Ko mora biti naključje res naključje
Naključna števila potrebujemo pri šifriranju, poganjanju simulacij, analizi podatkov, vzorčenju, integriranju, razvrščanju na naključnih seznamih in še marsikje. Potrebe so tolikšne, da metanje kock in kovancev že zdavnaj ne zadostuje več. Pomislimo na pomoč računalnikov. Ti znajo dandanes izračunati skorajda vse, le naključnih števil ne. Od kod jih dobimo?
Ob naključnost povprečni uporabnik računalnikov največkrat trči pri vrstnem redu predvajanja skladb, ustvarjanju naključnih gesel in kakšnem kvizu. Še večkrat pa naključnost uporablja pri šifriranju podatkov, na primer ob vsakemu obisku e-banke, čeprav tega največkrat niti ne ve. Računalnik mora tedaj zagotoviti neki naključen niz podatkov. Če pomislimo, da ima računalnik takšno ime zato, ker računa – torej izvaja predpisane algoritme – se vprašamo, kako lahko iz determinističnih algoritmov dobimo naključna števila. Ne moremo jih, zato bodisi uporabljamo boljše ali slabše približke bodisi smo prisiljeni nekaj izmeriti.
Tvorjenje naključnih števil z računalniki je bistveno težje, kot se zdi na prvi pogled. Računalnik namreč na enako vprašanje vedno vrne enak odgovor. Pravzaprav je to njegova naloga, saj so namenoma sestavljeni tako, da to drži in da se naključnosti izognemo. Kako torej dobiti naključno število iz računalnika?


Človeško oko je izurjeno za zaznavanje vzorcev, zato vizualizacija naključnih števil hitro pokaže periodične vzorce. Levo: naključna števila z random.org, desno: števila iz algoritma v Windows.
Spletni generator naključnih števil
Kadar potrebujete resnično naključno število, si lahko pomagate s stranjo www.random.org. Tam lahko brezplačno tvorite naključna števila, mečete navidezno kocko, vlečete karte iz premešanega kupa itn. Prav tako lahko svoj poljuben seznam postavite v naključni vrstni red, generirate naključno geslo, predvajate naključni beli šum, izberete naključni datum ali uro, pogledate naključno sliko belih in črnih točk itn.
Random.org naključna števila, iz katerih sestavi vse svoje ponujene storitve, tvori z meritvami atmosferskega šuma. To počne že od leta 1998, ko je stran postavil dublinski Trinity College, in do danes so ustvarili že 1,12 bilijona naključnih bitov podatkov oziroma entropije.
Zmuzljiva naključnost
Definicija naključnosti (random) ni preprosta. V računalniškem smislu to pomeni, da poznamo verjetnost, da se posamezna vrednost pojavi, nikakor pa je ne moremo vnaprej napovedati, ker ni vzorca pojavljanja. V realnosti je najbolj znan zgled radioaktivni razpad atomov, ki ga ne moremo napovedati. Met kovanca pa je naključen samo zato, ker je rezultat tako občutljiv za začetne razmere, da ga ne znamo napovedati.
Naključnost merimo z entropijo, ki podaja količino informacije v nizu podatkov. Kadar je entropija največja, je niz povsem naključen, kar mimogrede pomeni tudi, da ga ne moremo stisniti. Žal ni metode, ki bi nam povedala, ali je niz res povsem naključen. Če gledate sredino zaporedja cifer števila pi in tega ne veste, je to za vas naključnost. V resnici pa jih lahko enostavno računamo in napovemo.

RNG domače izdelave, ki z optičnim tipalom meri padanje zrn peska skozi grlo peščene ure. Ko pesek izteče, elektromotorček uro obrne.

Geigerjev števec, ki ga priključimo na računalnik. V normalnem okolju nameri 25 zadetkov na minuto, ki generirajo naključne bite.
Psevdonaključna števila
Kadar od izbire ni odvisna prihodnost države, se zadovoljimo s psevdonaključnimi števili. Ta v resnici niso popolnoma naključna, so pa za zunanjega opazovalca, ker se vsa pojavljajo s predpisano verjetnostjo brez prepoznavnega vzorca (temu pravimo statistična naključnost), torej ne moremo napovedati, katero bo sledilo. To se v praksi izvede z neko funkcijo, ki iz danega semena (seed) računa psevdonaključna števila. Če poznamo funkcijo in seme, seveda lahko napovemo, katera števila bodo sledila. Četudi funkcijo poznamo, je v marsikaterem primeru dovolj, da ima tako dolgo periodo, da se zaporedje števil ne začne ponavljati, dokler jo kličemo, in da so števila statistično naključna. Recimo pri enakomernem vzorčenju, nekaterih vrstah šifriranja ali uporabi metode Monte Carlo to popolnoma zadostuje, četudi je funkcija znana.
