Umetna inteligenca, ki riše in slika
Neredko se zgodi, da po desetletjih zatišja čas nenadoma dozori in več laboratorijev na različnih koncih sveta skoraj istočasno odkrije kakšno iznajdbo. To se je letos zgodilo z modeli za ustvarjanje slik iz besedilnega opisa. Čeprav smo primitivne poskuse videli že v preteklih letih, so letos vsi velikani predstavili svoje prve uporabne primerke. Vodi OpenAI z DALL-E 2, Facebook, Google in drugi pa ne zaostajajo mnogo.

Ko je OpenAI januarja lani predstavil umetno inteligenco DALL-E, ki je bila namenjena ustvarjanju vizualnih podob v najrazličnejših oblikah (ISM – image synthesis model), od imitacij fotografij do dalíjevskih slik, je bil rezultat klavrn. DALL-E, kar je sklop iz besed WALL-E in Dalí (Salvador), je resda ustvarjal grafične podobe, a te bi težko koga preslepile. Pridih umetne inteligence oziroma računalniške stvaritve je močno vel iz vsake podobe, ki tudi niso bile zadovoljive kakovosti za vsebinsko objavo v medijih, kaj šele, da bi jih obesili na steno ali razstavili v galerijah.
Kaj je OpenAI
OpenAI je raziskovalni laboratorij podjetja OpenAI LP, ki je v lasti neprofitne organizacije OpenAI Inc. OpenAI LP so ustanovili kot hibridno obliko med neprofitno organizacijo in profitnim podjetjem, ki je namenjeno ustvarjanju dobička investitorjem, a je ta navzgor omejen. Ob tem ves čas poudarjajo, da je glavno poslanstvo zagotavljanje varne splošne umetne inteligence, ki bo koristila človeštvu. Zaradi tega v upravnem odboru OpenAI LP predstavniki kapitala oziroma investitorjev ne morejo imeti večine, prav tako morajo vedno ostati zvesti osnovnemu poslanstvu in vrednotam.
V preteklosti je v OpenAI sodeloval tudi Elon Musk, a je organizacijo zapustil že februarja 2018. OpenAI je bil sicer ustanovljen leta 2015, ko so moči in več kot milijardo dolarjev združili še Sam Altman, Ilya Sutskever, Greg Brockman, Wojciech Zaremba in John Schulman. Altman je izvršni direktor, Sutskever je direktor raziskav in Brockman strokovni direktor. Ko je Open AI začel delovati, je imel devet raziskovalcev, danes jih ima več kot sto. Med njegove najodmevnejše izdelke sodijo jezikovni model umetne inteligence GPT-3 (in predhodnika), CLIP, Microscope in OpenAI Five.
A umetna inteligenca je eno najhitreje razvijajočih se področij moderne tehnologije, zato ni presenetljivo, da smo letos dobili DALL-E 2. Od julija je bil DALL-E 2 dostopen le milijonu ljudi, ki so se pravočasno vpisali na čakalno vrsto, da so sčasoma dobili povabilo za dostop. Septembra pa je OpenAI ocenil, da je DALL-E 2 dovolj razvit in preizkušen, da ga lahko ponudi vsakomur. Odtlej lahko dostop dobi vsakdo.
Na čakalno vrsto smo se vpisali že avgusta, a nam je OpenAI dostop podelil šele konec septembra ob splošni dostopnosti storitve. Pri registraciji je treba izbrati, v katere namene bomo DALL-E 2 uporabljali, pri čemer prevelika odkritost prej škodi kakor koristi. Če izberemo kot namen uporabe preizkus za novinarske namene, nas stran obvesti, da to ne bo šlo. Preleviti se moramo v fizično osebo, ki umetno inteligenco uporablja doma za neškodljivo igranje.
Prvi vtisi
Za registracijo potrebujemo elektronski naslov in telefonsko številko. A ko smo se poskušali registrirati, smo dobivali vztrajno in nič kaj povedno obvestilo o napaki (Failed to create account. If this issue persists please contact support@openai.com). Ni preostalo drugega kakor potožiti na ponujeni elektronski naslov in šest ur pozneje so iz OpenAI odgovorili, da imajo težave z registracijo novih uporabniških računov. Očitno je bil naval po odprtju storitve res velik. Kot so obljubili, je naslednji dan registracija delovala.
