Računalniško učenje v vsak žep
Računalniško učenje se je iz univerzitetnih laboratorijev prebilo najprej v industrijo in naposled do končnih izdelkov. Ne da bi vedeli, ga uporabljamo pri iskanju po slikah, prikazu sorodnih izdelkov v spletni trgovini, filtriranju spama, računalniškem prevajanju in pomenkovanju s Cortano ali Siri. Izkoristite pa ga lahko tudi na svojih podatkih, za kar vam ni treba izumiti tople vode, temveč zadostuje, da uporabite pripravljene programske vmesnike API.
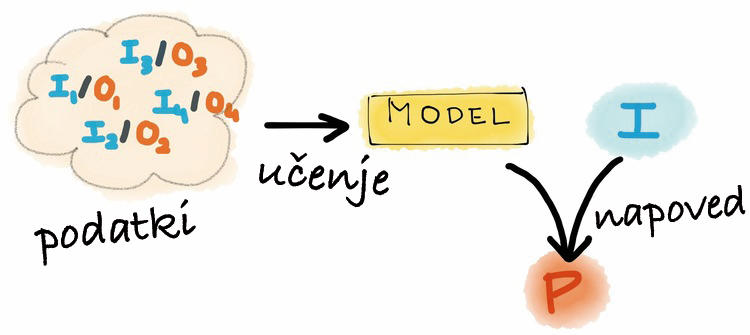
S podatki in znanimi rezultati najprej svoj model natreniramo, da ga potem lahko uporabljamo za analizo novih podatkov. Slika: Louis Dorard.
Na prvi pogled se zdi računalniško učenje enostavno, saj moramo zgolj postaviti nekaj umetnih nevronov v več nivojev in dobljeno mrežo natrenirati na podatkih, ki so sorodni problemom, za katere jo postavljamo. Ko se poglobimo v podrobnosti, se vtis popolnoma spremeni, saj je različic in izvedb zelo veliko, pri vsaki pa je treba poznati še razne zvijače in podrobnosti. Zato se na koncu zdi, da bo strojno učenje moralo ostati domena Googla, Amazona, IBMa in drugih velikanov. Pa to ni res.
Kakor nam ni treba poznati delovanja motorja z notranjim izgorevanjem, da lahko vozimo avtomobil, niti nam ni treba za pisanje Cjevske kode poznati procesorskih registrov, tudi za uporabo strojnega učenja ni treba doktorirati iz tematike. Razvoj je tako napredoval, da je računalniško učenje postalo storitev, ki jo veliki razvijajo in ponujajo, drugi pa najemajo (ali pa uporabijo odprtokodne programe, če imajo dovolj znanja). Ključna beseda je machine learning API oziroma programski vmesnik za strojno učenje.
Uporaba API je praktična, ker razvijalcem omogoča, da se osredotočijo na pripravo podatkov, analizo, uporabniško izkušnjo in razvoj aplikacije, odpadejo pa podrobnosti pri razvijanju in postavljanju modelov za računalniško učenje, priprava infrastrukture in njeno dimenzioniranje glede na potrebe. Tako lahko gledamo nanje kot na abstraktni nivo, ki nepotrebne tehnične podrobnosti skrije za konkretni problem, podobno kot APIji v programiranju počno že leta.
Glavni problem se tako prelevi v natančno definicijo, kaj želimo predvideti z računalniškim učenjem. Problem mora biti dobro definiran, in sicer lahko razvrščamo binarno (npr. ali je sporočilo spam ali ne), iščemo rešitev med več možnostmi (npr. prepoznava izgovorjene besede, predvidevanje naslednje zapisane besede) ali pa uporabljamo regresijski model, če nas zanima vrednost neke spremenljivke (npr. verjetnost, da bo dolžnik poplačal posojilo). Ob tem se moramo zavedati, da računalniško učenje kljub svoji moči ni univerzalna čarobna paličica, zato ni primerno za vse probleme. Če je naš problem rešljiv, moramo pripraviti le še čim več podatkov, s katerimi najprej natreniramo svoj model. Potem v dobljeni model (enolično ga določa številka ID) nalagamo podatke in dobivamo napovedi. Če smo domačo nalogo opravili pravilno, so te uporabne, za karkoli jih pač potrebujemo.