V praksi tak način tvorjenja naključnih števil uporabljajo številni programski jeziki, v katerih programiramo, ter komercialni programi in operacijski sistemi. Enega prvih takih algoritmov je pokazal John von Neumann (odkrit je bil sicer že v 13. st.). Vzel je poljubno n-mestno število (seme), ga kvadriral in iz rezultata vzel srednjih n cifer, ki so predstavljale psevdonaključno število in začetno vrednost za naslednjo iteracijo. Tak postopek ima številne pomanjkljivosti, saj ima majhno periodo in se mnogokrat „zacikla“ ali izteče v same ničle, a ponazori osnovno zamisel tvorbe naključnih števil.
Algoritmi za psevdonaključna števila največkrat vračajo rezultate enakomerno z intervala [0,1]. To zadostuje, saj jih lahko z osnovnimi matematičnimi operacijami raztegnemo in premaknemo v druge intervale ter ustrezno spremenimo porazdelitev (v Gaussovo, Studentovo, Poissonovo in druge).
Preizkušanje naključnosti
Pri uporabi vsakega novega generatorja naključnih števil moramo preveriti, ali so ta res naključna. Pričakovali bi, da bo to preprosto, a se izkaže za nerešljiv problem. Nemogoče je dokazati, da je neko zaporedje števil nastalo z naključnim procesom, lahko pa se temu precej približamo.
Dobiti moramo čim več nizov števil, ki jih je generator ustvaril. Potem jih podvržemo številnih statističnim testom in, če jih prestanejo, lahko generator razglasimo z visoko verjetnostjo kot dober.
Naključna števila so nehvaležna prav zato, ker so naključna. Če bodo vsa zaporedja uspešno prestala vse teste, moramo biti v resnici sumničavi, da nekaj ni prav. Od prave naključnosti namreč pričakujemo, da bomo lokalno našli vzorce, ki niso videti naključni, zato bodo tudi nekateri testi nekajkrat neuspešni.
Precej strog nabor testov se imenuje Diehard in ga je leta 1995 razvil ameriški matematik George Marsaglia. Še strožji je nabor TestU01, ki vsebuje več kot sto različnih testov za generatorje naključnih števil. Če jih prestanejo z ustrezno verjetnostjo, lahko skoraj zagotovo trdimo, da je algoritem brezhiben.
Seme
Seme je poleg algoritma druga bistvena sestavina generatorja psevdonaključnih števil. Glede na dimenzionalnost problema je lahko seme število ali pa vektor. V resnici sploh ni nujno, da je seme resnično naključno število, saj bo katerokoli seme dobro opravilo svojo nalogo. Poznavanje semena in algoritma nam omogoča, da poustvarimo celotno zaporedje števil, kar je v nekaterih primerih celo zaželeno. Pri programiranju programov, ki upravljajo naključna števila, med programiranjem uporabljamo isto seme, da je obnašanje ponovljivo. To olajša iskanje hroščev.
Ko pa želimo različna zaporedja psevdonaključnih števil, bomo seveda potrebovali različna semena. Ker ljudje nismo prav posebej sposobni pri izmišljanju naključnih števil in ker jih računalniki ne morejo naračunati, uporabimo neki zunanji dogodek. Kot seme zato mnogokrat uporabljamo lokalni čas v milisekundah, lokalno temperaturo, ping do kakšnega internetnega strežnika, količino prostega pomnilnika ali zasedenost procesorja, omrežno aktivnost, gibanje miške, čas med pritiski tipk na tipkovnici itn. Vsi ti dogodki so z našega vidika dovolj naključni, da jih smemo uporabiti za seme, saj so nenapovedljivi (ne pa nujno neponovljivi!).
Semena so pomembna tudi pri izdelavi šifrirnih ključev, kjer pa morajo biti čim bolj naključna, zato na primer TrueCrypt pri izdelavi ključa zahteva čim več naključnega premikanja miške po zaslonu.

RNGji za osebni računalnik, ki vzorčijo entropijo okolice za tvorjenje naključnih števil, so lahko v obliki razširitvenih kartic.
Preveč različnosti je sumljivo
Če bi generator naključnih števil proizvajal sama različna števila, to ne bi bila naključna števila. Verjetnost izbire števila v nekem koraku je povsem neodvisna od preteklih dogodkov, zato se števila na dolgi rok morajo ponavljati. Prav tako je nujno, da vsak naključni niz števil vsebuje lokalna podzaporedja, ki imajo vzorec, ker so ta prav enako verjetna kakor zaporedja brez vzorca.
Strojni generatorji naključnih števil
Kadar psevdonaključna števila ne zadoščajo, potrebujemo strojne generatorje naključnih števil (RNG). Načeloma bi lahko opazovali kakršenkoli makroskopski proces, ki ga zaradi množice vplivov ne moremo natančno opisati in predvideti (recimo met kovanca, igralne kocke, vrtenje kolesa na ruleti), a to ni preveč praktično. Strojni RNGji zato merijo kak mikroskopski dogodek. Značilen zgled je meritev radioaktivnega razpada z Geigerjevim števcem, v praksi pa merimo tudi elektronski šum, potovanje fotonov skozi polprepustno zrcalo, termični šum, atmosferski šum, merjenje plazu pri Zenerjevi diodi ipd.
