Računajmo z grafiko
Zamisli, da bi veljalo grafične procesorje izkoristiti še za kaj drugega kot zgolj računanje grafičnih podob, so med inženirji vzcvetele kmalu po prelomu tisočletja, ko so se začele grafične zmogljivosti strmo dvigati. Danes smo priča grafičnim karticam, katerih procesorji se lahko pri splošnem računanju več kot le kosajo z najboljšimi osrednjimi procesorji. Kdo je torej najboljši matematik?
Namere o tem, da velja grafične procesorje izkoristiti tudi v splošne namene obdelave podatkov, so postale resne okoli leta 2002, ko se je ustanovila organizacija GPGPU, katere kratica pomeni General-Purpose computation on Graphics Processing Units. Grafični procesorji danes veljajo za visoko zmogljive mnogojedrne procesorje, ki jih krasijo odlične računske sposobnosti in visoka prepustnost podatkov v kombinaciji s hitrimi pomnilniki. Če je še pred desetletjem veljalo, da so ti procesorji ozko usmerjeni in namenjeni le obdelavi računalniške grafike ter za nameček še zelo zahtevni za programiranje, je danes zgodba precej drugačna. Sodobni grafični procesorji so po svoji sestavi večnamenski vzporedni procesorji, ki podpirajo vrsto programskih jezikov, med njimi poleg namenskih OpenCL in DirectCompute najdemo še C, C++, FORTRAN, javo, python in druge. Razvijalci aplikacij, ki te prilagodijo izvajanju na grafičnih procesorjih, so tako neredko presenečeni nad pohitritvami, ki jih njihovi programi doživijo v primerjavi z izvajanjem na osrednjih procesorjih. V nekaterih (žal še precej redkih) primerih je hitrost izvajanja na vzporednih mnogoprocesorskih zasnovah grafičnih čipov lahko večja tudi za trimestni faktor v primerjavi z izvajanjem na procesorjih z arhitekturo x86.
Model računanja z grafiko predpostavlja heterogenost osrednjega procesorja in grafike, skratka deluje tako, da logični del aplikacije še vedno teče na osrednjem procesorju, medtem ko se vsa matematično zahtevnejša opravila izvajajo v grafičnem procesorju. Z vidika uporabnika aplikacija, ki izkorišča tak način delovanja, deluje bistveno hitreje, saj se računsko zahtevna opravila zaradi mnogoprocesorske zasnove sodobnih grafičnih jeder izvedejo hitreje, poleg tega pa razbremenjen osrednji procesor skrbi za boljšo odzivnost operacijskega sistema in same aplikacije.

Takšna zasnova bi danes sodila med daleč najhitrejše, kar si jih lahko navaden smrtnik še privošči, pa že ob konfiguraciji, ki bi obsegala sodoben šestjedrnik in tri visoko zmogljive grafične kartice, bi se marsikateri računalnikar raje odločil za naložbo v rabljen avtomobil ali dvomesečno križarjenje po oceanih.
Vzporedna arhitektura v računalništvu omogoča občutne izboljšave računalniških zmogljivosti, če poleg osnovnega procesorja izrabimo tudi zmogljivost grafičnega procesorja. Današnji razvijalci, raziskovalci in drugi znanstveniki so že našli vrsto področij, kjer te kombinacije s pridom izkoriščajo. Poleg najbolj očitnih področij, kot sta obdelava fotografij in video posnetkov, so izdatnega prirastka računskih zmogljivosti najbolj veseli biologi in kemiki, pa inženirji, ki se ukvarjajo s preračunavanjem dinamike tekočin, znanstveniki, ki raziskujejo seizmične aktivnosti tal našega planeta, in še bi lahko naštevali.
