Unicode - En standard za en svet
Dandanes je samoumevno, da lahko z računalniki brez težav zapisujemo besedila v vseh jezikih in pisavah, najsi gre za slovenske šumnike ali kitajske pismenke. Sistem, ki danes kodira več kot sto tisoč različnih simbolov, je zanimiva kombinacija domiselnosti s preudarnim načrtovanjem na eni strani in zgodovinske navlake na drugi. To so tudi razlogi, da med znaki najdemo kakec, lebdečega moža in nerazvozlano pisavo Minojcev.
Zgodovinsko naključje je hotelo, da se je razvoj modernih računalnikov najhitreje odvijal v angleško govorečih državah. Tam brez težav shajajo s 26 črkami latinice, ne da bi potrebovali naglasna znamenja ali specialne črke. In tako so prvi računalniki podpirali teh 26 črk in še nekaj posebnih znakov. A zamisel je v resnici precej starejša.
Kodiranje znakov v obliki, ki je primerna za digitalni prenos, sega v čas električnega telegrafa, v prvo polovico 19. stoletja. Besedo digitalni kod uporabljamo v prvobitnem pomenu besede, torej kot prenos, kjer imamo na voljo dve stanji. V modernih računalnikih so to konceptualno ničle ali enice, v Morsejevi abecedi pa dolgi in kratki signali. In prav eden izmed izumiteljev telegrafa Samuel Morse se je leta 1835 domislil prvega širše uporabnega načina za kodiranje znakov v digitalni obliki. Sprva je sicer na tak način zapisal le števke, a je njegov kolega Alfred Vail leta 1840 Morsejevi abecedi dodal še črke in nekaj ločil.
Z današnjo Morsejevo abecedo lahko zapišemo tudi nekaj posebnih znakov z naglasnimi znamenji, vrsto ločil ter nekaj drugih kontrolnih sekvenc. Čeprav telegrafov že zdavnaj ne uporabljamo več, je več kot poldrugo desetletje pozneje še vedno marsikje uporabna. Radioamaterji in vojska je uradno ne uporabljajo več, a jo marsikje še vedno poznajo.

Morsejeva abeceda je bila eden prvih načinov kodiranja znakov.
Morsejeva abeceda strogo vzeto nima zgolj dveh stanj (črtica in pika oziroma dolgo in kratko), saj ima tudi premore treh različnih dolžin, ki nastopajo med črkami, besedami in stavki. Ker obstajajo te ločnice, so posamezne enote (črke) lahko različno dolge. Tak način kodiranja znakov je varčnejši, še posebej ker imajo najkrajši zapisi prav najpogostejše črke, in ljudem tudi prijaznejši. Črka E je en kratek signal, redkejši Q pa ima štiri signale. Za implementacijo v svetu računalnikov pa bi to predstavljajo dodaten ovinek.
Ko je bil slovenski jezik izziv
V 90. letih preteklega stoletja je bil zapis slovenskih krilatih znakov velik problem. Najbolj znani nabori za kodiranje slovenskega besedila so bili YUSCII, CP852, CP1250, ISO-8859-2 (Latin 2) in kasneje Unicode. Operacijski sistemi niso bili poenoteni, zato je prenos datotek z DOS na Linux ponavadi poskrbel za izgubo slovenskih znakov. Izgube so se dogajale tudi pri tiskanju in skoraj vsakem prenosu med sistemi.
Microsoft je za slovenske znake poskrbel januarja 1991, ko je beta verzija DOS 5 ponudila izbiro jugoslovanskega znakovnega nabora. V tem primeru je uporabil kodno tabelo CP852. Tedanja konkurenca OS/2 je CP852 podprl februarja 1991 v OS/2 2.0 (pre-release 6.123). Precej bolj zamudno je iskanje izvora te kodne tabele, saj IBM na svojih spletnih straneh trdi, da je bil CP852 registriran leta – 1993. Zdi se, da nikomur ni zares jasno, kako in zakaj je CP852 videti tako, kot je.
Drugi kodni nabor za zapis slovenskih znakov je ISO-8859-2, ki je bil standardiziran davnega leta 1987 kot ECMA-94 (Latin Alphabet No.2). Tega je uporabljal zlasti Unix. A Windows je raje uporabljal novo Microsoftovo iznajdbo Windows-1250 (CP1250), ki ni bila kompatibilna s CP852 ali z ISO-8859-2. Prvikrat jo je uvedel v Windows 3.1 za srednjo in vzhodno Evropo. Danes vsi ti operacijski uporabljajo Unicode.
V zgodnji dobi interneta ni bilo samoumevno, da bodo spletne strani povsod videti berljive. Kdor ni pravilno nastavil kodne tabele, je imel med besedilom razmetane nenavadne krace. Problem se je uredil, ko je prispel Unicode.