Zelo enostaven in precej dober način izrablja frekvenco različnih oscilatorjev, čemur pravimo tudi lezenje ure (clock drift). Če imamo dva oscilatorja z bistveno različnima frekvencama, počasnejšega krmilimo s termičnim šumom. S tem mu malenkostno spreminjamo frekvenco. Po vsakem nihaju počasnega oscilatorja pogledamo, ali je hitrejši oscilator napravil liho ali sodo število nihajev, od tod dobimo naključen bit 0 ali 1. Tako dobljena števila sicer potrebujejo še dodatno obdelavo, ki ji pravimo dekorelacija, a načeloma je to vse.
Procesorji VIA C3 imajo od leta 2003 vgrajen RNG, ki deluje podobno, le da uporablja štiri oscilatorje. Tudi Intelovi procesorji imajo od leta 1999 vgrajen podoben analogen RNG, ki ustvari nekaj sto kilobitov entropije na sekundo. Arhitektura Ivy Bridge pa prinaša digitalni RNG (glej sliko), ki je bistveno hitrejši (3 Gb/s).
Vrste psevdonaključnih generatorjev števil (PRNG)
Najpogosteje uporabljeni PRNG se imenuje linearni kongruenčni generator (LCG) in ga najdemo v večini programskih jezikov kot privzeti algoritem, ki ga kliče funkcija rand(). Algoritem je preprost, hiter in računsko nezahteven, saj deluje takole: za seme vzamemo število X0 in ga pomnožimo s faktorjem a, prištejemo inkrement c in poiščemo ostanek pri deljenju z m, ki mu rečemo X1. Navadno je m neka potenca števila 2, največkrat 231 ali 232, a in c pa sta vnaprej določeni konstanti. Izbiramo lahko le seme.
Xi+1 ≡ (aXi+c) mod m
LCG ima nekaj pomanjkljivosti, med katerimi je najočitnejša zaporedna korelacija med vrnjenimi vrednostmi, zato ni primeren za uporabo pri šifriranju ali metodi Monte Carlo. V te namene uporabljamo Mersenne Twister. Slednji je privzet algoritem v jezikih python, ruby, R, PHP in mathlab, odlikujeta pa ga bistveno daljša perioda (219937-1) in boljša statistika.
Poleg teh najbolj znanih PRNGjev so še številne druge izvedbe, ki so prilagojene specifičnim platformam, potrebam in omejitvam. Posebna vrsta se imenuje CSPRNG (kriptografsko varni PRNGji), ki morajo izpolnjevati še strožje pogoje glede predvidljivosti in naključnosti, da so primerni za uporabo pri šifriranju. Taka primera sta Yarrow (rman po slovensko) in Fortuna.
Čemu vse to?
Za zapletanje z naključnimi števili so zelo dobri razlogi. Najočitnejši je šifriranje, saj so naključna števila nujno potreba za tvorjenje ključev. Če lahko napadalec napove ta števila, potem lahko ustvari kopijo ključa. To ni zgolj teoretična nevarnost, saj so septembra odkrili namerno ranljivost na enem izmed štirih algoritmov za tvorjenje psevdonaključnih števil, ki jih je ameriška NSA standardizirala v letih 2004–2005.
Pasti slabih generatorjev je že leta 1995 izkusil Netscape, ki je psevdonaključna števila v brskalniku za vzpostavitev varne povezave SSL ustvaril iz treh semen (časa, ID procesa, ID starševskega procesa). Ker so bila dolga le 40 bitov, so hekerji v 30 urah preiskali vse možnost kombinacije in jih zlomili.
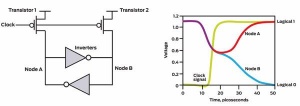
»Digitalni RNG v Intelovih procesorjih Ivy Bridge. Vključitev tranzistorjev prisili inverterja, da imata v točkah A in B enako stanje. Po izključitvi tranzistorjev se to metastabilno zaradi termičnega šuma hitro poruši, tako da je stanje inverterjev nasprotno (0 in 1 ali 1 in 0). Tako lahko v vsakem ciklu pridobimo en naključni bit.«
Uporaba slabih generatorjev naključnih števil je škodljiva tudi v znanosti. Metode Monte Carlo temeljijo na tvorjenju naključnih števil, ki jih uporabljamo za izračun večdimenzionalnih integralov ali poganjanje molekulskih simulacij. S slabimi naključnimi števili bodo rezultati napačni, pa tega sploh ne bomo vedeli.
Vse to so razlogi, da je priprava naključnih števil težak in pomemben problem, v rešitev katerega se investirajo milijoni.