GPGPU v strežniških okoljih
Ne samo osebni računalniki, tudi strežniki bi lahko z uporabo heterogenih možnosti izrabe vseh procesorjev znotraj posamezne strežniške rezine lahko pridobili na zmogljivostih, še posebej, če bi bila programska koda posebej optimizirana zanje. Kljub velikim upom, ki jih skupnost vlaga v zagon GPGPU podprtih aplikacij za strežnike, pa so v podjetju AMD zadržani glede dejanske izvedbe. Pri procesorskem gigantu namreč menijo, da namenska programska oprema še zdaleč ni dovolj dodelana (po videnem se z njimi absolutno strinjamo), zato grafični procesorji še lep čas ne bodo prevzeli matematičnega primata v podatkovnih centrih. Že res, da je nekaj zanimivih pilotskih projektov, ki bi jih lahko označili za uspešne poskuse, vendar tudi razvijalci strežnikov ne morejo kar čez noč spremeniti svoje filozofije in na tanke rezine vgrajevati na ducate grafičnih procesorjev, še posebej, ker so ti energijsko zelo zahtevni in bi marsikje presegli okvire možnosti napajanja sistemskih omar. V AMDju so svojo napoved pohoda GPGPU aplikacij in strojnih rešitev v podatkovne centre smelo primerjali s časom, ki je bil potreben za množični sprejem 64-bitne strojne opreme in aplikacij. Ali, po domače povedano, grafični procesorji še vsaj desetletje ne bodo imeli glavne besede v podatkovnih centrih.

V reklamne namene se zlasti pri Nvidii radi pohvalijo, da je grafični procesor za določene naloge lahko tudi do 250-krat hitrejši od procesorja z arhitekturo x86.
##
Predstavitev tehnologij
Med širšo publiko se je začelo zanimanje za računanje s pomočjo grafičnih procesorjev večati šele po letu 2006, ko sta največja izdelovalca grafičnih kartic napovedala svoji namenski tehnologiji - pri Nvidii so povili CUDA, ATI pa je svojo rešitev poimenoval Stream. Seveda je uspeh posamezne tehnologije v tem primeru odvisen od posameznega izdelovalca in njegovih povezav z razvijalci programske opreme, pri čemer lahko mirno zapišemo, da v tem trenutku vodi Nvidia s CUDO. A na dolgi rok bi se moral razvoj poganjanja različnih programskih kod na grafičnih procesorjih poenotiti, zato pa potrebujemo (odprte) standarde. Trenutno sta na obzorju predvsem dva, ki bi to utegnila postati. Ena je knjižica OpenCL, drugi pa DirectCompute, ki je del Microsoftove knjižice DirectX.
Nvidia CUDA
Tabor zelenih je bil prvi, ki je začel obsežneje poudarjati vlogo grafičnega procesorja v druge koristne namene. S tehnologijo CUDA (kratica je okrajšava za Compute Unified Device Architecture) so hitro "okužili" različne ponudnike programskih paketov za obdelavo videa in zadevo medijsko napihnili, to pa jim je prineslo veliko pozornosti javnosti. Njihovi novi grafični procesorji kar naenkrat niso zgolj strojno pospeševali predvajanja zahtevnih video vsebin visokih ločljivosti (pri tem pravzaprav ni šlo za pravo splošno procesiranje na grafičnem procesorju, temveč so to delo opravljala namenska vezja za dekodiranje videa), temveč so jih zmogli zelo hitro tudi obdelovati (o tem smo v Monitorju že pisali, in sicer januarja 2009 v članku Nvidia proti Intelu!). CUDA s pridom izrablja zasnovo grafičnih procesorjev, ena njenih največjih prednosti pa so deljeni bloki pomnilnika, ki si jih niti med seboj lahko delijo in tako še pospešijo samo izvajanje ukazov.

Med najbolj znanimi implementacijami tehnologije CUDA seveda prevladujejo aplikacije za obdelavo video vsebin, denimo MotionDSP vReveal, CyberLink PowerDirector, Loilo Super Loiloscope, ArcSoft TotalMedia Theatre 3, Elemental Badaboom in druge.
AMD ATI Stream
Tudi v AMDju, ki si je kupil grafični oddelek od podjetja ATI Technologies, v zadnjih letih namenjajo več pozornosti splošnim računskim zmogljivostim svojih grafičnih kartic. Njihova tehnologija vzporedne obdelave sliši na ime ATI Stream in omogoča aplikacijam delovanje na grafični arhitekturi, kjer grafični cevovodi nimajo več fiksno določenih funkcij, temveč so povsem programabilni in kot taki uporabni v najrazličnejše namene.

