra. Druga pomembna lastnost je ta, da imajo tudi uporabniki možnost določanja lastnih pravil, kar omogoča izdelavo kompleksnih sistemov poizvedb, kjer je vsak podstavek poizvedbe mogoče pogojiti s poljubnim številom implicitnih podstavkov, na katere je prav tako mogoče vplivati s pravili. To lahko razvijalcem precej olajša delo, vendar pa precej večjo vlogo kot navadno odigra dobra komunikacija med upravljavcem zbirke in razvijalci, predvsem v smislu ozaveščanja glede možnosti, ki so na voljo.
Modificirano poizvedbeno drevo v naslednjem koraku obdela načrtovalec poizvedb ali query planner. Njegova naloga je, da med vsemi možnimi načini obdelave poizvedbenega drevesa najde najhitrejšega, in tudi v tem je PostgreSQL zelo prožen. Med vsemi uporabljanimi tabelami, načini združevanja teh tabel in preiskovanja podatkov v tabelah je treba izbrati tiste, ki bodo obdelane najprej, in poiskati optimalni vrstni red. To je korak, v katerem ključno vlogo odigra upravljavec zbirke podatkov, saj mu dobro poznavanje načina obdelave in predvsem obteževanja posameznih elementov poizvedbe omogoča vplivati na vrstni red obdelave in izbrane mehanizme, to pa včasih pomeni tudi več desetkrat hitrejšo (ali počasnejšo) obdelavo. Na srečo ima PostgreSQL na voljo izreden nabor mehanizmov, s katerimi je moč vplivati na posamezne spremenljivke.
Zadnji korak je izvedba izbranega načrta poizvedbe, kar v bistvu ne pomeni nič drugega kot sprehod po poprej izbranih podatkovnih strukturah, urejanje podatkov in njihovo dostavo odjemalcu. Za katerokoli podatkovno zbirko, ki jo v življenjski dobi čaka resnejša obremenitev, je pomembno predvsem skrbno načrtovanje vrste obremenitev in dobra ocena t. i. delovnega nabora podatkov. Iluzorno je namreč pričakovati, da bi bilo moč s čimerkoli drugim kot gručo računalnikov in vsaj toliko delovnega pomnilnika, kolikor je podatkov, doseči približno enako hiter dostop do kateregakoli podatka v zbirki. V vseh drugih primerih je dobra ocena velikosti delovnega nabora podatkov tisti pogoj, ki ob nabavi strojne opreme omogoča pravilno dimenzioniranje komponente, ocena vrste obremenitev, ki jih zahteva delo s podatki, pa pove, ali je razpoložljiva finančna sredstva bolj smiselno porabiti za nakup hitrejšega procesorja, več delovnega pomnilnika ali hitrih diskov SCSI, povezanih v diskovno polje RAID10. Prav strojna oprema najbolj vpliva na zadnji korak obdelave poizvedbe tudi v PostgreSQLu.
Načrtovalec poizvedb
Z nastavitvami je mogoče vplivati na načrtovanje poizvedbe z najrazličnejših vidikov, od katerih je eden zanimivejših namig o tem, koliko delovnega pomnilnika PostgreSQLu utegne ostati na razpolago za predpomnilnik. PostgreSQL se namreč ne obremenjuje z lastnim predpomnilnikom; to pragmatično prepušča operacijskemu sistemu. Večina operacijskih sistemov podatke, prebrane z diska pred kratkim, zadrži v delovnem pomnilniku za primer, če bi jih potreboval še kdo, nato pa so po nekem algoritmu staranja počasi odstranjeni. Zanimajo ga tudi vrednosti, kot sta npr. na eni strani cena branja naključne strani podatkov z diska v pomnilnik in na drugi ista količina za obdelavo strani, ki je že v delovnem pomnilniku. S tem si pomaga ob odločanju, ali je smotrneje preiskati tabelo ali uporabiti kazalo. To odločanje se imenuje Index Cost Estimation ali, krajše, ICE.
