Google, kaj tu piše?
Strojno učenje je z rastjo količine podatkov, ki bi jih bilo koristno analizirati, in čedalje zmogljivejšimi računalniškimi sistemi z miz raziskovalnih inštitutov prispelo v gospodarstvo. Pri tem mu obilno pomagajo tehnološki velikani, ki so pripravili vrsto bolj in manj specializiranih orodij za različne uporabe pridobitev strojnega učenja. Google Natural Language API je namenjen analizi naravnega besedila.
Google je konec julija javnosti odprl (sicer še v beta različici) programski vmesnik oziroma API za analizo besedila. Google Natural Language API se pridružuje vrsti programskih vmesnikov, ki jih Google že ponuja in nam dobesedno iz naslanjača omogočajo uporabo izpopolnjenih modelov strojnega učenja in Googlove zmogljive strojne opreme. Taki so Google Cloud Vision za prepoznavo slik, Google Cloud Speech za prepoznavanje govora in zapis po nareku in Cloud Translation za prevajanje med različnimi jeziki.
Strojno učenje je namenjeno reševanju najrazličnejših vrst problemov, a moramo za vsako vrsto svoj model izuriti s primerno metodo (nadzorovano učenje, nenadzorovano učenje, delno nadzorovano učenje, učenje z okrepitvijo) in naborom vadbenih podatkov. Prepoznavanje govora, analiza besedil, prepoznava slik in podobno so dovolj široko razširjeni problemi, da nima smisla odkrivati tople vode, temveč je bolje, laže in učinkoviteje uporabiti že pripravljene modele, ki jih ponuja Google kot APIje. Google jih je namreč že preveril na milijardah vhodnih podatkov, obenem pa se z vsako rabo urjenje še nadaljuje, model pa s tem izboljšuje. Za posebne primere pa seveda tako Google kot konkurenca ponujajo platforme za gradnjo lastnih modelov, npr. Google Prediction API, Watson Analytics, Amazon Machine Learning ali Azure Machine Learning.
Google Natural Language API zmore analize treh vrst: prepoznavanje ključnih besed (entity recognition), analizo sentimenta (sentiment analysis) in analizo skladnje (syntax analysis). Prva točka pomeni, da s strojnim učenjem iz besedila izluščimo podatke o osebah, organizacijah, krajih, izdelkih, skratka pomenske informacije, ki bi jih slovenisti poimenovali osebki, predmeti in prislovna določila. Skupaj s temi ključnimi besedami izpiše še razvrstitev (oseba, kraj itd.), poudarjenost (salience) in priloži neposredno povezavo na spletno stran z več informacijami, navadno Wikipedijo. Vse to izjemno olajša delo agencijam, ki za stranke pripravljajo izrezke iz medijev po ključnih besedah.
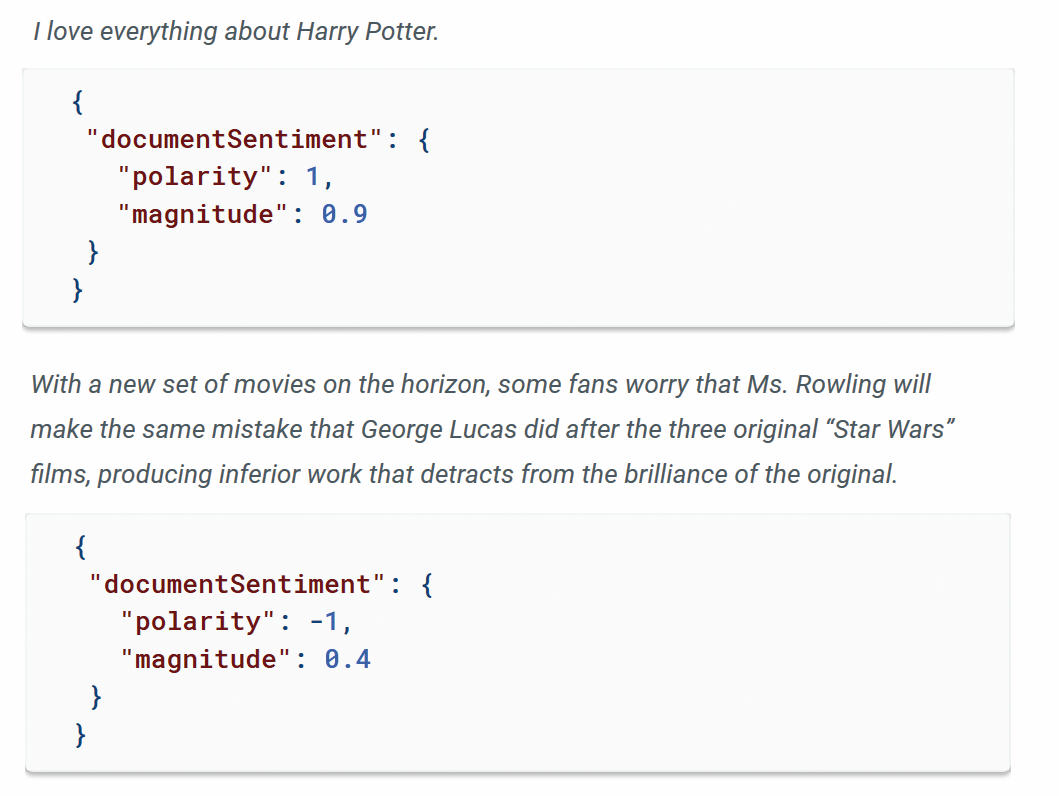
Analiza sentimenta vrne informacijo o splošnem tonu besedila, torej ali je napisano pozitivno ali negativno. Sentiment je podan kot dvodimenzionalni vektor, kjer je prva komponenta normalizirana na vrednosti od –1 do +1, druga pa od 0 do neskončno. Prva komponenta podaja polarnost in ima vrednost +1 za absolutno pozitiven stavek in –1 za negativnega, druga komponenta pa se imenuje magnituda in ponazarja jakost tega občutja. Na splošno velja, da je magnituda odvisna od povprečne čustvene nabitosti uporabljenih kvalifikatorskih besed (love, adore, like, fond, keen …), polarnost pa od razmerja med pozitivnimi in negativnimi.