Tale okvir bi sicer brezhibno zmogli prikazati vedno, ker vsebuje zgolj osnovne znake iz latinice, brez krilatih znakov. Preberite ga ponovno. Kljub temu, da zato vsebuje tudi nekatere nenavadne besede ;).
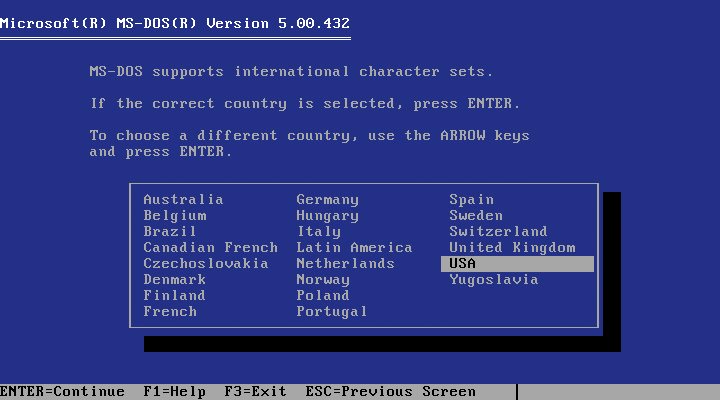
DOS je že leta 1991 ponujal šumnike.
Čeprav se zdi, da se računalniška zgodovina kodiranja znakov začne s standardom ASCII, ga prvi podobni poskusi prehitevajo za skoraj sto let. Émile Baudot je že v 70. letih 19. stoletja postavil način za kodiranje znakov, ki se imenuje Baudotov kod (ali ITA1). Uporabljal se je na teleprinterjih, vsaka črka pa je bila kodirana s petimi biti. Črka A bi bila 10000, črka B 00110 itd. Leta 1924 ga je zamenjal ITA2 (International Telegraph Alphabet 2), ki s staro različico ni bil združljiv. Še vedno pa je uporabljal pet bitov za zapis posameznega znaka. Hitro lahko izračunamo, da lahko na tak način zapišemo največ 32 znakov (25), kar ne zadostuje niti za celotno abecedo in števke od 0 do 9. Rešitev tega problema je analogna tipki Shift na tipkovnici. S posebnim znakom Shift to Figures (11011) se pomaknemo na drugi nivo, kjer so na voljo števke, ločila in posebni znaki, nato pa s Shift to Letters (11111) ponovno nazaj. Kljub svoji primitivnosti se je ITA2 obdržal vse do danes, ko se še vedno uporablja tam, kjer je izjemno pomembna dolžina zapisa.
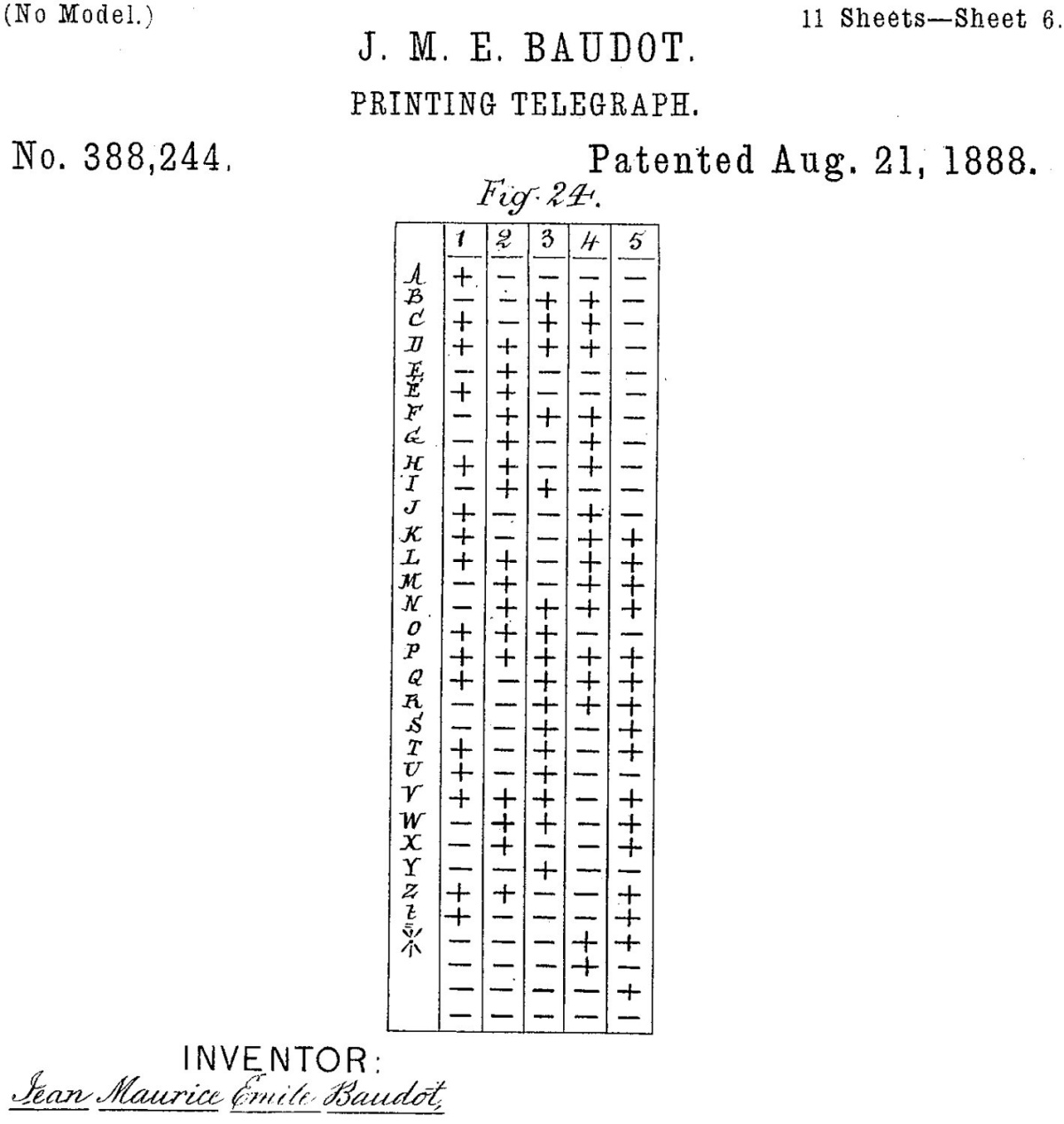
Baudotov kod iz konca 19. stoletja se je uporabljal tudi na teleprinterjih.
ASCII