Vse doslej povedano, čeprav koristi tudi pri vsakdanji uporabi zbirke, je pomembno za razumevanje mehanizma obdelave stavkov, ki združujejo mnogo tabel (join), kar je velika prednost PostgreSQLa v primerjavi z ostalimi podatkovnimi zbirkami. Za združevanje tabel so na voljo različne tehnike parjenja podatkov, npr. gnezdene zanke, združevanje po ključih, zlivanje ipd., izbira tehnike pa je odvisna tudi od pogojev, s katerimi so tabele združene, in kazal, s katerimi so opremljene. Standardni pristop k izvedbi takih stavkov, ki ga uporablja večina zbirk podatkov, t. i. near-exhaustive search, v vsakdanjih razmerah pa tudi PostgreSQL, zahteva izračun najboljšega načrta za izvedbo združevanja, težava takega pristopa pa sta čas, porabljen za izdelavo načrta, in količina za to porabljenih sistemskih sredstev, ki rasteta eksponentno s povečevanjem števila pridruženih tabel.
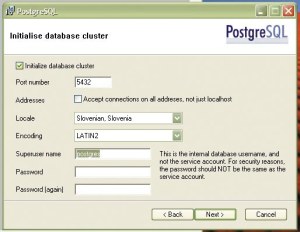
Namestitveni program se ponudi, da namesto nas ustvari začetni grozd zbirk podatkov (template0 in template1).
Združevanje tabel najdemo najpogosteje v zbirkah, kjer je korelacija med podatki velika in kjer se v določenih stolpcih znotraj ene tabele podatki pogosto ponavljajo ali pa se podvajajo v več tabelah hkrati. S postopkom zmanjševanja količine podvojenih podatkov v zbirki, normalizacijo, je mogoče podatke prestaviti v ločene organizacijske enote, tako izboljšati izkoristek prostora in poenostaviti relacijsko shemo zbirke ter s tem doseči tudi večjo preglednost. Ker pa je cena združevanja številnih tabel v eni sami poizvedbi tako visoka, visoko normalizirane zbirke podatkov niso ravno pogoste, ne nazadnje tudi zaradi razmeroma nizke cene diskovja v primerjavi s ceno delovnega pomnilnika in procesorjev. Negativna posledica take organizacije podatkov v zbirki sta žal ponavadi ravno prevelika poraba delovnega pomnilnika za predpomnilnik in počasen dostop do posameznih tabel ob spreminjanju podatkov.
Na podobne težave so naleteli tudi pri načrtovanju sistema za vzdrževanje električnega omrežja na Inštitutu za avtomatizacijo nadzora na Univerzi za rudarstvo in tehnologijo v Freibergu. PostgreSQL, ki so ga uporabili v ta namen, so zato razširili tako, da namesto klasičnega načrtovanja poizvedb v takih primerih uporablja GEQO, Genetic Query Optimizer, ki za razliko od prej omenjenega postopka uporablja algoritme, ki so sicer bolj znani iz genetike: rekombinacijo, mutacijo in selekcijo. Z uporabo teh treh postopkov je mogoče priti do optimalnega načrta združevanja v neprimerno krajšem času, kot bi bilo to mogoče sicer. Kriteriji za primernost (selekcija) se sicer ne razlikujejo od tistih v klasičnem načrtovalcu poizvedb - še vedno je najvažneje to, kako čim hitreje priti do želenih podatkov, o čemer se je mogoče odločiti na podlagi statistik o porazdelitvi in kardinalnosti podatkov v tabelah, pričakovanj o tem, koliko posamezne tabele je verjetno že v predpomnilniku operacijskega sistema, kazal, ki so na voljo za aktualne stolpce v tabelah in cene metode, ki bo uporabljena za parjenje posameznih stolpcev. Bistvena razlika je v tem, da se primerne metode za parjenje in vrstni red le-tega iz izbora možnosti izluščijo precej hitreje, a v veliki večini primerov še vedno zagotavlja tudi dovolj hitro izvedbo načrta.
Razširljivost
Kazala, ki si nedvomno zaslužijo omembo, so vrste GiST. To je kratica za skupino metod gradnje dreves kazalcev, ki jim je skupno to, da za dostop do listov drevesa vse uporabljajo okvir, ki ga določa t. i. posplošeno iskalno drevo ali Generalized Search Tree. Konkretno to pomeni, da je v kazalih GiST mogoče uporabiti poljubne podatkovne tipe, podatki pa so v njih lahko urejeni v poljubni drevesni shemi, najsi bo to B+, R ali kaka druga. Bistveno za to skupino kazal je, da za njihov razvoj ni treba prav dobro poznati zbirke podatkov - dovolj je obvladovanje programiranja in poznavanje podatkovnega tipa, ki naj bi ga kazalo vsebovalo.