AMD je razmeroma pozno dojel, da za uspeh svoje tehnologije ATI Stream potrebuje uspešno sodelovanje z razvijalci programskih paketov, ki jih uporabljajo večje skupine zahtevnih uporabnikov
AMD je razmeroma pozno dojel, da za uspeh svoje tehnologije ATI Stream potrebuje uspešno sodelovanje z razvijalci programskih paketov, ki jih uporabljajo večje skupine zahtevnih uporabnikov. Tako so se šele leta 2009 resneje lotili implementacije podpore za ATI Stream v nekatere izdelke za obdelavo videa in večpredstavnih vsebin (npr. CyberLink PowerDirector različici 7 in 8 ter Roxio Creator 2010). Od konca leta 2009 je aktivno tudi sodelovanje s podjetjem Adobe, zato ATI Stream pospešuje izvajanje Flash vsebin in obdelovanje grafičnih izdelkov v programskem paketu Photohop. ATI Stream je podprt tudi v ArcSoftovem programskem paketu TotalMedia Theatre 3.
OpenCL
OpenCL predstavlja programski jezik (Open Computing Language) za pisanje programov, ki delujejo na heterogenih platformah, v našem primeru kombinaciji grafičnega in osrednjega procesorja. Omogoča vzporedno obdelavo nalog in podatkov, arhitekturno pa močno spominja na svoja "konkurenta", Nvidijino CUDO in Microsoftov DirectCompute, s katerima si ne nazadnje deli tudi nekaj gradnikov.
OpenCL so sicer najprej razvili v Applu, ki si še danes lasti to blagovno znamko, vendar so kasneje v navezi s partnerskimi podjetji AMD, IBM, Intel in Nvidio razvoj predali delovni skupini Khronos Group, ki je konec leta 2008 povila odprtokodni standard OpenCL 1.0. Danes pri razvoju OpenCL sodeluje že več kot 30 podjetij iz računalniške industrije, OpenCL pa je junija letos dopolnil specifikacijo 1.1 s številnimi novimi funkcionalnostmi. OpenCL ima vse večjo podporo tudi na strani razvijalske skupnosti, ki si ne želi razvijati optimizacij za AMDjeve in Nvidijine grafične procesorje posebej, temveč naj bi za poganjanje nalog na grafičnih procesorjih skrbel enoten jezik. Prednost OpenCL je tudi v tem, da deluje na vseh najbolj razširjenih platformah na svetu, torej v vseh (naj)novejših operacijskih sistemih Microsoft Windows, Apple MacOS in distribucijah Linuxa.
Microsoft DirectCompute
Microsoft DirectCompute je programski vmesnik, ki podpira splošno obdelavo na grafičnih karticah. Je del Microsoftovih (grafičnih) knjižic DirectX 10 in DirectX 11, zato je za razliko od odprtokodnih alternativ podprt le v operacijskih sistemih Windows Vista ter Windows 7. Kot že omenjeno pri opisih drugih rešitev, si DirectCompute z nekaterimi deli več gradnikov, to pa bi mu lahko v prihodnje pomagalo, da postane de facto standard programiranja za aplikacije GPGPU, pa čeprav zgolj na platformi Microsoft Windows.

Podobno kot druge rešitve tudi današnja uporaba DirectCompute cilja predvsem na nove možnosti računalniških iger po prikazu čim bolj realistične grafike, pri čemer prednjači obdelava fizikalnih modelov ter napredno senčenje in osvetljevanje. Nova generacija iger, ki bodo znale bolje izkoriščati navezo CPU-GPU, bo tako uporabnikom postregla z bistveno večjim realizmom, kot ga poznamo danes.
Kaj zmorejo grafične kartice?
Tehnologija CUDA je danes podprta na več kot sto Nvidijinih grafičnih karticah, ameriški izdelovalec se tudi pohvali, da je prodal že več kot 100 milijonov kartic z omenjeno tehnologijo, kljub temu pa te po samih zmogljivostih računanja s plavajočo vejico trenutno precej zaostajajo za AMDjevimi konkurenti. Paradni konj, GeForce GTX 480, sicer pri enojni natančnosti računanja zmore 1,35 teraFLOPS, s čimer skoraj podvoji rezultat prejšnje generacije (GTX 285 zmore 0,708 teraFLOPS), a še vedno krepko zaostane za Radeonom HD 5870, ki med enoprocesorskimi grafičnimi karticami z zmogljivostjo 2,72 teraFLOPS še vedno krepko drži primat. V primeru računanja z dvojno natančnostjo pa rdeči vrag svojo prednost še poveča, saj so njegove zmogljivosti trikrat večje kot pri najzmogljivejšem GeForcu (544 gigaFLOPS proti 168 gigaFLOPS).