Revolucijo pa je povzročil standard ASCII (American Standard Code for Information Interchange), ki je za zapis znaka uporabljal sedem bitov, kar omogoča 128 znakov. Leta 1963 postavljeni standard je v prvih letih sicer doživel nekaj popravkov, a je že več kot pol stoletja nespremenljiv način berljivega zapisovanja znakov brez oblikovanja. Vsebuje 32 kontrolnih znakov, ki so bili svoj čas namenjeni posredovanju ukazom tiskalnikom, teleprinterjem in pisalnim strojem (npr. pojdi v novo vrstico, premakni se nazaj). Preostali znaki pa so izpisljivi in vključujejo velike ter male tiskane črke angleške abecede, števila od 0 do 9 in osnovna ločila.
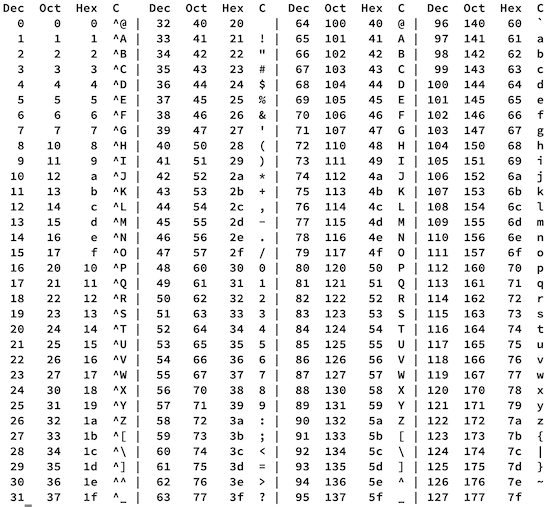
Osnovni ASCII vsebuje 128 znakov, ki zadostujejo za enostavna angleška besedila.
ASCII ima precej elegantnih rešitev, ki olajšajo delo z znaki. Računalniki namreč operirajo s številkami, v resnici zgolj ničlami in enicami, zato je koristno tudi črke in druge znake predstavljati na način, ki omogoča enostavne manipulacije. Enotna dolžina (7 bitov) omogoča enostavno štetje znakov. Vsakih sedem bitov se začne novi.
Številke se začnejo pri 011 0000 (ničla) in tečejo do 011 1001 (devetica), torej zadostuje porezati prve tri pa imamo vrednost v bitih. Velike tiskane črke se začnejo pri 100 0001 (A) in tečejo do 101 1010 (Z), male tiskane pa od 110 0001 (a) do 111 1010 (z). To pomeni, da lahko med njima pretvarjamo preprosto tako, da bitom prištejemo ali odštejemo 32, torej obrnemo drugi bit.
