Ko računalniki berejo
Živimo v digitalnih časih. Če nam ljudje vsebine ali informacije podajajo analogno, denimo na papirju, se nam zdijo bistveno manj uporabne, saj jih ne moremo v hipu obdelati, popraviti in/ali razposlati več prejemnikom. Potrebujemo namreč rešitev, ki nam bo zadeve kar se da pravilno digitalizirala.
##

Prav zato smo se odločili pripraviti preizkus programov za optično prepoznavanje znakov (optical character recognition, OCR). Teh je na trgu slaba dva ducata, vendar le peščica pozna šumnike, uradno pa slovenščino podpirajo le trije. Te tri smo tudi preizkusili v praksi in ugotovili, da je stopnja prepoznavanja in digitalne pretvorbe dokumentov v zadnjih letih zelo napredovala. Ne nazadnje traja razvoj rešitev OCR že 80 let, po začetnem velikem navdušenju in razcvetu na prelomu stoletja pa je v tem poslu danes ostalo le nekaj velikih imen, izdelovalcev programske opreme, če želite.
Namenjeni predvsem poslovni rabi
Programi za optično prepoznavanje znakov so po navadi del obširnejših programskih paketov, ki znajo in zmorejo obvladati celoten tokokrog dokumentov, oziroma se integrirajo v sam informacijski sistem, ki njihove funkcionalnosti še razširi. Upravljanje dokumentov je namreč veda v malem, vse več podjetij pa počasi le začenja opravljati izračune, koliko jih papirnati dokumenti (in njihovo ustrezno hranjenje) dejansko stane. Na tem področju so mogoči veliki prihranki, tako časa kot denarja. Samo pomislite, da vam ne bi bilo treba nikdar več pretipkati dokumenta, dokumentov ne bi nikdar izgubili, poiskali pa bi jih skoraj v hipu ... Vse to so glavne in dopolnilne prednosti tehnologije OCR, ki pomaga analogne dokumente spremeniti v digitalno obliko, ki jo lahko urejamo, ji preiskujemo vsebino in/ali jo delimo z drugimi uporabniki.
Dokumenti v digitalni, elektronski obliki korenito znižajo stroške shranjevanja in arhiviranja, pa seveda tudi vse druge stroške, povezane s kopiranjem, tiskanjem, faksiranjem, razmnoževanjem, deljenjem med uporabniki in kar je še drugih vrst poslovne rabe dokumentov. Poleg denarja se zdijo še največji časovni prihranki, saj opravila, za katera smo nekoč potrebovali več ur, opravimo z vsega nekaj kliki. Lahko bi celo zapisali, da tehnologije OCR pomagajo izkoristiti ves potencial podatkov, ki so v/na dokumentih.
Zajem z optičnim bralnikom ali fotoaparatom
Za zajem dokumentov v digitalno obliko se najpogosteje uporabljajo optični bralniki, med uporabniki bolj znani kot skenerji. Za optično prepoznavanje znakov zadostuje že vsak optični bralnik, dražji modeli pa po navadi poleg hitrosti prinašajo nekoliko širši nabor funkcij in večjo natančnost zajema, ki pa pri zajemu tipičnih poslovnih dokumentov ali revij ni ključnega pomena. Ko smo vsebino enkrat digitalno zajeli, lahko z njo počnemo, karkoli nam poželi srce. Vsebino lahko shranimo kot različne oblike dokumenta, jo arhiviramo ali prek omrežja delimo z drugimi uporabniki, možnosti so praktično brezmejne.
Na Monitorjevem preizkusu smo za zajem vsebin uporabljali optični bralnik znamke Canon, model CanoScan 5600F, ki velja za enega zmogljivejših predstavnikov svoje vrste. Kljub temu je vse breme optičnega prepoznavanja vsebine padlo na umetno pamet programov OCR, optični bralnik je rabil le za zanesljiv vir zajema.