Dolgoročni trend komercializacije storitve strojnega učenja je, da se storitev trži podobno, kot lahko danes kupujemo hrambo podatkov ali računsko moč. Nihče se ne sprašuje, kje točno Dropbox skladišči naše datoteke niti na čem Amazonov EC2 poganja izračune. Isto želimo od APIjev za računalniško učenje; včasih ga lahko poganjamo na zalogo (recimo pri ocenjevanju kakovosti kreditnega portfelja ali določanju zvrsti glasbe), drugič pa v realnem času (za živo tolmačenje ali nalaganje predlogov pri vpisovanju iskalnih terminov).

Google Cloud Vision API z visoko verjetnost ocenjuje, da sta na fotografiji prikazana pojma »tek« in »maraton«. Slika: Google Blog.
Pričakovati je, da se bo obdelava podatkov z nevronskimi mrežami razrasla v velik trg, zato so na tem področju dejavni praktično vsi velikani. Google ponuja kopico rešitev s tega področja, ki zasedajo cel spekter. Na enem koncu najdemo TensorFlow, ki je odprtokodna knjižnica za računalniško učenje, ki uporablja tenzorje. Če ne veste, kaj je tenzor (posplošitev vektorja), ta pripomoček ni za vas. Namenjen je raziskovalcem in znanstvenikom, ki razvijajo strojno učenje. Na drugem delu spektra so visoko specializirani API, kjer včasih niti ne pomislimo, da gre za strojno učenje. Google Cloud Translate API, Cloud Speech API in Cloud Vision API so značilni zgledi, kjer je Google izdelal in dobro natreniral modele, da so uporabni za konkretno opravilo. Z njimi lahko pisci aplikacij uporabljajo isti zmogljiv in dodelan pogon kot Googlove aplikacije. Translate API prevaja vneseno besedilo, Speech API pa prepisuje govorjeno besedilo. Cloud Vision, ki je v javno beta različico prispel šele februarja letos, omogoča prepoznavanje objektov na sliki, prepoznavanje besedila, prepoznavanje neprimernih posnetkov (Safe Search), prepoznavanje obrazov (da je na fotografiji nekogaršnji obraz, ne pa čigav), prepoznavanje znamenitosti in logotipov blagovnih znamk.
Uporaba Googlovih storitev seveda ni brezplačna. Google Cloud Vision API bo na primer stal dva dolarja za tisoč slik. Preizkusite pa ga lahko tudi sami, saj Google vsakomur ponuja brezplačno preizkušanje v vrednosti 300 dolarjev, če vpišete številko kreditne kartice (ki je ne bremeni).
Na sredini med obema skrajnostma je Googlov Cloud Machine Learning, ki je namenjen reševanju problemov, ki niso dovolj splošni, da bi bil zanje na voljo namenski API – npr. že omenjeno ocenjevanje kreditne sposobnosti.
IBM Watson
Odkar je IBMov Watson zmagal na kvizu Jeopardy, je skorajda sinonim za računalniško učenje, pa čeprav to sploh ni Watsonov največji uspeh. Prek IBM Watson Developer Cloud lahko tudi programerji v domači sobi uporabljajo IBMove dosežke.
IBM ponuja več deset različnih APIjev, ki so glede na stabilnost razvrščeni v eksperimentalne, beta in stabilne, glede na operacijo pa na jezikovne, govorne, vizualne in podatkovne. Tako lahko pridelamo izvleček iz besedila, prevajamo, analiziramo osebnost na podlagi zapisanega, preverimo podton sporočil, prepisujemo govorjeno besedo, prepoznavamo slike in še in še. Delovanje večine APIjev lahko preverimo kar neposredno na spletni strani, so pa večinoma omejeni na angleščino.
IBM Watson se obračunava pavšalno, in sicer je na voljo v brezplačni oskubljeni, cenejši osebni enouporabniški (30 dolarjev na mesec) in poslovni (od 80 dolarjev na mesec na uporabnika) različici.