Da je ASCII nadomestil ITA2, je poskrbel kar ameriški predsednik Lyndon B. Johnson, ki je leta 1968 odredil, da ga morajo podpirati vsi novi računalniki v zvezni vladi. In tako je ostalo zelo dolga časa. Ne le da ASCII še danes razume vsak računalnik – resda ga vsi ne uporabljajo aktivno –, na internetu je bila do leta 2007 najpogostejša tabela za kodiranje prav ASCII. Nasledila ga je implementacija Unicoda UTF-8, ki je nazaj združljiva z ASCII.
ASCII je bil omejen na angleške črke, saj so si ga zamislili kot enega izmed več nacionalnih standardov za zapis znakov. IANA (Internet Assigned Numbers Authority) ga še danes imenuje US-ASCII, v Jugoslaviji pa je obstajal standard YUSCII, ki je bil v glavnem enak, je pa vseboval tudi črke č, ć, đ, š in ž. Za njihovo uporabo smo se morali odreči nekaterim posebnim znakom: [, \, ], ^, {, |, } in ~. Ker je v YUSCII črka Đ na istem mestu kakor \ v ASCII, smo v prvih različicah Microsoftovega ukaznega poziva v lokaliziranih Windows namesto C:\> videli zapis C:Đ>. Lokalizacij je bilo cel kup, saj so Britanci dodali simbol za funt, Nemci preglašene črke (ä ö ü) itd. Vsak je torej uporabljal svoj način zapisovanja znakov.
Zakaj je med znaki tudi smejoči kakec
V današnjem svetu z največjim veseljem uporabljamo majhne piktograme, ki so od začetnih smeškov prerasli v najrazličnejše podobe, od zastav držav do lebdečega moža v obleki in seveda smejočega kakca. Da so se znašli v univerzalnem naboru znakov, je krivo zgodovinsko naključje, ki izvira iz Japonske.
Konec 90. let, ko je zahodni svet uporabljal še različne izpeljanke ASCII, so na Japonskem za pošiljanje kratkih sporočil uporabljali svoje standarde. Operater NTT DoCoMo je ponujal sistem i-mode, v katerega je leta 1999 inženir Shigetaka Kurita dodal 176 piktogramov. Japonci so si lahko kot besedilo pošiljali emojije.
Za to japonsko posebnost v tujini ni vedel skoraj nihče, dokler ni konzorcij Unicode želel dodati japonskih znakov v svoj znakovni nabor. Emojije so po začetni razpravi v standard dodali, ker je cilj standarda Unicode pretvorljivost besedil v obe smeri, torej v Unicode in nazaj.
Apple jih je integriral v iPhone 2, a le za uporabnike z japonskimi karticami SIM, zato tega spet ni opazil skorajda nihče. Ko pa je v iPhone 4 odklenil emojije za vse uporabnike in dodal posebno navidezno tipkovnico za njihov vnos, je popularnost eksplodirala. Ljudje so ugotovili, da si lahko pošiljajo kakce, srčke in podobno. Zgledu so morali slediti tudi drugi ponudniki telefonov, če so želeli omogočiti normalno komuniciranje z uporabniki iphonov. Ostalo je zgodovina. Svet se je zaljubil v emojije, konzorcij Unicode jih je dokončno ponotranjil in z vsako novo različico jih je v standardu več.
Danes Unicode vključuje celoten nabor znakov iz pisav Wingdings in Webdings, japonske emojije, Zapfov Dingbats itd. V Unicodu 14.0 je že več kot 6.000 emojijev in nič ne kaže, da se bo rast ustavila. Želeli smo imeti enotni standard za zapisovanje vseh jezikov sveta, dobili pa smo kakce. Ljudje si pač radi pošiljamo sličice.

V Unicodu je tudi cel kup sličic – emoji.
Po pričakovanjih je bil rezultat zmeda. Črke angleške besede so bile povsod na istih mestih, nove črke pa so nadomeščale manj pogosta ločila. To je povzročalo težave pri programiranju, kjer so imeli posebni znaki (npr. { in }) zelo jasno opredeljene funkcije, neameriške različice standarda pa jih včasih sploh niso imele. Programski jezik C zato še danes dopušča tričrkovne zamenjave zanje, na primer ??( in ??) za { in }, čeprav težav še zdavnaj ni več. ASCII je potem nasledil 7-bitni standard ISO/IEC 646, ki je tudi obstajal v kopici nacionalnih različic.