Kot alternativni vir za zajem vsebin lahko uporabimo tudi digitalni fotoaparat, ki ga danes že najdemo praktično v vsakem gospodinjstvu. Takšna rešitev je praktična, če imamo namen digitalizirati le manjše število dokumentov, pri večjem obsegu pa velja razmisliti o naložbi v optični bralnik. Ena izmed največjih prednosti uporabe optičnega bralnika za zajem vsebine je njegova ločljivost - ta je po navadi bistveno višja od tiste, ki jo premore katerikoli fotoaparat, programi OCR pa z veseljem sprejmejo dodatne informacije v sliki, ki so jim pomoč pri prepoznavanju in obdelavi vsebine. Seveda moramo dokumente na ta način najprej ustrezno poslikati, saj, denimo, postavitev dokumenta na stekleno mizo in fotografiranje z bliskavico ne bo postreglo z berljivim rezultatom, ker bo fotografija "prežgana" in zato neuporabna. Pričakovati je, da bo podpora vsebinsko bogatim digitalnim fotografijam v prihodnje še bolj izpopolnjena, izdelovalci pa že nakazujejo soroden razvoj algoritmov, ki bodo kos tipičnim anomalijam, ki jih povzroča fotografiranje z razmeroma skromnimi fotoaparati v sodobnih mobilnikih.
Krajša lekcija iz zgodovine
Prvi uradni zaznamki, bolje rečeno patenti za tehnologijo optičnega prepoznavanja znakov, segajo v leto 1929, ko je Gustav Tauschek v Nemčiji za svojo mehansko napravo OCR prejel prvi tovrstni patent. Novotarija ni potrebovala prav dolgo, pa je našla pot čez lužo, kjer je kot prvi patent OCR prijavil Handel (l.1933), a so ZDA le dve leti kasneje nov patent OCR podelile tudi Tauscheku, ki je svojo metodo prijavil tudi onkraj luže.
Razvoj je dobil krila med drugo svetovno vojno, ko so predvsem ameriški znanstveniki, ki so med drugim razvozlali tudi japonsko diplomatsko kodo, krepko delali na samodejni obdelavi podatkov. Enega ključnih izzivov je predstavljala pretvorba tiskanih sporočil v strojni jezik za računalniško obdelavo, doseči jim jo je uspelo šele leta 1951.
Večjo komercialno rabo so sistemi OCR doživeli v 70. letih prejšnjega stoletja, ko so jih vzele za svoje poštne ustanove, kjer so skrbeli za grobo sortiranje pisemskih ovojnic in paketov. Sprva so obvladali le poštne številke, a so bili kaj hitro nadgrajeni tudi na bolj ali manj uspešno prepoznavanje naslovov.
Leta 1974 je Ray Kurzweil v svojem podjetju razvil računalniški program, ki je bil zmožen prepoznati besedila, natisnjena v večini standardnih pisav (takrat je bil nabor bistveno manjši kot danes). Kurzweil je sicer imel v mislih že naslednji projekt - izdelavo naprave, ki bo slepim brala besedilo - tega je leta 1976 tudi uresničil. Kurzweil je podjetje Kurzweil Computer Products leta 1980 prodal Xeroxu, ta pa je še nadalje razvijal tehnologije za pretvorbo papirnatih dokumentov v digitalno obliko. Ta Xeroxova podružnica je kasneje postala Scansoft in je danes znana pod imenom Nuance.
