Stati na ramenih brezpravnih
O umetni inteligenci, ki je v zadnjem letu doživela novo renesanso, pišejo zgolj v presežnikih. Spremenila bo prihodnost, bodisi nam bo pričarala paradiž bodisi bo pogubila svet, v vsakem primeru so pričakovanja ogromna. Njene zmožnosti že danes delujejo čarobno, o njej govorijo največji strokovnjaki, rojeva se v laboratorijih v Silicijevi dolini, Londonu in na najuglednejših kitajskih univerzah. A za bliščem so nepregledne množice slabo plačanih ljudi, ki so s težaškim, z monotonim in nekvalificiranim delom to omogočili. To je zgodba o njih.

Mehanični Turek iz 18. stoletja je izrabljal človeško delo za stroj.
Ko je OpenAI novembra 2021 iskal delavce v Keniji, so bili v Nairobiju navdušeni. V državi že več let kot gobe po dežju rastejo centri za podporo uporabnikom, ki jih zaradi nizkih cen dela tam rade postavljajo multinacionalke. A Nairobi je precej več od tega. Vzdevek Silicijeva savana, ki je nastal kot očitna imitacija kalifornijske doline, ni naključen. V državi imajo eno najhitreje rastočih inovacijskih središč v Afriki, kjer je vzniknilo na desetine tehnoloških startupov.
Kenija ima 50 milijonov prebivalcev, ki so v povprečju mladi, sorazmerno dobro izobraženi in angleško govoreči. Hkrati je Kenija že danes ena bogatejših afriških držav in druga najprivlačnejša država za tuje investicije. Država postaja regionalno finančno, telekomunikacijsko in tehnološko središče. Internetne povezave v prestolnici so dobre, zato imajo v Nairobiju svoje pisarne tudi Microsoft, IBM, Intel ali Facebook.
Zakaj umetna inteligenca potrebuje ljudi
Ena izmed najučinkovitejših tehnik za trening umetne inteligence je RLHF (reinforcement learning from human feedback), ki je omogočila tudi razvoj ChatGPT. Z njo je mogoče razviti tako velike jezikovne modele (ChatGPT, Bing Chat, Bard) kakor tudi specializirano inteligenco, ki lahko igra videoigre.
RLHF je različica okrepitvenega učenja, ki pri izračunu nagrajevalne funkcije (reward function) uporablja povratno informacijo človeka. Pri učenju šaha lahko sistem sam ugotovi, kako dobro se je odrezal, ker so pravila jasna, izidi pa enoznačni. Pri analizi naravnega jezika pa je to precej teže. V praksi to pomeni, da morajo ljudje oceniti odzive umetne inteligence, denimo kakovost odgovorov ali njihovo faktografsko natančnost.
Druga naloga pa je seveda označevanje podatkov za trening, s katerimi se umetna inteligenca uči, na primer prepoznavati podobe na fotografijah, pisati programsko kodo ali razpoznavati govorjeno besedo.