Drugi pomemben dejavnik predstavljata pasovna širina pomnilniškega vodila in hitrost pomnilnika, saj določata prepustnost podatkov v obdelavo v grafični procesor. Tu so si najzmogljivejše novodobne grafične kartice precej sorodne, saj je pasovna širina pomnilnika med 150 in 180 GB/s. Zahvaljujoč uporabi bliskovito hitrega pomnilnika GDDR5 lahko kartice v sekundi obdelajo do 5000 milijonov grafičnih tekstur. Njihova uporabnost v splošne namene računanja pa je omejena s številom niti, ki jih mnogoprocesorska zasnova grafičnih jeder omogoča. Seveda sodobni grafični procesorji po tej plati krepko prekašajo osrednje procesorje, vendar velja dodati, da tudi razvijalci aplikacij te izredne večnitnosti v praksi nikoli ne izkoristijo v popolnosti, saj jim navadno zadostuje že eno- ali dvomestno število niti za izvajanje ukazov, druge pa pač rabijo za hitro komunikacijo s pomnilnikom. Pri Nvidiji razvijalcem celo svetujejo, da za kar najboljši izkoristek uporabljajo skupine po 32 niti, pri čemer lahko skupno število niti dosega tudi številko nekaj tisoč.
Procesiranje na grafičnih karticah uporablja metodologijo SIMD (single instruction, multiple data), medtem ko osrednji procesorji svoje delo opravljajo po načelu SISD (single instruction, single data). Visokoparalelna arhitektura grafičnih procesorjev pri tem zmore z vsakim delovnim taktom opraviti več deset tisoč opravil, osrednji procesor pa prebavi zgolj nekaj vzporednih operacij v delovnem ciklu.
Največje število niti, ki jih lahko obdela grafični procesor - primerjava med posameznimi generacijami:

Najnovejši GeForce je krepko večji čip od Intelovega šestjedrnika, zakaj ne bi torej bil tudi hitrejši?
Računanje v praksi
Za prikaz zmogljivosti grafičnih kartic pri prevzemu bremena osrednjih procesorjev smo izbrali več različnih primerov iz prakse. Nekateri med njimi so bolj, drugi pa manj pogosti, a oboji nazorno kažejo potencial naveze osrednjega in grafičnega procesorja, ki ga velja v računalništvu v prihodnje kar se da pogosto izkoristiti. Primerjali smo delo osrednjega procesorja Intel Core i7 930 z delom grafičnih procesorjev, ki delujeta na karticah Nvidia GeForce GTX 470 in AMD ATI Radeon HD 5870.
Predvajanje bogatih vsebin visokih ločljivosti
Predvajanje filmov na ploščkih blu-ray je poleg sodobnih iger bržkone ena najpogostejših nalog, ki zna doleteti sodobne grafične kartice v domačem okolju. Kot že omenjeno, so skoraj vse novinke opremljene z namenskimi vezji za dekodiranje videa, ki jih še dodatno nadgradijo programske tehnologije, kot sta Nvidia PureVideo in ATI Avivo HD. Njihov namen je prevzeti breme osrednjega procesorja pri predvajanju video in avdio vsebin visoke ločljivosti in to jim odlično uspeva. Intelov štirijedrnik brez njihove pomoči tako porablja dobro tretjino svojih zmogljivosti, ob vklopu omenjenih pomočnikov pa obremenitev procesorja upade na vsega odstotek ali dva.