ABBYY FineReader 9.0 Professional Edition
Ukrajinski ABBYY velja za sorazmernega novinca na področju OCR, pa vendar ima podjetje goro izkušenj. Čeprav je bil njihov programski paket FineReader 9.0 predstavljen že leta 2007, moramo zapisati, da njegov uporabniški vmesnik in program na sploh deluje najsodobneje od vseh tokrat preizkušenih. Po zagonu programa nas pričaka hitri izbirni menu z najpogostejšimi možnostmi, ki so logično razporejene. Dokumente lahko zajamemo prek optičnega bralnika ali pa uporabimo prepoznave vsebine posameznih dokumentov, shranjenih na disku ali omrežnih virih ter drugih pomnilniških nosilcih. Na hitrem menuju je na voljo skeniranje v priljubljene programe iz pisarniškega paketa Microsoft Office ter v dokumente formata PDF. Prav tako je že na začetku predstavljena možnost prepoznave vsebine fotografij in prenos te vsebine v pisarniške programe. Pohvalno je tudi to, da po opravljenem zajemu dokumenta v digitalno obliko program sam odpre ustrezen program (Word, Excel, bralnik PDF dokumentov ... itd.), kjer lahko uporabnik nadaljuje svoje delo. Uporabniški vmesnik programa FineReader 9.0 je zelo lep in hkrati uporabno preprost, brez odvečnih ali motečih elementov/ukazov. V ABBYYju očitno dobro sledijo zadnji modi, saj je večina ukazov podana na kontrolniku v obliki traku, ki je podoben tistemu v Microsoft Office 2007.
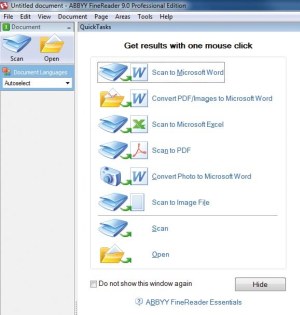
FineReader 9.0 si zapomni, kaj smo nazadnje počeli, in to nastavitev obdrži do spremembe; to je pri delu z več enakimi dokumenti priročna lastnost.
FineReader 9.0, ki ima vgrajeno podporo slovenščini in slovar slovenskih izrazov, se pri prepoznavanju besedila odlično odreže. Preizkus s prepoznavanjem člankov iz Monitorja mu je šel prav neverjetno dobro od rok, saj je bila natančnost prepoznavanja besedila po pregledanih nekaj straneh stoodstotna! Odlično je tudi ločil posamezne elemente člankov, torej slike od besedila in tabel; to priča o res zmogljivem programskem pogonu, ki so ga razvili v ABBYY-ju, in sliši na ime Adaptive Document Recognition Technology (ADRT). FineReader 9.0 podpira samodejno prepoznavanje jezika pisav, ki na naše presenečenje resnično deluje kot oglaševano. Preizkusili smo ga z dokumenti v slovenščini, nemščini in angleščini in prav vsakokrat je jezik pravilno prepoznal dokumenta. Sicer pa slovarski del programskega paketa pri ABBYY-ju nikoli ni bil problematičen, saj je podjetje nadvse uspešno na lingvističnem področju, to, da prihaja iz Vzhodne Evrope, pa je za naše govorno in pisno območje celo prednost, saj razvijalci laže razumejo naše posebnosti (ki gredo, denimo, Američanom težko v glavo).
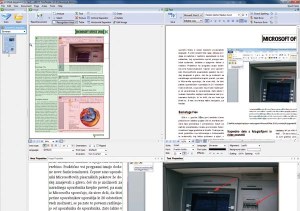
Prepoznavanje srednje zahtevnih dokumentnih struktur je za FineReader mala malica, s tira ga utegne vreči le kak zelo zahteven prelom besedila v revijah, nasičenih z barvnimi prehodi.
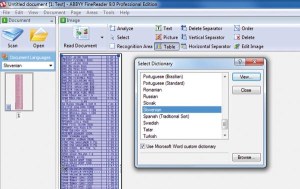
FineReader 9.0 pozna silno veliko jezikov, tudi slovenščino, z veseljem pa lahko prevzame tudi črkovalnik nameščenega programa Microsoft Word.