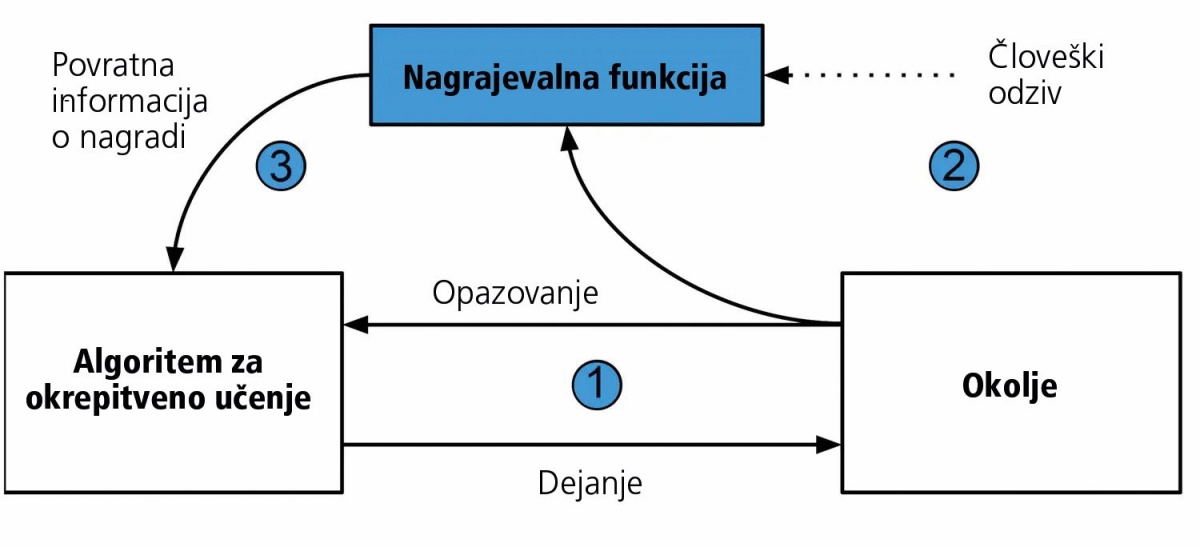
Učenje umetne inteligence s človeškim odzivom (RLHF). Slika: Deepmind
Od OpenAI so zato pričakovali veliko, pa čeprav podjetje ni zares stopilo v Nairobi pod lastno znamko. To je bila Sama, nekdaj Samasource, ki ima sicer sedež v San Franciscu, a večino zaposlenih v Keniji in Ugandi. Ustanovila ga je Leila Janah, o kateri smo že pisali (Človeški roboti, Monitor 12/18). Podjetje najemajo tako največji tehnološki velikani, od Facebooka, Googla in Microsofta, kot druge multinacionalke, denimo Walmart. Sama ima centre po vsem svetu, v njih pa ljudje opravljajo monotona računalniška dela zanje. Pred desetletji bi si to predstavljali kot vnašanje podatkov v preglednice in zbirke, danes pa gre za trening umetne inteligence.
Internet kot smetišče
Sama ima zloščeno mednarodno podobo. Nastala je kot neprofitna organizacija s plemenitim ciljem, da bi z dostojnim plačilom omogočila preboj iz revščine za ljudi v deželah v razvoju. Pravijo, da so iz revščine potegnili že 50.000 ljudi. Leta 2019 se je preoblikovala v profitno podjetje, v katerem je dotedanja neprofitna organizacija delničar. Podjetje in ustanoviteljica sta dobila številne nagrade. Leta 2011 jo je Forbes uvrstil na seznam 30 Under 30, Wired pa med 50 ljudi, ki bodo spremenili svet. Od leta 2019, ko je Janah odstopila zaradi zdravstvenih težav, podjetje vodi Wendy Gonzalez, ki je po smrti ustanoviteljice postala izvršna direktorica.
Še eno pomembno funkcijo ima Sama. Podjetje omogoča tehnološkim velikanom, da se ogradijo od dogajanja v teh centrih, saj so ljudje v njih zaposleni pri podizvajalcu, ta pa z njimi lahko ravna tudi slabo. Letos je revija Time objavila presunljivo zgodbo o podplačanih zaposlenih v centru v Nairobiju, ki so delali za OpenAI. A majhno plačilo je bilo še najmanjši problem.