Zakaj tolikšno posploševanje? PostgreSQL brez razširitev podpira dvaintrideset osnovnih podatkovnih tipov, od numeričnih, znakovnih in časovnih pa do geometričnih, tistih omrežne narave (npr. naslov IPv6 ali MAC) in kombiniranih (kot so podatkovne razpredelnice, objekti in dedovanje). Omogoča razširljivost tako na področju podatkovnih tipov kot tudi operatorjev in funkcij za njihovo obdelavo ter združevalnih funkcij nad stolpci takih podatkov. Ravno kazala GiST pa so tista, ki dajejo tej množici podatkovnih tipov tudi praktično vrednost, saj omogočajo poenostavljanje zgradbe zbirke z njihovo uporabo v ključih in tako povečajo tudi njihovo uporabnost v zbirki.
PostgreSQL je nadvse razširljiv tudi na področju programiranja zbirke podatkov na ravni prožilcev (trigger) in funkcij. Za razvoj kode je poleg objektnih datotek, ki jih razvijalec lahko napiše v kateremkoli jeziku in jih s pomočjo knjižnice libpq vključi v strežnik, na voljo tudi pet uradnih tolmačenih postopkovnih (procedural) jezikov, v katerih je mogoče pisati prožilce in funkcije, od katerih je bil pl/pgsql razvit posebej za uporabo v PostgreSQLu, pl/tcl, pl/perl, pl/python in pl/java pa so že znani programski jeziki, razširjeni in prilagojeni delu z zbirko. Omeniti velja še dva dodatna projekta, pl/R, ki je namenjen predvsem statističnim obdelavam znotraj zbirke, in plMono, ki uporablja Mono, odprtokodno okolje .NET, in podpira praktično vse jezike iz tega okolja (v tem trenutku šestnajst).
Novosti v različici 8.0
Kljub vsem že naštetim lastnostim je PostgreSQL pred osmo različico veljal le za približno enakovredno rešitev komercialnim zbirkam podatkov. Šele zadnja izdaja ga dejansko uvršča "ob bok velikim", kar pa ne pomeni, da je v novih lastnostih novinec. Zadnje tri izdaje, 7.3, 7.4 in 8.0, so namreč vse težile v isto smer, s temeljitimi pripravami na nove lastnosti, od osnovnih komponent strežnika naprej. Eno od načel razvoja je, da je nova različica objavljena šele, ko je popolnoma nared in že vsaj četrt leta v poskusni rabi, del zbirke pa je tudi nabor regresivnih testov, ki preverijo brezhibnost nove namestitve in zagotovijo pravilno delovanje v vsakem okolju. V času pred izdajo PostgreSQL navadno uporablja precejšnje število podjetij, ki ponujajo tudi komercialno podporo in svetovanje pri uporabi zbirke, zanimivo pa je, da je tudi koncern Fujitsu v zadnjih letih v razvoj PostgreSQLa vložil zelo veliko količino sredstev.
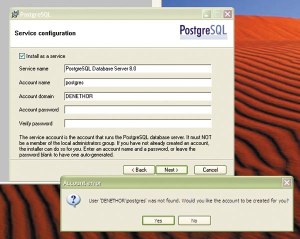
Tudi za varnost na ravni delovanja je po dobri, stari UNIXovski tradiciji poskrbljeno.
Prva, morda celo ena manj pomembnih novosti, nedvomno zelo velika za vse novince, ki zbirke še ne poznajo, pa bi jo radi, in vse projekte, ki imajo za osnovo to okolje, pa bi radi razširili območje delovanja, je podpora družini operacijskih sistemov Windows. PostgreSQL je bilo pred različico 8.0 sicer mogoče uporabljati v tem okolju, vendar samo z dodatkom Cygwin. Nova različica je to omejitev odpravila, v paketu pa so skupaj PostgreSQL, vsi standardni dodatki in program pgAdmin, grafični vmesnik za delo z zbirko.