Pri skeniranju revij in člankov, pa tudi drugih podobnih dokumentov z veliko besedil in nekaj slik, so rezultati navdušujoči, saj program od uporabnika zahteva le malo interakcije. Ker je natančnost na visoki ravni, je tudi urejanja dokumentov malo, pa še to je zelo enostavno opravilo. Uporabnik v desnem delu programskega okna preprosto klikne prepoznani del strani in popravi ali spremeni posamezen vnos - kot bi to počel v urejevalniku besedil ali preglednic. Za številne uporabnike bo dobrodošla tudi možnost natančnega prepoznavanja pisave (ang. font matching), ki digitalizirano kopijo kar se da približa originalu. Po opravljenem optičnem pregledu dokumenta program tudi označi dele, za katere meni, da bi lahko vsebovali napake, ter tako uporabnika opozori nanje, zato je ta pri svojem delu na posameznem delu dokumenta še previdnejši.
Čim več pisav odkljukamo, tem več možnosti imamo, da FineReader zadene pravo. Ta možnost sicer malenkostno podaljša čas obdelave dokumenta, a še dodatno pripomore k natančnosti prepoznavanja.
Kot bomo videli v nadaljevanju, sodobni programi OCR z besedili iz dobrih virov nimajo večjih težav, jim pa jih povzročajo slabše skenirani dokumenti (ali dokumenti slabše kakovosti) in preglednice. Tak je bil naš primer zajetega računa iz trgovine, ki smo ga želeli pretvoriti v uporabno obliko, ki bi uporabniku dovolila praktično urejanje v programu Microsoft Excel. FineReader sicer zna prebirati različne vire dokumentov, brez večjih težav, denimo, streže datotekam s končnicami BMP, GIF, JPEG, PDF, PNG, TIFF, XPS in drugim. Toda naš račun ga je kljub temu postavil pred težak preizkus. Medtem ko je tabelarično postavitev še precej dobro zadel, so bile posamezne besede zanj prave neznanke - predvsem zaradi svetlosivih prehodov pisave, ki je posledica ne najboljšega izpisa računa v trgovini. Prav tako ni takoj zadel cen posameznih izdelkov, temveč jih je razdelil v dve različni celici (pred vejico in po njej), to pa smo z enostavnim premikom drsnika v navidezni tabeli, ki jo program postavi nad dokument, in vnovičnim branjem vsebine zlahka popravili.
Podobno se nam je godilo pri zajemu vsebine dokumenta, ki je prikazoval prodajo revij po posameznih prodajnih mestih. V tem primeru je bila tabela še gostejša, z več vnosi. Prvo skeniranje je že zelo dobro opravilo svoje delo, le polja s po več številkami so bila kljub pravilni prepoznavi neuporabna za nadaljnjo obdelavo (program je med številke preprosto vnesel presledke in s tem poskrbel za neuporabnost v Excelu, občasno pa je tri ločene enomestne številke združil v eno trimestno). Že uporaba dodatnih navpičnih separatorjev je stvari hitro postavila na svoje mesto in tabela je postala popolnoma uporabna.
Delno površen zajem računa je FineReaderju povzročil nemalo preglavic pri prepoznavanju besedila, v slovarju pa smo pogrešili nekaj preprostih besed, ki bi mu pomagale do boljšega rezultata. V takem primeru mora svoje dodati uporabnik.
Delovanje programa FineReader 9.0 je zelo hitro. To potrjuje navedbe izdelovalca, da podpira večnitnost in večjedrne procesorje. Seveda bomo večje razlike opazili šele pri obsežnejši rabi, kjer se nekaj sekund razlike na posamezen dokument sešteje v večje časovne enote.