Ko so v 70. letih standardizirali opremo za uporabo osmih bitov kot bajt, je tudi kodiranje ASCII dobilo osmi bit. Razširjeni ASCII je zmogel zapisati 256 znakov, kar je bilo še vedno premalo za zapis vseh evropskih jezikov, kaj šele za kaj bolj ambicioznega. Spet smo dobili vrsto standardov za kodiranje, ki so bili slabo združljivi. Naposled je ISO izdal standarde ISO 8859-1 za zahodnoevropske jezike, ISO 8859-2 za srednjeevropske jezike in tako naprej do ISO 8859-16. Za slovenščino je (bil) uporaben ISO 8859-2 (več v okvirju). Sicer je bilo mogoče zapisovati vse znake evropskih jezikov, če smo uporabili pravo tabelo, a ne v istem besedilu. Potrebovali smo enotno rešitev.
Unicode
Različnih naborov je bilo še precej več, kot nam jih je tu uspelo omeniti, vsem pa je bila skupna omejenost. Kakorkoli obračamo osem bitov, je 256 znakov premalo, da bi imeli res univerzalen nabor. Že konec 80. let je bilo jasno, da tako ne bo šlo. Razširjanja nabora se je bilo treba lotiti premišljeno, da bi imeli enoten univerzalen način kodiranja znakov. Problema so se prvi lotili Joe Becker (Xerox), Lee Collins in Mark Davis (Apple). Becker je že leta 1988 objavil predlog za standard, ki bi omogočal zapis bistveno več znakov. Trdil je, da je 16-bitno kodiranje znakov v 32-bitnih računalnikih že dejstvo, ki si ga moramo le še priznati. Xerox je bil že več let razvijal različne večjezikovne računalniške sisteme, ki podpirajo vse latinične abecede, poleg tega pa še arabsko, armensko, bolgarsko, kitajsko, gruzinsko, grško, hebrejsko, japonsko, korejsko, perzijsko, rusko, ukrajinsko itd. Že leta 1982 so v Xeroxu vzpostavili interni standard XCCS (Xerox Character Code Standard), Unicode pa je bil njegova izboljšava.
Pravzaprav predstavlja vzpostavitev standarda Unicode pravi mali čudež, saj so se vsi tehnološki velikani, ki v poslu kaj štejejo, usedli za isto mizo, pripravili en standard in se ga še vedno tudi držijo. Polne glasovalne pravice v konzorciju imajo trenutno Adobe, Apple, Emoji ID, Facebook, Google, ETCO, Microsoft, Netflix, SAP in Salesforce, pridruženih članov pa je še več.
Varnostni pomisleki
V Unicodu so tudi znaki, ki so videti povsem identični, čeprav imajo različne kode in so torej za računalnik različni. Imenujejo se homoglifi (homoglyphs). Tak primer sta latinični in cirilični a. Prvi ima kodo 65, drugi 1072. To lahko predstavlja varnostno tveganje, če uporabniku podtaknemo povezavo, ki je videti kot legitimna domena, a v resnici vsebuje lažno domeno, ki jo je registriral napadalec.
Standard Unicode je širši od kodiranja znakov, saj vsebuje pravila za konsistentno kodiranje znakov, njihovo predstavitev in pravila za prikaz (vključno z razvrščanjem in dvosmernim besedilom) itd. Če zelo poenostavimo, pa je Unicode priredil vsem mogočim znakom, ki bi jih lahko kadarkoli potrebovali, svoje kode. Te pa lahko zapišemo različno, saj v nasprotju s pogostim prepričanjem Unicode določa in omogoča več načinov kodiranja (UTF-8, UTF-16, UTF-32 in še številne starejše).
Unicode je rešil več težav: v istem besedilu lahko zapisuje vse znake, ki karkoli pomenijo v katerikoli pisavi – vsebuje celo še nerazvozlano linearno pisavo A iz antične Grčije –, in omogoča enolično pretvarjanje. Od različice 1.0, ki je oktobra 1991 podpirala dobrih sedem tisoč znakov, je Unicode pripotoval do 14.0 s podporo za več kot 144.000 znakov v praktično vseh znanih sistemih zapisovanja. Ob tem pa še vedno vsebuje istih 32 neizpisljivih kontrolnih znakov, ki se vlečejo še iz časov teleprompterjev oziroma pisalnih strojev (npr. CR oz. carriage return).
Kako deluje
Za zdaj ni bojazni, da bi Unicodu zmanjkalo prostora. Standard ima za zapis koristnih informacij na voljo 21 bitov, v katere je zaradi nekaterih omejitev standarda moč stlačiti 1.114.112 znakov. Trenutno ni uporabljenih niti šestina. Če zelo poenostavimo, Unicode vsem mogočim znakom zgolj priredi zaporedno število od 0 do 10FFFF, kar ustreza 21-bitnemu prostoru. Resnica je še nekoliko kompleksnejša, saj znaki, ki jih uporabnik vidi, niso nujno enaki vrednostim (code point), s katerimi so zapisani. Unicode namreč vsebuje te vrednosti (code point), izrisovalniki pa jih potem pretvarjajo v znake, ki jih ljudje vidimo.