Druga novost zadeva transakcije. Težava z večino zapletenih transakcij je, da je takrat, ko spodleti en stavek v zaporedju, izgubljen celoten paket operacij, ne glede na uspeh prejšnjih. Na srečo standard SQL za transakcije določa možnost posebne lastnosti, ki poveča drobljivost le-teh. Točke vrnitve ali savepoints določajo posamezna operativna območja v transakciji, na začetek katerih se je v primeru spodletelega stavka mogoče vrniti, kritično mesto v postopku zaobiti ter nalogo, s katero se transakcija ukvarja, rešiti drugače. V prvi vrsti to pomeni pridobljen čas pri izvajanju takih transakcij v aplikacijah, saj le-te lahko sorazmerno nemoteno nadaljujejo z delom znotraj transakcije, tudi če pride do napake.
Dveh novosti bodo veseli predvsem skrbniki zbirk podatkov. Prva omogoča boljše prilagajanje hrambe podatkov diskovnemu podsistemu strežnika, na katerem je nameščen PostgreSQL. Poleg splošne prepustnosti zbirke, ki zaradi neprestanega dela, vloženega v izboljšave ICE in načrtovalca poizvedb, že tradicionalno doživi izboljšanje v vsaki novi različici PostgreSQLa, je tu še ena težava. Treba je ločevati tudi med zbirkami podatkov in tabelami znotraj zbirk, ki so izpostavljene večji količini bombardiranja s poizvedbami in zato tekmujejo za prepustnost diskovnega podsistema strežnika s preostalimi. Če odmislimo zgolj pretok podatkov, tudi mehanske komponente diskovja pogosto postavljajo resne omejitve: gledano kumulativno, so časi, porabljeni za premike glave na disku z več zbirkami, precej daljši.
V strežniku, opremljenem z več diski ali diskovnimi polji RAID, je zato navada dodeliti posameznim enotam gruče zbirk podatkov ločene naprave in jim tako zagotoviti polno prepustnost, ki jo zmore neki disk ali diskovno polje. S takim načinom porazdelitve objektov znotraj gruče zbirk je mogoče tudi zmanjšati količino, predvsem pa dolžino "poskakovanja" glav na sprejemljivo. To v PostgreSQLu že dozdaj ni bila težava za posamezne zbirke podatkov, prostori za tabele ali tablespaces pa so rešitev, ki v novi različici omogoča še boljšo razdrobljenost z vidika upravljanja.
Naslednja novost bo olajšala življenje vsem, ki imajo težave z varnostnimi kopijami. Povečini je namreč zelo težko priti do zanesljivih večstopenjskih (incremental) varnostnih kopij. V primeru zbirke podatkov z več milijoni zapisov je to seveda silno nerodno - ob vsaki vnovični izdelavi varnostne kopije je treba iz zbirke na neki nosilec, ki je navadno nekajkrat počasnejši, prenesti vso množico podatkov, to pa traja in traja. Med restavriranjem varnostnih kopij je stanje še slabše - kako priti do točno določenega podatka, ki nas zanima? Tudi performančne zmogljivosti zbirk so med izdelavo varnostnih kopij precej okrnjene, nekaterih pa v tem času celo ni mogoče uporabljati.
V ta namen transakcijske zbirke podatkov vodijo dnevniške datoteke, v katere zapisujejo vse operacije, ki spreminjajo podatke. Kadar med delom doživi nepričakovano prekinitev, je proces okrevanja zbirke po katastrofi v osnovi zelo preprost: ob vnovičnem zagonu pregleda dnevniške datoteke, poskuša ugotoviti, katere transakcije so se pred prekinitvijo dela uspešno končale, in bodisi zavrže bodisi znova izvede tiste, ki jim dela ni uspelo končati. Naprednejša različica tega mehanizma ob vnovičnem zagonu omogoča tudi izbiro točke v času, od katere bi želeli nadaljevati, zato je splošno ime zanj PITR ali Point-In-Time Recovery.
Z vidika varnostnih kopij to pomeni zelo preprost način izdelave večstopenjskih kopij: poleg rednih kopij podatkov v zbirki je mogoče v varnostni načrt uvrstiti kar dnevniške datoteke z zapisi transakcij. To po vnovični vzpostavitvi delovanja omogoča upravitelju v zbirko naložiti zadnjo polno varnostno kopijo podatkov in toliko dnevniških datotek, kolikor jih želi oziroma potrebuje za normalno delovanje. Izdelavo večstopenjskih varnostnih kopij lahko tako upravljavec nastavi poljubno pogosto.