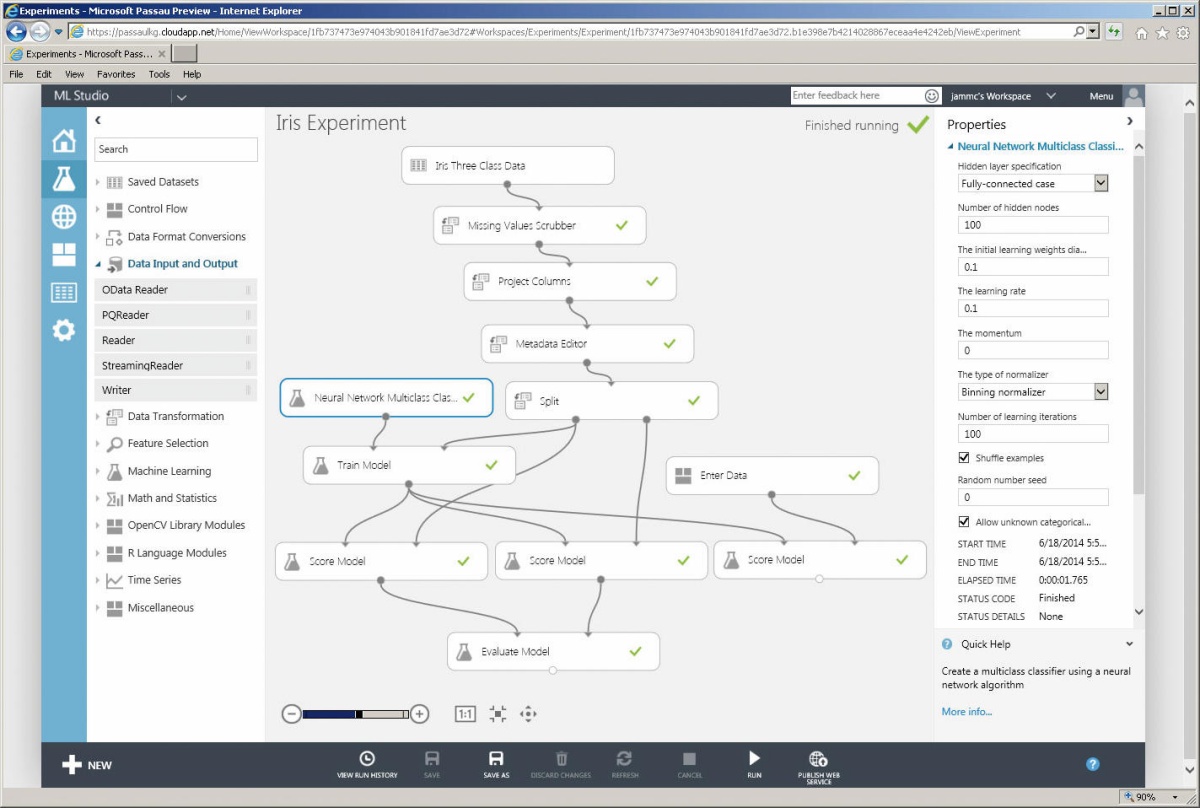
Zgled obdelave podatkov v Microsoftovem Azure Machine Learningu.
Microsoft Azure
Microsoftova pomočnica Cortana uporablja strojno učenje, da vas razume, in to isto infrastrukturo Microsoft ponuja prek storitve Azure Machine Learning. Na prvi pogled je podoben kot IBM Watson, a se istega cilja lotevata vsak s svojega konca. IBM Watson poizkuša odpraviti potrebo po suhoparnem podatkovnem rudarjenju z iskanjem korelacij, analizami varianc in podobnega ter to nadomestiti z naravnim jezikom. Vprašanja, ki si jih zastavljamo, je mogoče ubesediti v preprostem jeziku, zato Watson razume tak jezik.
Azure Machine Learning tega niti ne poizkuša, temveč se osredotoča na čim preglednejšo manipulacijo nad podatki. Če IBM Watson poizkuša nadomestiti podatkovnega znanstvenika, mu želi Microsoft čim bolj pomagati in olajšati delo. V preglednem grafičnem vmesniku nastavimo vhodno zbirko podatkov, module za prepocesiranje in želeni algoritem (nevronske mreže, logistična regresija, odločitvena drevesa itn.). Razume celo R in python, kar je velika prednost. Imeti moramo solidno poznavanje strojnega učenja, ni pa treba poznati podrobnosti algoritmov in njihove implementacije.