Internet je smetišče. Običajni uporabniki pri svojem delu brodimo po površju, kot ga slikajo Google in največji mediji, a že bežen potop v manj popularne kotičke razkrije vso njegovo kompleksnost. Vsebin je tako rekoč neomejeno, njihova kakovost, primernost in dostojnost pa segajo od bleščečih diamantov do lukenj, črnih kot premog. Ko se je predhodnik ChatGPT, GPT-3, učil na javno dostopnih besedilih z interneta, so rezultati navdajali z mešanimi občutki. Njegove sposobnosti za ustvarjanje besedil so bile osupljive, njegova predrznost pa še bolj. Ker se je učil na vseh dosegljivih besedilih, so bili njegovi odzivi polni nasilnih, rasističnih, seksističnih in drugače neprimernih vsebin. GPT-3 je bil tako dober, ker je bila zbirka podatkov za njegovo urjenje tako obsežna, a prav zaradi tega je bil neotesan robavs. Toksični zapisi z interneta so se zrcalili v njegovem razumevanju sveta in seveda tudi izdelkih.
Iz učnega materiala je bilo treba odstraniti neprimerne vsebine. OpenAI je naletel na problem, ki bi tudi več tisoč inženirjem vzel leta, zato v surovi obliki praktično ni bil rešljiv. OpenAI je prispel do točke, kjer so se prvikrat resno spotaknila tudi družbena omrežja. Neprimerne vsebine je moral odstraniti v megalomanskem obsegu.
Rešitev obstaja, kar navsezadnje vidimo v ChatGPT tudi danes, ko je uglajen sogovornik. Umetna inteligenca je sposobna marsičesa, tudi odstranjevanja nasilnih vsebin, a jo moramo tega naučiti. Potrebovala je torej primerno označene izseke najbolj toksičnih vsebin: nasilja, zlorab, mučenja, seksizma, rasizma itd. To je OpenAI poslal v Kenijo.
Dolar na uro
Novembra 2021 je Sama začela sodelovati z OpenAI. Izbira je logična, saj si je Sama zgradila renome kot najboljši ponudnik storitev označevanja vsebin. Trdijo, da so »etično podjetje na področju umetne inteligence«, ki zaposlenim iz deprivilegiranih okolij daje možnosti. V Nairobiju so bile njihove možnosti vredne med 1,32 in 2,00 dolarja na uro, kolikor je Sama plačevala zaposlene.

Zaposleni v Sami označujejo posnetke za samovozna vozila.
OpenAI uradno ne želi razkriti, od katerih podjetij kupujejo storitve označevanja podatkov. Potrdili pa so, da so zaposleni v Sami prispevali k orodju, ki je bilo kasneje vgrajeno v ChatGPT, za zaznavanje in odstranjevanje toksičnih vsebin. Označevanje in razvrščanje škodljivih vsebin (besedila in slik) sta nujni sestavni del za razvoj takih orodij, so še dodali.
Time je ugotovil, da je OpenAI s Samo podpisal vsaj tri pogodbe v višini 200.000 dolarjev za storitve označevanja opisov spolnih zlorab, nasilja in sovražnega govora. Imeli so dobrih trideset zaposlenih, ki so bili razdeljeni v tri skupine, saj se je vsaka ukvarjala s svojo kategorijo. Na dan so morali prebrati od 150 do 250 odlomkov, ki so obsegali od sto do tisoč besed ter so plastično opisovali omenjene vsebine. Te so morali nato označevati. Več zaposlenih je povedalo, da je bilo to pravo mučenje, ker so morali brati res najbolj umazane in bolne izdelke človeške domišljije. Sama jim je uradno nudila psihološko pomoč, v praksi pa je šlo za skupinske delavnice, pa še tja niso mogli vedno. Podjetje po drugi strani trdi, da so imeli dostop tudi osebnih svetovalcev.
Čeprav je OpenAI plačeval 12,5 dolarja na uro, so zaposleni začeli z osnovno plačo v Keniji, torej 170 dolarjev na mesec. Prejeli so še 70 dolarjev dodatno zaradi pogojev in dodatke za hitrost ter natančnost, kar je skupno zneslo do 1,32 dolarja na uro. Dvema dolarjema so se približali najbolj izkušeni zaposleni na višjih položajih. Vratarji v Keniji zaslužijo okoli 1,5 dolarja na uro. V Sami medtem trdijo, da so morali zaposleni na dan označiti 70 odlomkov, plače pa da so segale od 1,46 do 3,74 dolarja na uro. Omogočili naj bi jim redno individualno psihološko pomoč, delavci pa so lahko delo kadarkoli odklonili.