Nekatere vrednosti v Unicodu so namreč modifikatorji, ki vplivajo na sosednje znake. Tak primer je zapis emojijev za zastave. Unicode ne vsebuje informacije o posamezni zastavi, temveč omogoča le kodiranje z dvema posebnima regionalnima simboloma, ki v zaporedju izrisovalniku povesta, da gre za zastavo. Slovenijo zapisujeta znaka s kodama 1F1F8 (regionalni S) in 1F1EE (regionalni I). SI, torej. Če zastavo kopirate v urejevalnik besedila, bo ta preštel dva znaka, če bo sploh znal narisati zastavo. Če 1F1F81F1EE vpišete v iskalnik Google, vam bo pokazal/našel, da gre za slovensko zastavo.
A kakorkoli, za namene tega članka si lahko predstavljamo, da ima vsak prikazani znak enolično zaporedno številko. Načinov, kako to zapisati v obliki ničel in enic, pa je več. Zakaj sploh komplicirati? Poglejmo najprej, kako bi zapisali črko A. V Unicodu ima podobno kot v ASCII oznako 65, kar binarno zapišemo kot 01000001. Zakaj to ni dovolj? Če računalnik vidi 01000001 01000001, lahko to interpretira kot AA ali pa znak z zaporedno številko 16705 oziroma 䅁. Kako bo računalnik vedel, ali imamo opraviti z AA ali 䅁?
Oglejmo si, kako se Unicode v praksi kodira. Najpogostejši načini so UTF-8, UTF-16 in UTF-32. Vsi zmorejo isto, se pa razlikujejo v izvedbi. Med njimi je UTF-8 gotovo najpriljubljenejši, saj je na spletu po zadnjih ocenah 98 odstotkov strani zapisanih z UTF-8.
A začnimo pri najenostavnejšem. UTF-32 ne skopari s prostorom, temveč vsak znak zapiše s štirimi bajti (32 biti). Čeprav se zdi to logična odločitev, saj potrebujemo vsaj 21 bitov, računalniki pa se najbolje znajdejo z večkratniki števila 8, je UTF-32 pretiravanje. Črko A (indeks 65) bi zapisal kot 00000000 00000000 00000000 01000001 (v heksadecimalni obliki 0x00000041). Tak zapis ni le potraten, saj imamo kopico odvečnih ničel, temveč tudi nezdružljiv z ASCII in nasploh neprijazen do starejših sistemov, ki se pri osmih zaporednih ničlah pogosto predajo, saj jih razumejo kot znak za konec sporočila (ali znak NULL). Pri zapisu evropskih besedil, ki vsebujejo latinične ali cirilične črke in se nahajajo na začetku tabel Unicode (nizke vrednosti), bodo večino datoteke v resnici predstavljale ničle. Vsaka datoteka bi bila štirikrat daljša kot v zapisu ASCII, četudi bi imela povsem enake informacije. To je potrata.
Zato so izumili UTF-8, ki predstavlja eno najelegantnejših rešitev. Prvih 128 znakov, ki ustrezajo originalnemu ASCII, zapišemo popolnoma enako. Zanje uporabimo osem bitov, torej so v obliki 0xxxxxxx. Besedila, ki vsebujejo le te znake – torej angleščino –, bodo v ASCII in UTF-8 zapisana popolnoma enako. To pomeni, da je vsaka datoteka ASCII veljavna datoteka UTF-8. Razširjeni ASCII, ki ima 256 znakov, pa to že ni več.
UTF-8 nadaljnje znake zapisuje takole. Kar ima indeks nad 128, zahteva več bajtov. Če je prvi bajt 110xxxxx, to označuje, da je znak zapisan z dvema bajtoma. Če je prvi bajt 1110xxxx, potem je znak zapisan s tremi bajti in tako naprej do 1111110x, ki je zapisan s šestimi. Začetne vrednosti v teh prvih bajtih so zaglavja (header). Začetnim bajtom sledijo nadaljevalni bajti oblike 10xxxxxx, ki imajo vsi enako zaglavje 10. Preostale vrednosti (x) so namenjene zapisu znaka. Taka rešitev je genialna iz več razlogov: 1. je združljiva z osnovnim ASCII, 2. porabi približno toliko prostora, kot ga potrebuje, 3. iz zaglavja je moč ugotoviti, kje se začne naslednji znak, 4. nikoli se ne pojavi zaporedje 00000000.