Analiza skladnje, ki seveda ni uporabna zgolj za jezikoslovce, v besedilu prepozna stavčne člene in generira drevesno predstavitev skladnje (parse tree), iz katere se razbere skladenjska struktura stavka. Če na primer analiziramo angleški stavek »The dog bites a man«, ugotovimo, da je sestavljen iz osebka in povedka. Osebek sestavljata določni člen the in samostalnik dog, povedek pa glagol bites in predmet, ki se razčleni na nedoločni člen a in samostalnik man. Analiza skladnje je pomembna, ker se v njej skrivajo fine pomenske informacije, ki jih iz prepoznavanja ključnih besed ni mogoče razbrati. To je tudi najbolj inovativen oziroma dodelan del Googlove storitve (glej spodaj). Če ima Noah Chomsky prav, je slovnica univerzalna (in človeku vrojena), zato tega dela ne bo težko prenesti na druge jezike. Dejansko so si skladenjska drevesa indoevropskih jezikov podobna.
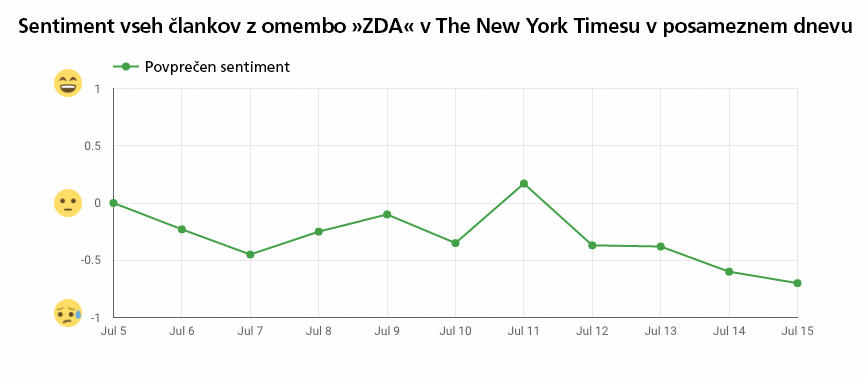
Žal Google Natural Language za zdaj razume le angleško, špansko in japonsko. Kot je tudi Google Translate API počasi dobival podporo za nove jezike, lahko pričakujemo nekaj podobnega tudi pri Google Natural Language. Google je deset dni preizkusno analiziral vse članke v The New York Timesu, ki vsebujejo izraz ZDA, in ugotovil, da je na običajen dan prevladujoč ton teh člankov v povprečju negativen. Ko se bo naučil slovensko, bo zanimivo podobno analizirati slovenske časnike. Tako bomo dobili objektivno meritev, kdo piše predvsem o negativnih zgodbah in kdo v glavnem o pozitivnih.
Google Natural Language je nova Googlova storitev, niso pa se tega v Mountain Viewu seveda domislili prvi. IBM že nekaj časa ponuja podobno storitev, in sicer več APIjev, ki so iz besedila sposobni narediti izvleček, analizirati osebnost pisca, določiti podton sporočila (podobno kot Googlov sentiment), izluščiti ključne pojme itd. Poleg velikih se s tem ukvarjajo tudi nišni specialisti, denimo Aylien, MeaningCloud, Lexalytics in številni drugi. Seveda pa sta Googlov glavni adut velikost in ugled. Privošči si lahko najboljšo strojno opremo, ima največ vhodnih podatkov in vsakdo ga pozna. V poslu pa to nemalo šteje. Glede cen pa – niti beta različica ni povsem brezplačna – pokukajte v spodnjo tabelo.