Konec ljubezni
OpenAI ne razvija le ChatGPT. Tudi v naši reviji smo že pisali o njihovem orodju za ustvarjanje slik DALL E, ki se je takisto moralo izuriti na obstoječih izdelkih. Februarja lani je Sama dobila dodaten projekt za OpenAI. Lotiti bi se morali tudi opisov slik, zato jim je OpenAI poslal testni komplet 1.400 posnetkov. Ti so bili brutalni. OpenAI posnetke glede na stopnjo neprimernosti označuje od 1 do 4, kjer so C4 spolne zlorabe otrok, C3 posilstva in zlorabe živali, V3 posnetki nasilja, trupel in podobno. OpenAI je želel analizo kompleta za 787 dolarjev.

Poslopje Same v Nairobiju. Slika: Time
Le nekaj tednov pozneje, in sicer osem mesecev pred iztekom pogodb, je Sama odstopila od sodelovanja. Dejali so, da jih OpenAI ni obvestil, da bodo med posnetki tudi nezakoniti, ter da pristojni niso ustrezno preverili, kaj točno OpenAI želi. Prekinili so tudi vse druge pogodbe s podjetjem, denimo za označevanje besedila za ChatGPT. OpenAI se je v uradni izjavi izogibal priznanju, da so poslali tudi posnetke C4, so pa potrdili, da je komplet vseboval posnetke kategorij C1, C2, C3, V1, V2 in V3. Sodelovanje se je končalo februarja 2022.
V Sami so imeli problem. Čeprav so prekinili delo pri spornih projektih, se je slab glas hitro širil. Lufthansina hčerinska družba, ki je sodelovala s podjetjem, je zahtevala, da s spleta umaknejo vse reference o sodelovanju. Sama se je na koncu odločila prekiniti sodelovanje tudi s Facebookom, ki je prinašalo 3,9 milijona dolarjev in zagotavljalo 200 delovnih mest v Nairobiju.
A podjetji zvračata krivdo drugo na drugo. OpenAI trdi, da se je za Samo odločil zaradi njihove zavezanosti dobrim praksam, zato so od njih pričakovali pošteno plačilo, psihološko pomoč delavcem in normalne delovne pogoje. Sama pa trdi, da jih je OpenAI malodane preslepil, ko jim ni vnaprej povedal, kakšne surove vsebine bodo morali označevati.
Potrebe ostajajo
Čeprav ima Sama svoje zaposlene v več državah, jih je 75 odstotkov prav Nairobiju, je že pred petimi leti ugotovil BBC. Tedaj umetne inteligence v sedanji obliki še ni bilo, a potrebe so bile zelo podobne. Takrat so bila vroča tema avtonomna vozila, ki so svet spremljala v glavnem s kamerami in z lidarjem. Fotografije, ki so jih ti sistemi zajemali, so potrebovale oznake: ljudje, avtomobili, semaforji, talne oznake, nebo itd. Pomislite na znamenito CHAPTCHO, ki nam jo včasih prikaže Google, le da bi to počeli osem ur na dan z natančnostjo posameznega piksla.
Richard Mathenge, ki je začel delati v Sami leta 2021, je izkušnjo opisal za Slate. Devet ur na dan pet dni na teden je moral označevati slike iz lidarja samovoznih avtomobilov. Ko se je projekt iztekel, so ga premestili na delo za OpenAI. Manjša skupina, ki jo je moral voditi, je kmalu začela razpadati, ker niso zdržali vsakodnevnega prebiranja najnizkotnejših besedil. Posledice so bile vidne in tudi po koncu projekta imajo nekateri sodelavci psihološke posledice, med drugim depresijo, nespečnost, anksioznost.