Obdelava fotografij v Adobe Photoshop
Grafični oblikovalci in postavljalci revij kar lep del svojega časa namenjajo obdelavi fotografij. Tudi zanje naj bi imeli dobro novico, saj tako Nvidia kot AMD navajata, da imata ustrezno podporo za pohitritev računanja nalog tega priljubljenega grafičnega programa. V Adobe Photoshop CS5 smo pognali test DH Photoshop Benchmark v3, ki je sestavljen iz 15 različnih opravil, pretežno manipulacij velike fotografije. Tudi zadnji Adobe Photoshop še ni povsem optimiziran za večjedrne procesorje, zato bi bila zmaga grafik na tem preizkusu pričakovana, vendar ni tako ali pa je preizkus še vedno premalo zahteven, da bi pokazal večjo prednost grafik. Tako sta se navezi Core i7 930 in GeForce GTX 470 oziroma Radeona HD 5870 odrezali skoraj enako z rezultatom okoli 200 točk, kolikor jih sicer omenjeni procesor doseže tudi v navezi z manj zmogljivimi grafičnimi karticami.
V Photoshopu prednosti "grafičnega računanja" nismo uspeli izmeriti.
(Pre)kodiranje video posnetkov
Program Elemental Badaboom smo v eni zgodnejših različic že preizkusili v našem že omenjenem obračunu Intela in Nvidie. Program, ki je močno optimiziran za izrabo tehnologije CUDA, je tudi tokrat potrdil premoč grafičnih procesorjev GeForce, saj je GTX 470 upravičil svojo drago in napredno arhitekturo ter s prekodiranjem posnetka (iz ločljivosti 1080p smo video manjšali v ločljivost 720p, velikost datoteke dobrih 200 MB) opravil najhitreje, v 36 sekundah.
Preizkusa na Radeonu HD 5870 nismo mogli opraviti, saj zadnja serija teh grafičnih procesorjev (nalašč?) še ni podprta, smo pa zato vpregli prejšno generacijo in njenega najzmogljivejšega predstavnika. Radeon HD 4890 je postregel z dobrim hitrostnim rezultatom, saj je delo opravil v 46 sekundah, le pri kakovosti obdelanega videa je očitno zaostal.
V programu Badaboom ima uporabnik na voljo že nekaj prednastavljenih vrednosti prekodiranja vsebin za vse bolj priljubljene (mobilne) platforme.
Za primerjavo smo prekodiranje video posnetka x264 pognali še v programu Total video converter, pri čemer je vse delo opravljal zgolj osrednji procesor. Intelov štirijedrnik zadnje generacije je za nalogo potreboval kar poldrugo minuto in kot tak priznal hitrostni poraz na tem preizkusu, se je pa odkupil s kakovostno najboljšim izdelkom.
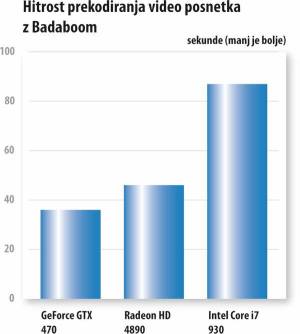
Moramo pa zapisati, da program Badaboom s svojim (pre)kodiranjem na grafičnih procesorjih ne dosega kakovosti posnetkov, primerljive z osrednjim procesorjem, kar je še posebej očitno ob večjih povečavah slike ali pa vsebinsko bogatejših posnetkih s hitrim gibanjem. Naše subjektivno mnenje glede kakovosti obdelane vsebine na prvo mesto postavlja Intelov Core i7, sledi mu GeForce GTX 470, s kakovostno najslabšim rezultatom pa je tokrat postregel ATIjev Radeon predzadnje generacije.
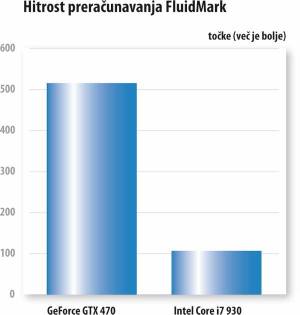
Simulacija pretakanja tekočin FluidMark
Dokaz, da jim je pri Nvidii na svojo stran uspelo prinovačiti več razvijalcev aplikacij kot pri AMDju, je tudi program za analizo simulacij tekočin FluidMark. Ta, denimo, s pridom uporablja tehnologijo Nvidia PhysX, ki močno gradi na osnovi CUDA, ki pri dotičnih izračunih fizikalnih modelov tehtnico močno nagne na stran grafičnega procesorja. GeForce GTX 470 je tako Intelov štirijedrnik premagal skoraj za faktor 5, saj je v istem času opravil 85 simulacij, osrednji procesor pa jih je zmogel le 18. Preizkus FluidMark na grafičnih procesorjih Radeon ne deluje.