Nuance OmniPage Professional 17
Že številka v naslovu programa OmniPage priča o tem, da ima globoke korenine. Te segajo v leto 1988, torej imajo razvijalci programa OmniPage več kot 20-letne izkušnje s tehnologijo optičnega prepoznavanja znakov. Žal pa se zdi, da jim manjka svežine, saj je ta programski paket med preizkušenimi daleč najbolj okoren in počasen. Prav tak, čeprav letos občutno osvežen, je tudi uporabniški vmesnik, ki ne sledi sodobnim trendom. Pa mu tega nikakor ne bi zamerili, če bi se odlikoval po uporabnosti, žal pa je nerazumno štorast. Res je, snovalcem je uspelo osnove spraviti v tri korake, a so ti koraki precej togi, še posebej vmesni del (za izbiro vstopne vsebine in pred načini shranjevanja), ki obravnava sam dokument. Če avtomatsko prepoznavanje dokumenta ne opravi dobro svoje vloge, je uporabnik prepuščen nič kaj prijaznim orodjarnam in neintuitivnim gumbom s kopico možnosti.
Nuance tudi sicer ne skriva, da je njihov paket namenjen bolj poslovnim kot domačim uporabnikom, to razkriva že najvišja cena med vsemi preizkušenimi rešitvami OCR. Uporabnik bo moral pred doseganjem optimalnih rezultatov preizkusiti kopico možnosti z menuja, tam bo med drugim primoran tudi ročno vklopiti slovenščino, saj OmniPage tega koraka ne zna narediti sam. Prav tako mu zamerimo, da digitaliziranih datotek po shranitvi ne odpre v programu, kateremu so namenjene, saj je pri večini uporabnikov naslednji korak povsem logičen - dodatno urejanje.
Slovenščino je pri OmniPage Professional 17 treba vklopiti ročno, tako kot FineReader pa pozna možnost natančnega prepoznavanja tipa pisave.
Vse preizkušene programe smo pred optičnim prepoznavanjem nastavili na najvišjo natančnost prepoznavanja (pri vseh je bila ta možnost že privzeta), saj nam druga skrajnost - v tem primeru hitrost prepoznavanja - ni pomenila prav veliko. OmniPage Professional 17 smo najprej postavili pred izziv prepoznavanja računa iz trgovine. Samodejna nastavitev nas je pustila hladne, saj je imel pri prepoznavi besed še za odtenek več težav kot FineReader 9.0, najbolj moteča pa je bila skoraj popolna odsotnost šumnikov (prepoznal je le redke). Je pa zato bistveno pravilneje že v prvem preizkusu prepoznal številke, čeprav je sosednji stolpec s črkami preprosto ignoriral. No, dopovedovanje programu, kaj želimo prepoznati in kako, je postreglo z vrsto frustracij (že omenjen nepraktičen uporabniški vmesnik), rezultat pa se ni bistveno spremenil.
Za prepoznavanje takih dokumentov očitno ni prave rešitve, saj so vsi trije preizkušeni programi pokazali kopico napak in zahtevali veliko popravkov s strani uporabnika. Vsekakor preveč, da bi se kdo z njimi ukvarjal ob nakupih.
Vtis je OmniPage Professional 17 popravil pri prepoznavanju tabele z več vnosi, kjer je naravnost blestel in jo najbolj dosledno preslikal v Excelovo preglednico, in to že v prvem, povsem avtomatiziranem poskusu. Tudi šumniki tokrat niso izostali. Očitno je programska koda močno optimizirana za takšne tipske dokumente, saj bi sicer, kljub več ponovitvam, le težko razložili tako velike razlike v prepoznavanju med posameznimi vrstami dokumentov.
OmniPage_tabela.jpg
OmniPage je mojster za tabele, a se žal, kot večina specializiranih rešitev, za druga področja ne zmeni preveč, oz. jih preprosto ne obvlada.