Še pred OpenAI je bila eden največjih naročnikov Meta (Facebook). Zanjo zaposleni v Sami niso zgolj pripravljali materiala za urjenje umetne inteligence, temveč so bili moderatorji vsebin na družbenem omrežju. V Nairobiju so od leta 2019 skrbeli za moderiranje celotnega podsaharskega dela Facebooka, za kar so prejemali okrog 1,5 dolarja na uro. In vsebine na Facebooku so v tem delu sveta resnično brutalne, saj v državljanskih vojnah in oboroženih spopadih, kakršen je potekal v Etiopiji, nasprotne strani družbena omrežja uporabljajo za širjenje sovraštva, propagande, dezinformacij in ščuvanje. Že tedaj so se med zaposlenimi širile anksioznost, depresija in posttravmatska stresna motnja. Ko so želeli stavkati, so vodjo upora odpustili, a spremenilo se ni nič.
Tudi v tem primeru je bila geneza problema enaka. Zaposleni niso vedeli, kaj jih bo doletelo. Ob podpisu pogodb so jim delo predstavili kot preprosto moderiranje dezinformacij, šele nato pa so spoznali pravo naravo odstranjevanja najbolj pokvarjenih vsebin, ne da bi imeli ustrezno pomoč.
Razviti svet
V distopičnih napovedih umetna inteligenca nadomesti ljudi na čedalje več delovnih mestih. Spravljivi glasovi na to mnogokrat odgovarjajo, da jih bo v resnici še več ustvarila, a drugačnih, zahtevnejših, bolje plačanih, kakor so to storile še vse tehnologije doslej. Četudi to morda drži, za delovanje današnjih različic umetne inteligence potrebujemo poceni in nizko kvalificirano delovno silo. Ljudje, kot je Mathenge, ki v Nairobiju označujejo slike in odlomke besedil, imajo mnogokrat diplome, a jih v resnici za to delo ne potrebujejo. Kar je v resnici še večja potrata.
Naivno bi pomislili, da OpenAI najema nekvalificirano delo le v Afriki, Latinski Ameriki in Vzhodni Evropi, ker je tam pač poceni. To drži, a to ni vse, so ugotovili pri NBC. Alexej Savreux iz Kansas Cityja ima delo z lepo zvenečim nazivom – trener umetne inteligence. Skupaj s kolegi je podizvajalec za OpenAI, za kar prejema 15 dolarjev na uro brez dodatnih pravic. Njihovo delo je v javnosti spregledano, tudi OpenAI jih ne omenja prav pogosto, a je hkrati ključno za razvoj modelov umetne inteligence. Savreux označuje vsebine, pregleduje odzive umetne inteligence in pripravlja urejene komplete podatkov za trening. Brez tega umetne inteligence ni.
Stavka v Hollywoodu
Medtem ko umetna inteligenca zahteva veliko nekvalificiranega dela, pa so ustvarjalci v Hollywoodu zaskrbljeni. Maja letos so začeli stavkati v Združenju ameriških scenaristov (Writers Guild of America), s čimer si prizadevajo za boljše delovne pogoje in višje plače. Eden glavnih problemov so ponudniki pretočnih vsebin, ki krčijo proračune za scenarije.
To ni prva stavka tega ceha, saj so že v letih 2007 in 2008 ohromili večino ameriške produkcije televizijskih serij in filmov. Pred tem so stavkali še v letih 1960, 1973, 1981, 1985 in 1988. A to pot je ena izmed groženj tudi generativna umetna inteligenca. Zahtevajo, da se sme ta uporabljati le kot orodje, ki lahko pomaga v posameznih fazah razvoja scenarija, ne pa kot zamenjava za človeške scenariste.