Razširitve
Bodisi v izvirni kodi bodisi v namestitvenem paketu zbirke podatkov PostgreSQL je zajeto že kar nekaj standardnih razširitvenih modulov. Vseh nima smisla naštevati, saj jih je preveč, nekaj atraktivnejših in aktualnejših pa vseeno omenimo.
Poleg nekaj izvedb dreves vrste B, R in L s kazali GiST za vse standardne podatkovne tipe so na najnižji ravni razširitvenih modulov na voljo še izvedbe podatkovnih tipov (in seveda spremljajoče funkcije ter operatorji za delo z njimi) večrazsežnostne kocke, zemeljske razdalje, knjižnih tipov ISBN in ISSN itd. Na voljo so tudi tri ločene izvedbe tekstovnega indeksa, namenjenega iskanju po stolpcih z veliko tekstovne vsebine, in dva sorodna modula: eden je namenjen približnemu iskanju nizov, drugi pa izdelavi trigramskih profilov besedila, kar je moč koristno uporabiti pri identifikaciji jezika, v katerem je napisano (daljše) besedilo.
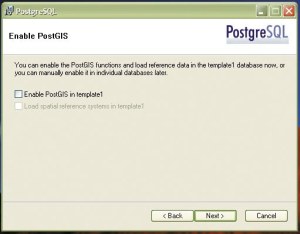
Razširitve, naložene v "template1", so dostopne tudi v naknadno ustvarjenih zbirkah.
Dve razširitvi omogočata inteligentno hrambo in generiranje datotek XML neposredno iz tabele v zbirki. Ena od njiju je že precej stara in je zato ni več priporočljivo uporabljati, je pa namenjena vsem tistim, ki so iz kakršnegakoli razloga "obsojeni" na delo s knjižnico expat. Novejša različica te razširitve uporablja knjižnico libxml, podpira pa poizvedbe XPath in omogoča pretvorbe vrste XSLT.
Med množico preostalih razširitev omenimo še tiste za delo z velikimi objekti (Large Objects, "lo"), pripomočke za vnovično izgradnjo kazal, poizvedbe po več zbirkah hkrati (tudi tistih na drugih strežnikih), nekaj osnovnih skript za pomoč pri pretvorbi shematskih datotek in prilagoditvi podatkov ob prenosu iz drugih zbirk podatkov, npr. MySQL in Oracle.
Na projektnih spletiščih PGFoundry in GBorg drugih razširitev kar mrgoli. Od malce bolj sistemskih omenimo dve rešitvi za replikacijo podatkov in porazdelitev bremena: pgpool in Slony-1, od katerih je prva namenjena porazdelitvi bremena v preprostih zbirkah, ki temeljijo predvsem na bralnih poizvedbah, druga pa omogoča izgradnjo kompleksnih replikacijskih shem na ravni posameznih tabel. pgpool in Slony-1 znata med seboj tudi sodelovati. Zanimivejša sta morda tudi PostGIS in OpenFTS, prvi poleg standardnih geometrijskih tipov PostgreSQLu doda tudi geografske, skupaj z goro funkcij in podporo podatkom v oblikah ESRI, GEOS, projekcijam, transformacijam itd., drugi, OpenFTS, pa uporabniku omogoča s pomočjo razširitve tsearch2 zbirko uporabiti kot iskalnik s tekstovnimi kazali in rangiranjem rezultatov po primernosti. Za to ponuja tri različne programske vmesnike v jezikih perl, TCL in python. Več o teh nedvomno zanimivih izdelkih pa kdaj drugič.