Amazon
Že dolgo ne prodajajo več le knjig. Pravzaprav že dolgo ne več le prodajajo, temveč imajo zelo močan oddelek za računalništvo v oblaku, kamor se seveda priključuje tudi strojno učenje, ki ga od lanske ločitve od Amazon Web Services tržijo pod imenom Amazon ML.
V Amazon ML naložimo podatke iz shrambe Amazon S3 ali Redshift, pri celotnem postopku pa nas lahko vodi čarovnik. Amazon sam zazna vrsto podatkov in predlaga nekaj modelov, lahko pa ustvarimo tudi svojega. Amazon ponuja nekoliko manj prilagodljivosti kot Azure, je pa preprostejši za uporabo. Največja pomanjkljivost je majhno število algoritmov, prednost pa pregleden grafični vmesnik.
In preostali svet
Storitve strojnega učenja in ustrezne APIje seveda ponuja še cela kopica drugih podjetij – pri hitrem pregledu smo jih našli več ducatov. Njihove rešitve niso same po sebi nič slabše od velike četverice, v nekaterih nišnih primerih pa so morda celo uporabnejše ali enostavnejše za uporabo. Velika četverica ima bistveno prednost s tem, da ponujajo tudi shrambo v oblakih in da lahko posledično berejo z vrste virov (Amazon S3, Redshift; Google Cloud Storage, BiqQuery; Azure Table in Blob Storage, SQL Database, Hive, Hadoop, OData). Tako lahko celoten postopek hranjenja in obdelave podatke integriramo na enem mestu, kar je prednost z vidika razpršenosti.
Prihodnost bo torej strojna. Zbiranje in shranjevanje podatkov sta že tako dobro rešena, da je ozko grlo postala obdelava teh podatkov. Zato bo široka uporaba strojnega učenja naslednja velika revolucija. Upajmo le, da jo bomo uporabili za revolucionarne dosežke, kot je IBMov smeli načrt izgradnje najboljšega zdravnika Watsona, in ne na primer za čim učinkovitejše oglaševanje.
Google Cloud Translate API nam omogoča uporabo Googlovega prevajalnika v lastnih aplikacijah.
SPLET
Slovenski osebni slikar
Slikovito si lahko uporabo nevronskih mrež in računalniškega učenja ogledamo na strani slovenskega porekla paintr.io. Z njeno pomočjo lahko svoje fotografije obdelate tako, da so videti kot slike, ki jih je v svojem značilnem slogu naslikal kak znan slikar. Potrebujemo dve slikovni datoteki – eno, iz katere bomo povzeli slog, in drugo, na katero bomo uporabljeni slog aplicirali. Spletna stran uporablja konvolucijske nevronske mreže (CNN), ki iz prve slike izvlečejo informacijo o oblikovanju, iz druge pa informacijo o vsebini. Rezultat je slika, ki vsebuje ti komponenti. V modernem svetu različnih filtrov na pametnih telefonih si lahko predstavljamo, da smo iz prve slike ustvarili filter.



Algoritem globokega učenja lahko fotografijo Celja predrugači v slogu Van Goghove slike Žitno polje s koscem.
Spletna stran sicer še ni povsem dokončana. Ker ji je 1. aprila 2016 potekla veljavnost certifikata HTTPS, nas brskalnik najprej opozori na to. Stran je sicer pregledno minimalistično oblikovana, tako da se ne moremo izgubiti. Na podstrani Submit lahko naložimo svoj slog in fotografijo, na Styles lahko izberemo katerega izmed več deset že pripravljenih slogov (Van Gogh, Picasso, Klimt ...), v Latest Submissions pa vidimo, kaj so oblikovali drugi ljudje, če so potrdili objavo v spletu. Ko v obrazec vpišemo elektronski naslov, naložimo obe slikovni datotek in ju pošljemo, čakamo. Predelano fotografijo prejmemo po elektronski pošti, a postopek kljub obljubam o minutah ni hiter, saj je naš preizkus vsakokrat trajal skoraj 24 ur.