Bojijo se namreč, da bi studii začeli uporabljati umetno inteligenco za razvoj idej in pripravo scenarijev, ki bi jih potem slabše plačani scenaristi le še »polikali«. Predsednik vzhodnega dela WGA Michael Winship poudarja, da niso popolnoma proti umetni inteligenci, a želijo odgovorno uporabo, ki ne krši avtorskih pravic in ni plagiatorska. Predvsem pa hočejo več varovalk.
A problem je širši, saj umetna inteligenca ne bo pisala le scenarijev, temveč lahko sklada glasbo, izboljša računalniško grafiko (CGI) in celo prepričljivo vrne mrtve igralce na platno ali pa zgolj omogoči, da posameznih kadrov ni treba ponavljati.

Protesti 5. maja 2023 pred Universal Cityjem v Kaliforniji. Slika: David James Henry, CC BY-SA 4.0
Jatin Kumar, ki dela v Austinu v Teksasu, se je kot trener pogovorov (conversational trainer) zaposlil takoj po diplomi iz računalništva. Njegovi glavni nalogi sta ustvarjanje pozivov (prompt) in preizkušanje zmogljivosti umetne inteligence v pogovorih. Odgovore, ki jih ta vrne, mora potem tudi ovrednotiti in opisati napake, da se lahko ChatGPT iz tega nauči. Kumar ob tem dodaja, da se je temu pridružil, ker mu omogoča vpogled v tehnologijo, še preden pride na trg, a bo kmalu zamenjal službo, saj ima tudi svoj startup. Kumar torej alternative ima. A brez tega dela umetne inteligence ni.
To potrjuje tudi Sonam Jindal iz neprofitne koalicije za odgovoren razvoj umetne inteligence Partnership on AI. V javni razpravi je veliko čestitk in hvale, kakor tehnološkemu sektorju pritiče. Ob tem opozarja, da so skozi celotno zgodovino tehnološki razvoj omogočali slabo plačani nekvalificirani delavci. V 50. letih preteklega stoletja so bili to operaterji luknjanih kartic, še danes pa imata Google in Apple javno vzpostavljen dvotirni sistem: redno zaposleni in agencijski delavci. Zadnji imajo slabše plače, manj pravic, več negotovosti, čeprav pogosto delajo v istih prostorih na isti opremi.
V poročilu iz leta 2021 je Partnership on AI opozoril, da se povečuje povpraševanje po delu, ki obsega obogatitve podatkov (data enrichment work), kakor imenujejo težaško delo označevanja, prebiranja, filtriranja in na sploh pripravljanja podatkov, da lahko avtomatizirani sistemi to uporabijo. Pozvali so k ureditvi standardov in sprejetju smernic, ki bi se jih morala podjetja kot naročniki držati, a se razen DeepMinda še nobeno ni prostovoljno zavezalo temu. Povedno pa je, da tehnološka podjetja tega ne želijo opravljati sama, temveč najemajo ponudnike, ki to počno daleč od oči sveta.
OpenAI ima približno 400 zaposlenih, a so v začetku tega leta uporabljali več kot tisoč podizvajalcev iz Latinske Amerike in Evrope. Približno 60 odstotkov jih je označevalo podatke, 40 odstotkov pa je ustvarjalo podatke za učenje programiranja umetne inteligence. Sprva se je namreč ta učila iz kode na GitHubu, zdaj pa uporablja tudi posebej zanjo napisano kodo, ki ima tudi obširne razlage v angleščini (ne le komentarje v kodi). Če ChatGPT poprosite za kodo, ki bo rešila neki problem, bo rezultat danes opremljen z nazorno razlago. Zdaj veste, kako se je tega naučil.
Moderni Turki
Leta 1770 je Wolfgang von Kempelen na dvoru Marije Terezije predstavil stroj, ki je znal dobro igrati šah proti človeškemu nasprotniku. Za majhno mizo, ki je bila del naprave, je posadil mehanično lutko, oblečeno v pražnja turška oblačila, ki jo je krmilil zapleten mehanizem. V resnici je bil v mizi skrit šahist, ki je premikal Turkovo roko. Mehanični Turek ni bil nič drugega kot ukana, zvijača, čarovniški trik, ki je izkoriščal spretnost skritega človeka – v resnici Kempelen ni nikoli trdil, da Turk igra sam.