Uporabniški vmesnik DALL-E 2 je preprost in spominja na Google. Na prvi strani je široko okno za vpis, kamor vpišemo čim podrobnejši besedilni opis želene slike. Omejitve so zgolj naša domišljija, saj bo umetna inteligenca iz česarkoli zmogla ustvariti nekaj. Navedemo lahko želene motive, lastnosti in tudi slog, denimo impresionizem, ASCII ali Pac Man. Gumb Surprise Me ima podobno funkcijo kot I'm Feeling Lucky pri Googlu – umetna inteligenca si tedaj sama izmisli opis in nam prikaže rezultat. Pod iskalnim oknom so prikazani primeri, ki so jih generirali drugi uporabniki ali razvijalci storitve. Mimogrede, DALL-E 2 si zapomni tudi vse naše stvaritve, kar je uporabno pri brskanju za nazaj.

Fotografiji urednika do prekrižanih rok smo dodali spodnji del trupa, leve, tarčo, denar in fanta s transparentom.
Rezultati so bili zelo zanimivi. Za vsak opis model ustvari štiri slike, ki so med seboj precej različne. Umetna inteligenca sicer ne ve, kako je videti molekula etanola, zato »an impressionist painting of an ethanol molecule with black background and yellow atoms« izriše neobstoječo molekulo, a sicer je rezultat zelo dober. Črna luknja v van Goghovem slogu je že precej prepričljiva. Najslabše se obnese, kadar zahtevamo ljudi z obrazom. Umetna inteligenca tega tipa še ne zna risati obrazov, ki bi bili dovolj podobni človeškim, da bi bili prijetni. Medtem ko pri vseh ostalih podobah človeški možgani sprejmejo tudi nerealistične posnetke, je pri človeških problem efekt srhljive doline (uncanny valley). Podobe, ki so zelo podobne realističnim, a ne povsem realistične, so videti spačeno, groteskno, neprijetno. Večina obrazov, ki jih ustvari DALL-E 2, je takšnih.
Naredite sami
Medtem ko DALL-E deluje v oblaku, je modele za ustvarjanje slik z latentno difuzijo moč poganjati tudi lokalno. Odprtokodni primer je Stabel Diffusion. Na Githubu CompVis/stable-diffusion so raziskovalci z Univerze Maximilian Ludwig v Münchnu pod licenco CreativeML Open RAIL M objavili njegovo kodo, ki omogoča generiranje slik. Tudi OpenAi je na Githubu objavil številne svoje modele, med katerimi pa DALL-E 2 še ni.
Zanimivo je, da je DALL-E 2 v nekaterih primerih že precej uravnotežen. Risanje laboratorijskih tehnikov (lab technician performing an experiment with a beaker) ustvari štiri posnetke, na dveh sta moška, na dveh ženski. Po drugi strani pa so pravljična bitja iz morja (mermaid) še vedno izključno ženskega spola, zlobni direktorji (evil director) pa moškega. Stereotipov so ga naučili ljudje, o čemer več v nadaljevanju.
Kaj pa svoje slike
Druga, na prvi pogled še obetavnejša možnost je uporaba lastnih posnetkov. Naložimo lahko poljubno fotografijo, kjer imamo potem dve možnosti. Lahko jo uporabimo kot osnovno za generiranje novih fotografij, torej kot nekakšen vizualni ekvivalent ključne besede. Rezultati v bistvu sploh niso slabi, če odmislimo katastrofalne obraze oseb.
Lahko pa fotografijo z umetno inteligenco dopolnimo. V tem primeru sliko naložimo na enak način, potem pa v angleščini opišemo, kaj želimo fotografiji dodati ali odvzeti. Rezultat je zabaven, v nobenem primeru pa ni nadomestek za Photoshop. Postopek lahko iterativno ponavljamo, saj sliki vsakokrat dodamo nove elemente na omejenem prostoru. S ponavljanjem lahko sliko povečujemo.
Preizkusili smo oboje in ugotovili, da sta funkciji manj uporabni kakor ustvarjanje slik samo iz besedilnega opisa. Izdelava različic iz obstoječih fotografij je še solidna, obdelava, urejanje in razširjanje fotografij pa so zelo primitivni. Tu se bo moral DALL-E 2 še kaj naučiti – in če gre sklepati iz razvoja doslej, mu bo to hitro uspelo (ta del storitve ima še vedno oznako beta).

DALL-E 2 lahko uporabi naloženo fotografijo kot vhodni podatek, da ustvari različice.
Sodba
Uporaba DALL-E 2 je brezplačna, a ni neomejena. Ob registraciji dobimo 50 žetonov, ki jih lahko uporabimo za generiranje slik. Vsak poskus stane en žeton, obnovijo pa se vsak mesec na dan prve registracije. Vsak mesec se stanje ponastavi na 15 žetonov, za kaj več pa bo treba plačati. Mogoče je kupiti 115 žetonov, kar stane 15 dolarjev, ki jih poravnamo s kreditno kartico.