Prepoznavanje člankov iz naše revije je zopet postreglo s hladnim tušem. Čeprav je bil dokument PDF, ki je rabil kot vir, najbolj idealna rešitev za digitaliziranje v dokument z besedilom, je OmniPage svoje delo opravil precej površno. Slabo je prepoznal že strukturo dokumenta, saj je izpustil nekaj gradnikov, pa tudi pretvorba v format MS Word je bila vse prej kot uporabna. Program namreč pregibano besedilo s fotografijami in tabelami postavlja v posamezna polja in ga tako močno prelomi, težave pa mu je, začuda, povzročalo tudi besedilo, saj je dele stavkov povsem po nepotrebnem zapisal s krepko pisavo, ki je v izvirniku seveda ni bilo. Med preizkušenimi programi je bil OmniPageov rezultat pri tej pretvorbi daleč najmanj uporaben, še posebej za nadaljnje urejanje.
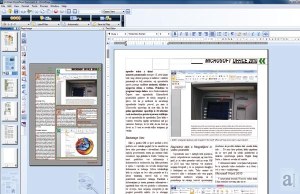
Lep zgled slabe pretvorbe v Wordov dokument, pa stran še ne velja za (naj)težji primer.
Nuance je v sedemnajstico skušal uvesti tudi nekaj lepo zvenečih novotarij, ki pa so le pogojno uporabne. Tako se namreč hvalijo, da je OmniPage Professional 17 optimiziran za prepoznavanje znakov s fotografij, posnetih z mobilnimi telefoni (z ločljivostjo okoli 2 milijona pik), in da zna zajeti dokument poslati na bralnik Amazon Kindle (priljubljen v ZDA). Medtem ko je pri fotografijah precej povprečen, pa druge možnosti nismo preizkusili, lahko pa programu pozitivno misel namenimo ob pogledu na vrsto orodij za optimizacijo toka dokumentov. Prav zato se zdi OmniPage ožje specializiran za poslovno rabo, čeprav se tudi pri nekaterih poslovnih dokumentih, kot so npr. predračuni brez uporabnikove intervencije, ni pretirano izkazal z natančnim prepoznavanjem in ločevanjem njihove vsebine.
I.R.I.S. ReadIris 11.6
Program ReadIris je še eden izmed stebrov svetovne OCR scene. Belgijski razvijalci imajo na trgu že različico 12, mi pa smo preizkusili nekoliko starejšo inačico z oznako 11.6. Program ReadIris je med uporabniki precej razširjen, saj ga HP prilaga svojim optičnim bralnikom, teh pa med uporabniki ni malo. ReadIris uporabnika še pred začetkom dela povpraša po osnovnih željah prepoznavanja in izbiri jezika, s tem pa si v nadaljevanju prihrani nekaj dela in tudi porabi manj časa.
ReadIris tako kot preostala konkurenta pozna veliko različnih formatov zapisov digitaliziranih dokumentov, tudi odprtokodnih.
Starejša zasnova programa se tudi pri ReadIris pozna na hitrosti, bolje rečeno, počasnosti delovanja, saj si za preučevanje vsebine dokumentov vzame razmeroma veliko časa. Nadaljevanje našega preizkusa je postreglo z že videnimi rezultati. Tudi ReadIris je moral priznati nemoč preprostemu blagajniškemu izpisku, kjer tako kot konkurenta ni postregel z uporabno digitalno različico.
Nekoliko bolje se je ReadIris Pro 11.6 odrezal pri transformaciji tabele v Excelovo preglednico, ki jo je na samodejni nastavitvi opravil bolje kot FineReader, a slabše od OmniPagea. Prav na tem mestu pa je vidna največja pomanjkljivost programa ReadIris, ki za razliko od konkurentov ne premore vgrajenega urejevalnika vsebine, temveč slednjo le shrani v format zapisa, izbran na začetku, ter digitalni dokument odpre v ustreznem programu, kjer uporabnik nadalje ureja vsebino. Če gre za mešanico besedila in slik, je ta možnost še sprejemljiva in delno uporabna, popravljanje "polomljenih" Excelovih preglednic pa je le in zgolj za ljudi z jeklenimi živci.