Protesti pred Samo v Nairobiju maja letos.
Amazon je že leta 2005 zagnal platformo Amazon Mechanical Turk, postopek pa imenuje umetna umetna inteligenca (artificial artificial intelligence). Gre za outsourcanje nekaterih opravil ljudem, kadar so ti bistveno hitrejši in spretnejši od računalnika. Na platformi naročniki ponujajo tako imenovane HIT (human intelligence task), ki jih ponudniki proti plačilu izvedejo. Druga platforma je tudi Clickworker, koncept pa enak.
Obseg del, ki jih ljudje opravljajo na teh platformah, je precej širši od označevanja podatkov za trening umetne inteligence. Včasih gre za pomoč Alexi, ki ne razume vseh naglasov, drugič za urejanje fotografij izdelkov v spletnih trgovinah.
Hkrati tovrstne platforme predstavljajo še eno plast za izolacijo dejanskih naročnikov od ljudi, ki to opravljajo. Ne potrebujejo niti vmesnega podjetja, ki bi zanje najemalo ljudi, temveč se ti sami ponujajo prek platforme za mikrodela. Medtem ko Amazon trdi, da gre večinoma za občasno delo, skorajda konjiček, je za številne to nadomestek za polno zaposlitev in glavni vir prihodkov. Kot platformni delavci (gig workers) so popolnoma odvisni od Amazonovega algoritma in dobre volje, zato se javno ne želijo izpostavljati.
Kako naprej
Tudi v najbogatejših državah na svetu obstajajo težaška dela, ki jih ne želi opravljati mnogo ljudi. Težavo rešujejo z urejenimi delovnimi pogoji, ustrezno podporo zaposlenim, s primernim plačilom itn. Druga plat resnice je, da takšna dela pogosto opravljajo neizobraženi ljudje, prisiljenci in tisti, ki druge izbire nimajo.
Tehnološki razvoj je, ne tako pričakovano, prinesel kopico res slabih služb. Pogosto govorimo o negativnih vplivih družbenih omrežij na družbo, pri čemer pa se pogosto prezre visoka cena za tiho množico ljudi, ki neutrudno moderira vsebine. Le počasi se širi zavedanje, da je treba zanje primerno poskrbeti. Facebook je leta 2020 plačal 52 milijonov dolarjev v poravnavi zaradi psiholoških posledic, ki so jih imeli zaposleni v podjetju Accenture, potem ko so moderirali vsebine na družbenem omrežju. Vsak je dobil od 1.000 do 6.000 dolarjev, odvisno od diagnoze.
Številka žal zbledi ob znesku 500 milijonov dolarjev, kolikor jih Facebook letno namenja zgolj enemu izmed podjetij, ki to počno zanj. Predlani je Accenture Facebooku zagotavljal 1.900 zaposlenih za polni delovni čas, ki so moderirali vsebine, z vsega sveta – iz Manile, Mumbaja, Lizbone, Kuala Lumpurja, Varšave, Dublina, Kalifornije in Teksasa. Podobnih ponudnikov je še več.
Zdelo se je, da bo vsaj umetna inteligenca odpravila težaško delo moderiranja družbenih omrežij, a ga je v resnici še poslabšala. Morda ji bo v prihodnosti to res kdaj uspelo, a najprej jo bo treba za to izuriti, kar zahteva te iste označevalce vsebin, ki morajo zdaj načrtno brati predvsem problematične vsebine, da jih označijo in predajo umetni inteligenci v študij.
Se je scenarij, kjer umetna inteligenca zasužnji ljudi, že začel dogajati na najbolj ironičen in perverzen način?