CyberLink PowerDirector
Program CyberLink PowerDirector je eden izmed peščice komercialnih programov, ki podpirajo tako AMDjevo kot Nvidijino tehnologijo za pospeševanje obdelave vsebin na grafičnih procesorjih. Izkaže se, da je, kar se tiče pospeševanja, zelo izbirčen. Če imamo srečo, je njegovo kodiranje v H.264 s pomočjo grafične kartice izredno hitro, če je nimamo, pa nam tovrstno pospeševanje sploh ne bo delovalo. Ali pa boste pristali nekje vmes, ob občasnih "sesutjih".
V uredništvu imamo nekaj računalnikov s pospeševalniki nVidia (8800 GT in GTX 285), kjer deluje odlično, medtem ko nam ga na testnem računalniku, ki smo ga uporabili za tokratni primerjalni preizkus, nikakor ni hotel delovati, oz. se je sesuval. To se je dogajalo tako z ATIjevim kot z nVidiinem pospeševalnikom, zato preizkusa kljub večkratnim ponovitvam nismo mogli opraviti. Intelov matematik je torej dobil ta preizkus brez boja.
S CyberLinkovim programom za obdelavo videa preprosto nismo imeli sreče.
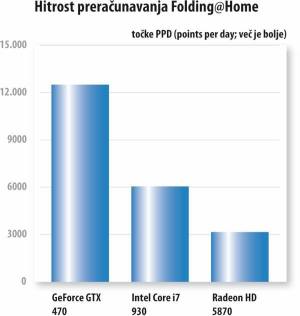
Folding@Home
Grafični procesorji so še posebej močni pri operacijah računanja s plavajočo vejico (Floating Point OPerations - FLOPs), ki so ga za pomoč pri izračunih dinamike molekul s pridom izkoristili tudi avtorji priljubljenega projekta Folding@Home, s katerim domači uporabniki lahko svoje mlinčke in njihove zmogljivosti "posodijo" znanstvenikom, ki si prizadevajo izboljšati naš planet. Folding@Home podpira Nvidijine grafične procesorje z jedri G80 ali novejše (pač vse z napisi CUDA) ter AMDjeve generacije grafičnih procesorjev od R6xx naprej. Optimizacija programske kode za izvajanje na grafičnih procesorjih naj bi ponudila od 20- do 40-krat boljše rezultate kot v primeru računanja z osrednjim procesorjem. Naš preizkus tega žal ni potrdil v celoti, saj je le GeForce premagal Intelov procesor Core i7, medtem ko je Radeon, za katerega podpora ni napisana tako temeljito kot za CUDA in v tem primeru izkorišča le jezik OpenCL, občutno zaostal.
Sklep
Uporaba grafičnih kartic za splošno procesiranje je odlična zamisel, ki se bo v prihodnje še razvijala. Že danes lahko vidimo vse več primerov koristne rabe, ki se bo čez čas razširila tudi na bolj splošne aplikacije. A zato bi potrebovali industrijski dogovor za enoten standard za programiranje aplikacij, ki bi tako pospešil razvoj programske podpore heterogenemu procesiranju. Ali bo prevladal OpenCL ali pa DirectCompute, je nam, končnim uporabnikom, popolnoma vseeno. Ne nazadnje nimamo prav nič proti, če nam grafične kartice, vredne nekaj sto evrov, pridno pomagajo pohitriti prav vsa opravila, ki jih počnemo z računalnikom. Toda zato bi si morala oba grafična giganta seči v roke in nehati novačiti izdelovalce aplikacij vsak na svojo stran ter raje začeti spodbujati razvijalce k enotnemu razvoju podpore za aplikacije GPGPU.
Trenutno sicer še vedno velja, da tudi zmogljivi štiri- in šestjedrni procesorji zmorejo ta opravila postoriti razmeroma hitro, predvsem pa bolj kakovostno (z vidika kakovosti obdelanih video posnetkov). A zdi se, da bodo z višanjem ločljivosti večpredstavnih vsebin primat prej ali slej prevzeli grafični procesorji.