V praksi se A (indeks 65) še vedno zapiše 01000001, Š (indeks 160) pa kot 11000101 10100000. Prvi bajt ima zaglavje 110, torej bosta bajta dva. Drugo zaglavje mora biti 10, ker gre za nadaljevalni bajt. Če odrežemo glavi obeh bajtov, ostane 00101100000, kar je resnično 160. Znak ⥱ (indeks 2971) pa se zapiše kot 11100010 10100101 10110001, kar brez zaglavij dá 0010100101110001 oziroma 2971. Morda se zdi takšen zapis nepotrebno kompliciranje, a njegove pomanjkljivosti se da obvladati. Število bajtov za zapis znaka variira, zato iz pozicije ni mogoče ugotoviti, koliko znakov se je že zvrstilo. Te je treba prešteti od začetka, je pa seveda mogoče enostavno ugotoviti, kje se začne naslednji znak.
Takšen zapis je izjemno praktičen za zapis evropskih jezikov, medtem ko za znake z visokimi indeksi zaradi zaglavij porabi nesorazmerno več prostora. Za azijske jezike UTF-8 v povprečju porabi tri bajte. Zanje je zato primernejši UTF-16, ki uporablja dva bajta ali štiri. V UTF-16 bo večina znakov – tudi azijskih – šla v dva bajta (od 0x0000 do 0xFFFF, torej dobrih 65.000 izpisljivih znakov in še nekaj kontrolnih), kar v odsotnosti posebnih znakov omogoča predpostavko, da to drži vedno. Kadar pa potrebujemo višje znake, se uporabijo nadomestni pari (surrogate pairs). Tak zapis zahteva štiri bajte.
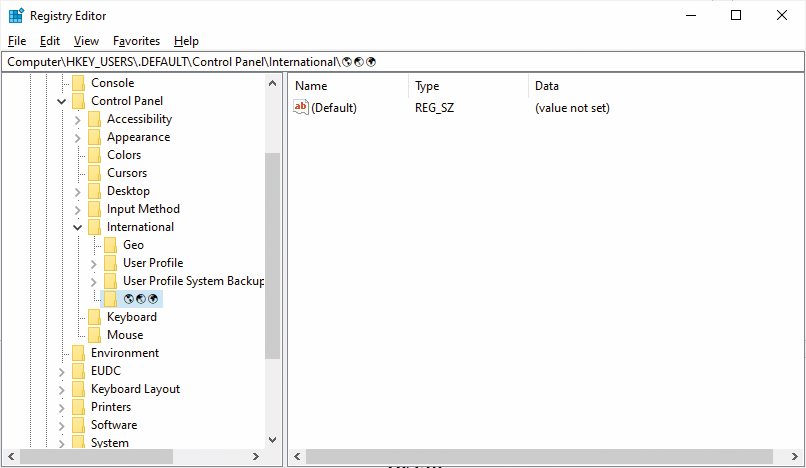
Emoji celo v Windows registru
Ker nove različice Windows uporabljajo Unicode, lahko datotekam dajemo najbolj eksotična imena – in seveda tudi odpiramo datoteke, ki jih prejmemo iz vsega sveta z imeni v različnih pisavah. Vse znake Unicoda lahko uporabljamo tudi v Windows registru, čeprav šariti po njem ni pametna izbira. A celo nekdo v Microsoftu je menil, da bi bilo zabavno uporabiti kakšen emoji za ime registrskega ključa. In tako obstaja ključ HKEY_USERS\.DEFAULT\Control Panel\International\🌎🌏🌍, ki vsebuje tri različne globuse.
Če strnemo, je UTF-8 torej najbolj kompakten in združljiv nazaj, a je manipulacija z nizi težja, ker ne poznamo bitne dolžine znakov. UTF-32 je obraten, saj iz pozicije točno vemo, koliko znakov je pred nami, a porabi največ prostora in se tepe z ASCII. UTF-16 je kompromis, ki ima najboljše ali pa najslabše od obeh svetov, odvisno od vašega življenjskega (in programerskega) nazora. V Windows je UTF-16 privzeta nastavitev, v Linuxu in na spletu pa v glavnem UTF-8, so pa ti standardi že toliko uveljavljeni, da za vse pomembne programske jezike obstajajo zelo dobre knjižnice za manipulacije z nizi in tudi njihovo pretvarjanje.