Odjemalci
V namestitvenem paketu za Windows, zelo verjetno pa tudi v vseh distribucijah Linuxa, ki v svojem naboru paketov zajemajo PostgreSQL, je tudi grafični vmesnik po imenu pgAdmin3. Ime govori, da gre že za tretjo generacijo programa, marsikatera podrobnost pa to tudi dokazuje. Namenjen je prav vsem, ki bi želeli delati z zbirko - od uporabnikov, ki ne potrebujejo kaj več, kot vnesti poizvedbo, do upraviteljev in razvijalcev. Glede na to, da v različici 1.2.0 podpira vse lastnosti nove različice PostgreSQLa, precej dobra pa je tudi integracija PostgreSQLove dokumentacije, je zagotovo aplikacija, ki je ne sme spregledati nihče, ki dela z zbirko. Ena izmed lastnosti, načrtovanih za bližnjo prihodnost, je tudi podpora projektu Slony-1. Poleg pgAdmin3 je na voljo še nekaj vmesnikov za delo z zbirko, npr. phpPgAdmin, spletni vmesnik, napisan v PHPju, in podobni.
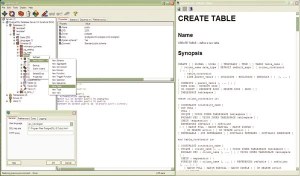
Program za upravljanje strežnikov PostgreSQL, pgAdmin3, s priloženo dokumentacijo.
Komunikacijski protokoli, ki jih podpira zbirka, zajemajo vse standardne gonilnike, od lastnega protokola pa do gonilnikov JDBC (tudi SQLj) in ODBC. Tudi vmesniki za programiranje podpirajo široko paleto jezikov: PHP, perl, C, C++, objective C, tcl, python, ruby, ECPG, .NET, prolog, matlab ... Skratka, v duhu zbirke - razširljivo.
Standard ISO/IEC 9075:2003
Mednarodna organizacija za standardizacijo, ISO, vsakih nekaj let izda novo, predelano in dopolnjeno različico standarda ISO/IEC 9075 z imenom "Jezik za zbirke podatkov SQL", vsaka naslednja izdaja pa nadomesti prejšnjo. Zadnja različica je bila izdana leta 2003.
Ker je standard SQL zelo zapleten in v precej primerih ureja tudi delovanje zbirk, utegne poseči precej globoko v drobovje zbirke, ni pa pisan "na kožo" nobeni posamezni že obstoječi zbirki podatkov. Večina zbirk podatkov, ki stremijo po združljivosti s standardom, si zato prizadeva za združljivost le na področjih, kjer je to smiselno in mogoče v okvirih že obstoječega izdelka.
SQL-92 je zavoljo tega opredeljeval tri nabore lastnosti, pomembne za združljivost: začetnega, vmesnega in popolnega, vendar je velika večina zbirk podatkov ustrezala le začetnemu, ker sta bila preostala nabora bodisi preobsežna bodisi nezdružljiva z obstoječo funkcionalnostjo teh zbirk. Začenši s SQL:1999, so bile kategorije razdeljene na nabore posameznih lastnosti, ki jih standard nato znova združuje v več funkcionalnih paketov, temeljni pa se imenuje "Core SQL Features" in je obvezen za vse zbirke, ki bi želele doseči združljivost s katerimkoli od drugih.
Standard SQL:2003 je prav tako razdeljen na več delov:
PostgreSQL je združljiv z deli 1, 2 in 11. Tretji del je zelo podoben vmesniku ODBC, četrti pa jeziku PL/pgSQL, vendar noben od njiju ni ravno območje, na katerem bi potekala kakšna resna prizadevanja za standardizacijo. Po drugi strani je PostgreSQL združljiv z vsaj 150 od 164 obveznih lastnosti v naboru Core SQL:2003 in še s celo množico dodatnih.
Uporaba stavka EXPLAIN
Stavek EXPLAIN je popolnoma nepogrešljiv, ko je treba izboljšati obnašanje zbirke, kadar je treba razumeti, zakaj poizvedbe trajajo predolgo, kako jih napisati bolje, katera kazala so odvečna, katera bi bilo treba prilagoditi, pa tudi kar tako, ko nas zanima, kako zbirka pride do zaključkov, ki jih uporablja v zadnji fazi obdelave poizvedbe.
EXPLAIN je na voljo v dveh različicah, kot preprosti EXPLAIN in podrobnejši EXPLAIN ANALYZE, oba pa dovoljujeta tudi dodatno besedico VERBOSE, ki še natančneje razloži posamezne elemente poizvedbe. Razlikujeta se predvsem po tem, da prvi stavka ne izvede, temveč le pove, kakšen je načrt izvedbe, drugi pa ga tudi izvede in primerja predvidene vrednosti z dejanskimi.