Latentna difuzija
Najnovejša generacija modelov za ustvarjanje slike (ISM – image synthesis model) uporablja tehniko, ki se imenuje latentna difuzija (latent diffusion). Modeli iščejo prepoznave oblike in podobe v šumu, ki jih nato izostrijo, če ustrezajo besedilnemu zahtevku. Tovrstne modele se uri z velikimi zbirkami slik, ki imajo ustrezne metapodatke, torej besedilne opise. Najpripravnejši vir tovrstnih je kar internet, kjer je na milijarde fotografij in slik z oznakami (alt tag) in pogosto kar celostavčnimi opisi (caption).
Ena tovrstnih zbirk je Laion-5B, ki vsebuje 5,8 milijarde prečiščenih slik in opisov. Na tej zbirki ali predhodnikih so se urili številni modeli za generiranje slik, tudi DALL-E, CLIP, FLORENCE in drugi. Celotna zbirka (laion.ai/blog/laion-5b) je prosto dostopna na internetu in meri 240 TB. Večina posnetkov je postrganih iz zbirk, kot so Pinterest, Deviantart, Getty Images, in podobnih. To zagotavlja, da vsebuje širok nabor posnetkov, od fotografij do umetniških ilustracij.
Model je treba potem »natrenirati«, kar poteka na zmogljivih grafičnih procesorjih. Stable Diffusion so urili 150.000 ur na 256 karticah A100, ki so bile vredne približno 600.000 dolarjev. Urjenje je namenjeno izgradnji modela, ki povezuje besedilo s sliko. Ta se s tem nauči statistične korelacije, kako obarvane pike so običajno v okolici drugih pik pri posamezni ključni besedi. Ko to obvlada, je sposoben generirati nove slike zgolj iz opisa, pri čemer nikoli ne ponavlja obstoječih slik iz zbirke, temveč ustvarja nove kombinacije iz njih.
Rezultati so lahko zelo realistični ali pa precej neumni, kot so ljudje s tremi rokami in šestimi prsti. A modeli postajajo tudi z uporabo čedalje boljši.
DALL-E 2 ni popoln in njegovih dosežkov še ne bomo lepili v časopise ali z njimi ilustrirali leposlovja, a po drugi strani mu do tja ne manjka več veliko, kar nas lahko navdaja tako z navdušenjem kakor s tesnobo. OpenAI namreč še zdaleč ni edini, ki razvija tovrstne modele in algoritme.
Tudi Google je razvil svojega, ki ga je poimenoval Imagen (imagen.research.google). Dasiravno ga še ne moremo preizkusiti sami, so znanstveni članek že spisali. Trdijo, da so ga primerjali s konkurenco (VQ-GAN+CLIP, modeli latentne difuzije, DALL-E) in da jo je zlahka premagal. Kakovost so ocenjevali ljudje, ki niso vedeli, čigavo sliko gledajo, temveč so se le opredelili, katera jim je bolj všeč.
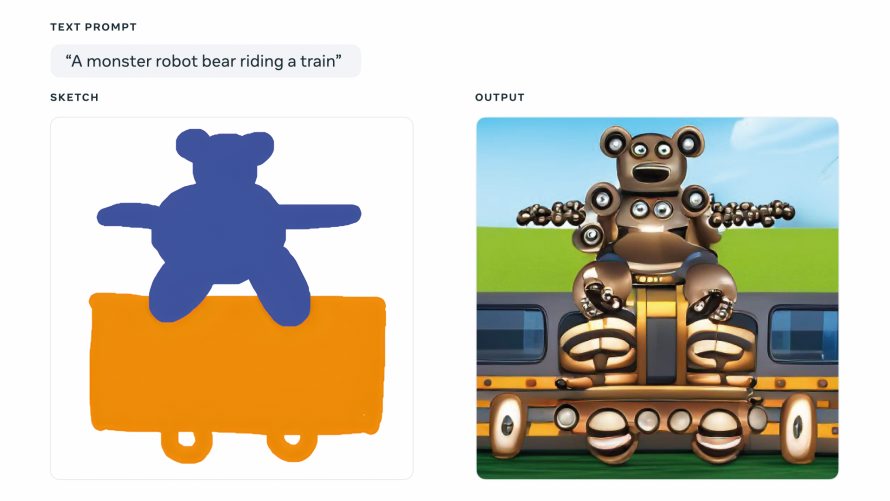
Facebookov Make-A-Scene sliko nariše iz besedilnega navodila in skice.