Samodejno prepoznavanje tabele včasih bolje, drugič slabše opravi svoje delo, eno pa je jasno: ReadIris kompleksnejših dokumentov vsekakor ne mara.
Prepoznavanje Monitorjevih člankov je postreglo s podobnim rezultatom kot pri programu OmniPage. To pomeni, da je delo z besedilom solidno, manjka pa veliko prefinjenosti pri samem formatiranju in postavitvi elementov znotraj dokumenta. Ukrajinski tekmec je v tej prvini bistveno boljši od vseh drugih. Ima pa ReadIris to srečo, da je najcenejši od tokrat preizkušenih rešitev in da je pogosto priložen optičnim bralnikom, pa čeprav v okrnjenih različicah, katerih zmogljivosti povsem zadostujejo potrebam povprečnega uporabnika.
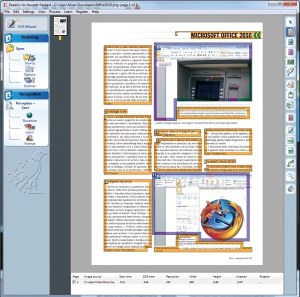
Analiza članka - tako program OCR razkosa posamezne gradnike strani - precej natančno, kajne? Zajem je nato večkrat (žal) precej slabši oz. manj natančen.
Za konec
Kaj reči za konec? Tehnologija OCR vedno ne postreže z absolutno natančnostjo, to so potrdili tudi naši preizkusi, saj vsak program prikaže nekoliko drugačne rezultate glede na enak vhodni dokument. Zato je toliko bolj pomemben del tudi t. i. postprodukcija oziroma enostavnost urejanja zajete digitalne vsebine, kjer pa program FineReader po svoji preprostosti in jasnosti rabe močno presega druga konkurenta. Tudi sicer se zdi ukrajinski izdelek daleč najprimernejši za domačo rabo, vprašamo se lahko le, koliko domačih uporabnikov bo pripravljenih odšteti nekaj stotakov za napreden program OCR.
Pri poslovni rabi so stvari še bolj jasne - vsi tokrat obravnavani ponudniki ponujajo tudi elemente za integracijo tehnologije OCR v dokumentni sistem podjetja, pogosto pa poskrbijo tudi za ustrezno implementacijo (beri: nastavitev tipskih dokumentov), po kateri je delo s temi programi bistveno olajšano. A tudi na tem področju se zdi ABBYY zaradi svojega preglednega in učinkovitega uporabniškega vmesnika najboljša rešitev, še posebej, če upoštevamo, da naloga zajemanja dokumentov po navadi pripada poslovnim asistentkam.
Pogled skozi oči izdelovalca
Z Yuriyem Korotkevichemizem podjetja ABBYY smo se pogovarjali o vlogi in možnostih optičnega prepoznavanja dokumentov, ki je še posebej problematično za Slovenijo in sosednje države, saj jezikovne posebnosti ter pisave s sičniki in šumniki spravijo na kolena marsikateri namenski program.

Kaj naredi dober program OCR?
Menim, da se dober program za optično prepoznavanje odlikuje predvsem z vsestranskostjo. Seveda je natančnost prepoznavanja ena ključnih lastnosti, a sama po sebi še ni zagotovilo za dober rezultat. Program mora predvsem ponuditi dober rezultat v kratkem času, za to pa je potreben skupek tehnologij - poleg zajema se tu izkažejo dobri algoritmi obdelave slik. Skener namreč ni več edino orodje za zajem, na tem področju začenjajo ljudje uporabljati tudi digitalne fotoaparate, ki so glede na svoje tehnične lastnosti pri rezultatih optičnega prepoznavanja zajete slike celo bolj uspešni.
Uporaben program OCR mora znati ustrezno obdelati vsa popačenja slik, nič manj pomembna ni niti natančnost rekonstrukcije dokumenta. Številni elementi besedila - tabele, slike, seznami, številke, stolpci itd. so težki za prepoznavo, podobno je tudi pri izvozu v digitalni dokument - dosegati enako postavitev je včasih prava umetnost.