Stavek SELECT, ki zajema podatke iz štirih tabel, na vseh poljih, po katerih jih združuje, uporablja kazala ter vsebuje opise 350.000 dogodkov z vsega skupaj 5,5 milijona zajetimi količinami, za natančno določeno številko dogodka in vse količine, zajete v njem (šestnajst jih je), potrebuje 12 milisekund. Če spremenimo pogoj tako, da namesto enega dogodka vrne podatke za dva, naenkrat potrebuje minuto in pol. Kaj je narobe?
plip=# EXPLAIN ANALYZE SELECT e."timestamp", e."sequence",
m.short_name, d.value, q.unit
FROM events e, metrics m, data d, quantities q
WHERE d.event_id = e.id AND d.metric_id = m.id
AND m.quantity_id = q.id AND e.id = 10120;
...
-> Index Scan using data_pkey on data d
(cost=0.00..547.31 rows=136 width=12)
(actual time=0.612..0.616 rows=1 loops=18)
...
Total runtime: 12.030 ms
plip=# EXPLAIN ANALYZE SELECT ... AND e.id BETWEEN 10120 AND 10121;
...
-> Seq Scan on data d
(cost=0.00..84892.19 rows=5424519 width=12)
(actual time=0.326..23820.163 rows=5664960 loops=1)
...
Total runtime: 97889.071 ms
Vidimo, da je v drugem primeru za tabelo z imenom "data" načrtovalec zapovedal zaporedno preiskovanje namesto uporabe kazala po polju "event_id", kar poveča število pregledanih vrstic z osemnajst na 5,6 milijona. To se zgodi, ker načrtovalec predvideva, da je kardinalnost podatkov v tabeli prenizka, da bi se izplačalo uporabiti kazalo. Ker to ni res, lahko predvidevamo, da se napačen načrt zgodi iz enega od dveh možnih vzrokov: tabela še ni bila analizirana z uporabo ANALYZE ali pa je distribucija vrednosti v stolpcu tako nepravilna, da so vzorci podatkov za izračun statistik premalo reprezentativni.
Po pogledu v sistemsko tabelo "pg_stats" se izkaže, da so statistike, ki jih strežnik vodi o stolpcu "event_id", resnično napačne:
plip=# SELECT attname, n_distinct FROM pg_stats
WHERE tablename = 'data' AND attname = 'event_id';
attname | n_distinct
----------+------------
event_id | 30804
plip=# SELECT COUNT(DISTINCT(event_id)) FROM data;
count
--------
354060
To je moč popraviti tako, da spremenimo velikost vzorca, ki ga strežnik preišče ob izračunu statistik, mu naročimo, naj tabelo še enkrat analizira, in znova poženemo EXPLAIN:
plip=# ALTER TABLE ONLY data ALTER COLUMN event_id SET STATISTICS 100;
ALTER TABLE
plip=# VACUUM FULL ANALYZE data;
VACUUM
plip=# SELECT attname, n_distinct FROM pg_stats
WHERE tablename = 'data' AND attname = 'event_id';
attname | n_distinct
----------+------------
event_id | 341654
plip=# EXPLAIN ANALYZE SELECT ... AND e.id BETWEEN 10120 AND 10121;
....
Total runtime: 1.457 ms
Sklep
PostgreSQL je nedvomno zrel izdelek, ki mu do popolnoma enakovrednega statusa, kot ga uživata DB2 in Oracle, ne manjka več veliko. Vse lastnosti, v katere so nekateri pripravljeni vlagati milijone tolarjev, kot so npr. visoka razpoložljivost in distribuirane namestitve, je z malo truda že mogoče doseči ali pa jih trenutno razvijajo, na "domačem" področju, pri delu z zbirkami podatkov, pa PostgreSQL že kar nekaj časa uspešno konkurira velikim.
Vsakomur, ki se še odloča o zbirki podatkov, pa ima v mislih kaj več kot zgolj nekaj preprostih razpredelnic, ter tistim, ki bi si želeli zbirke podatkov, ki v prihodnosti projekta pušča odprtih čim več možnosti za širitev, tudi v nepredvidene smeri, je PostgreSQL pisan na kožo.