Seveda je lonček pristavil tudi Facebook. Svoj izdelek je poimenoval Make-A-Scene. Ta razume tako besedilna navodila kakor preproste skice, ki jih razvije v kompleksne slike. Medtem ko DALL-E 2 potrebuje obstoječo fotografijo, ki jo spremeni, Make-A-Scene primitivno skico nadgradi.
Naslednji korak je seveda video. Konec septembra je Facebook (oziroma Meta) predstavil orodje Make-A-Video, ki iz besedila ustvari kratek videoposnetek. Za zdaj so videoposnetki še precej osnovni, s popačeno animacijo in z zamegljenimi detajli, a to je šele prvi korak. V prihodnosti bodo daljši od pet sekund, na kolikor so omejeni zdaj, pa tudi zvok bodo dobili. Za pripravo takega modela potrebujejo tudi novo zbirko, ki vsebuje videoposnetke. Facebook je uporabil WebVid-10M in HD-VILA-100M, ki imata na milijone kratkih posnetkov, torej več sto tisoč ur materiala. Kako dobro deluje model, lahko le ugibamo, ker je Facebook pokazal le najboljše primerke, ne moremo pa modela preizkušati samostojno. Lahko pa preizkusimo CogVideo, ki so ga razvili na Univerzi Tsinghua in kitajski akademiji za umetno inteligenco (BAAI).
Google ne želi prav nič zaostajati, tako da smo oktobra dobili Imagen Video. Ta je trenutno sposoben izdelati posnetke s 24 sličicami na sekundo v ločljivosti 1.280 x 768. Omejeni so na dobrih pet sekund, kar ni tehnična omejitev, temveč Googlova omejitev modela. Izdelati je moč tudi modele brez teh omejitev, kakršen je Googlov sestrski projekt Phenaki. Ta je sposoben v video predelati več deset vrstic dolge opise, rezultat pa so tudi več minut dolgi posnetki.
Kam vse to vodi
DALL-E 2 ima seznam prepovedanih tem, kamor sodijo sovražne vsebine, nasilje, pornografske vsebine, nezakonite aktivnosti, zavajanje, politične in zdravstvene vsebine ter spam. Večine teh sploh ni mogoče ustvariti, ker so bile odstranjene iz zbirke, na kateri se je DALL-E 2 uril.
Podobno velja tudi za druge storitve ali algoritme. Licenca za Stable Diffusion prepoveduje tovrstno uporabo, a to je moč nadzorovati le pri storitvah v oblaku. Kodo, ki jo prenesemo na lokalni računalnik ali jo celo lokalno urimo, seveda lahko uporabljamo, za karkoli smo jo »natrenirali«, četudi to ni zakonito. Na Discordu že obstajajo strežniki, ki so namenjeni deljenju pornografskih rezultatov ISM.
Ameriška zakonodaja za zdaj dovoljuje nabiranje javno dostopnih posnetkov z interneta (scraping), če ti niso avtorsko zaščiteni. V Evropi je omejitev zaradi GDPR nekoliko več, a se v glavnem nanašajo na slike, ki omogočajo prepoznavanje oseb in vdor v njihovo zasebnost. Nabiranje generičnih podob ni nikjer prepovedano.

Googlov Imagen je posebej učinkovit pri izdelavi lažnih fotografij.
Ker se ISM učijo na zbirkah posnetkov, ki so jih naredili, zbrali in označili ljudje, se naučijo tudi istih predsodkov. Rezultat ključnih besed beautiful girl je vedno ženska, ki ima vsaj malce odkrite kože. Tajnice običajno nariše kot ženske, bogate ljudi kot bele moške. To so stereotipi, ki jih je umetna inteligenca podedovala od svojih »staršev«, torej ljudi, in jih zdaj nekritično širi dalje.
Razvoj ISM je šele na začetku in ni pretirano reči, da lahko v prihodnosti pričakujemo izdelke, ki bodo za nevešče oko nerazločljivi od resničnih posnetkov. Poraja se vprašanje, kaj vse se bo s tem počelo. DALL-E izrecno dovoljuje reprodukcijo, prodajo in komercialno izrabo stvaritev. Kaj pa uporaba v bolj zle namene, za dezinformacije, zavajanje in laganje, širjenje lažnih novic, za vplivanje na javno mnenje itd.? Družbena omrežja so se izkazala za idealno gojišče tovrstnih nakan, umetna inteligenca z ISM in ostalimi iznajdbami, kot so deepfake in generatorji besedil (npr. GPT-3), pa predstavlja odlično seme.

Obrazov DALL-E 2 še ne zna risati prepričljivo.
Tehnologija je pač nevtralna. Ljudje jo lahko uporabijo v dobre ali slabe namene, zato morajo prav ti postaviti pravila in varovalke, da se ne zgodi zadnje.