Katere so ključne lastnosti, ki bi jih moral imeti vsak program OCR?
Ideal, h kateremu stremimo vsi izdelovalci, je ta, da bi program OCR logično razumel dokument. Torej, da bi hitro in pravilno prepoznal strukturo dokumenta in vse njene elemente, denimo, kaj je večstolpično besedilo, in da teče po več straneh, glave, noge, številke strani, opombe ... Vse to so elementi, ki so težji za rekonstrukcijo. Je pa res, da je za uporabnika laže urejati končni, torej digitalni dokument, zato mu mora program to omogočiti. Čeprav je danes natančnost rezultatov OCR zelo dobra, še vedno ni idealna, zato mora biti uporabniku omogočeno enostavno iskanje in odpravljanje napak v dokumentu. Črkovalnik je v sodobnem programu OCR nujnost, k višji natančnosti pripomore tudi kakovostna podpora slovarja.
Kaj pa trendi okoli uporabniškega vmesnika, ta se zdi pri vseh ponudnikih precej podoben?
Smernice glede uporabniškega vmesnika so jasne: uporabniki si želijo enostaven, a zmogljiv vmesnik, s katerim bodo vse postorili v nekaj korakih. Uporabniški vmesnik mora biti predvsem razumljiv, grafična pisanost pa nikakor ni prednost.
Kako je s šumniki in drugimi posebnimi znaki?
Podpora slovarjev je nujna za pravilno razumevanje besed. Tu pride do izraza morfologija jezika - kako se besede spreminjajo, kakšne oblike so mogoče ... Za doseganje optimalnih rezultatov s posebnimi znaki je treba veliko obdelovanja različnih besedil. Pri tem imajo veliko dela tudi lingvisti, ne le tehniki OCR. Ključno je učenje programa, da uporabniku že pokaže neprepoznane besede in besede iz slovarja, uporabnik pa nato izbere besedo ali jo sam popravi in doda v slovar. Cilj je, da uporabnik sam polni slovar s svojim besednjakom, ki je za njegovo rabo in delo najnatančnejši. Podobno velja pri pripravi okrajšav - če jih uporabnik vnese, jih program prepozna in prednostno uporablja.
Kaj pa površno napisana besedila in prostoročna pisava?
Slabo napisana besedila imajo težave pri optičnem prepoznavanju, a se je dober program sposoben učiti, četudi znak po znak. To sicer pomeni, da ga uporabnik popravi in shrani, a treba je reči, da včasih programi zmorejo prav neverjetne stvari - prepoznajo pisavo, ki bi jo vi in jaz le stežka razvozlala. Prav tako je nastala prva in neuradna podpora hebrejščini - uporabniki so sami naučili program.
Kaj pa samoučljivost programa, je realna možnost?
Morebiti v prihodnosti, čeprav zaradi same zahtevnosti morda ni najprimernejša. Veliko bolje je, da uporabnik sam nauči program glede na dokumente, ki jih uporablja. Tako je natančnost kar največja. Samodejno optimalno delovanje pa smo zato dosegli na vseh drugih področjih. Številni algoritmi so sposobni pametnega delovanja - dober program, denimo, prilagaja svetilnost dokumenta, da dobi boljšo predstavo, kaj ima pred seboj.
Menite, da bi lahko OCR v prihodnosti deloval v realnem času?
Ne vem, morda. Algoritmi so zelo zahtevni s stališča porabe sredstev. Sicer imamo že danes implementirano podporo večjedrnim procesorjem, pa tudi program zna razdeliti procesiranje dokumenta na več delov in tako pohitriti delo. To so že privzete nastavitve. Potem imamo v enačbi še skener - delo s skenerjem je lahko hitro, vendar le za manj zahtevne ali pa tipske dokumente.
Miran Varga