Kaj Unicode ni
Unicode ni pisava, temveč nabor znakov in širši sklop spremljevalnih pravil. Unicode vsebuje znake (characters), ki so najmanjši simboli za zapis in vsebujejo neko informacijo oziroma pomen. Niso pa v Unicodu zapisana natančna pravila za upodobitev, torej kako se mora izrisati kakšna črka ali znak. To je stvar pisave in je prepuščena izrisovalniku. Sploh v mladih letih Unicoda je bil pogost problem, da spletni brskalniki niso znali prikazati nekaterih znakov, ki so bili v Unicodu. Danes je to problem le še za zelo eksotične, npr. linearno pisavo A (poskusite odpreti: https://en.wikipedia.org/wiki/Linear_A). Tudi emojiji na Applu in Androidu so zato videti zelo drugače, ker jih pač izrisuje drug pogon.
Ker Unicode ni nastal iz nič, temveč je gradil iz obstoječih naborov znakov, vsebuje tudi nekaj nekonsistentnosti. Zaradi tega ima Unicode nenavadna pravila, kaj šteje kot znak. Akcenti na črkah in ligature načelno to niso, razen če so obstajali kot znak že v kakšnem prejšnjem standardu, ki ga je Unicode nasledil, zaobjel in vključil. Pri tem ne mislimo na akcente v jezikoslovnem smislu, temveč na modifikatorje črk.
Črka Š je zato del standarda Unicode, ker ima zgodovino (že v YUSCII je bila!), črka B s strešico pa ni. Če bi jo potrebovali, pa jo lahko vseeno zapišemo, ker Unicode vsebuje samostojna naglasna znamenja, ki se kombinirajo s sosednjim znakom. Znak z indeksom 780 (0x030C) predstavlja strešico, ki jo lahko pripnemo na karkoli (combining caron). Seveda bi lahko na tak način kodirali tudi Š, torej z dvema kodama za S in strešico, a tega ne počnemo. Takšna nekonsistentnost je cena za združljivost, se pa ta ne bo povečevala, saj Unicode ne more dobiti več nobenih novih samostojnih znakov z akcenti ali ligatur. Če se bodo pojavile nove potrebe, jih bodo ustvarili s kombinirajočimi znaki.
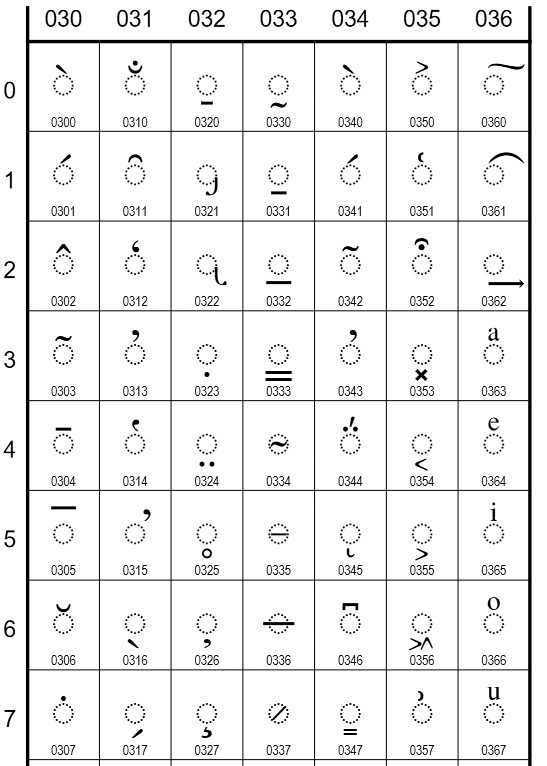
Unicode vsebuje znake, ki se kombinirajo z drugimi in jih modificirajo z akcenti.
Mimogrede, del standarda Unicode je tudi enolično latinično ime za vsak znak, ki se ne sme nikoli spremeniti. V redkih primerih pa je bilo izbrano manj primerno ali napačno poimenovanje, zato ima Unicode tudi aliase, ki predstavljajo alternativni, a še vedno enolični opis znaka. Znak s kodo 0E9F ima enolično ime LAO LETTER FO SUNG, alias pa LAO LETTER FO FAY, ker je prvo ime napačno, a ga ne morejo spremeniti. Drugi razlogi za aliase so okrajšave in poimenovanja kontrolnih znakov.
Unicode je skorajda šolski primer standarda, ki so ga tehnološki velikani ustvarili skupaj – resda na Xeroxovih in Applovih ramenih – in se ga še danes držijo. Standard se je v treh desetletjih obstoja razvijal, a je hkrati ves čas ostajal združljiv nazaj, in to celo s prazgodovinskim ASCII. Kadar je interes, je torej mogoče tudi poenotenje. To seveda ne pomeni, da je Unicode brez težav, saj je pri tako monumentalni nalogi, kot je kodiranje vseh znakov v vseh zemeljskih pisavah, to neizbežno, so pa te sorazmerno redke, omejene na res eksotične jezike, a še te se sproti odpravljajo.