Kdo se boji babilonske ribice
Se še spomnite časov, ko ni bilo Googlovega prevajalnika? Ker bomo kmalu proslavili peto obletnico, odkar je ta prelomna spletna storitev začela ponujati tudi slovenščino, se spodobi pogledati, kako kaže strojnim prevajalnikom danes in česa se lahko veselimo v prihodnosti.

Google Translate je statistični strojni prevajalnik, ki se uči obrti neposredno iz podatkov, pri prevajanju pa ne uporablja slovarjev, slovničnih pravil in drugih jezikovnih virov človeške izdelave. Seveda tudi Googlov prevajalnik uporablja nekakšna pravila, vendar ta nastanejo z računalniško obdelavo velikanskih količin besedil in se večinoma nanašajo na verjetnost, da se bo določen jezikovni niz v danem sobesedilu pojavil ali ne.
O avtorici
Špela Vintar je izredna profesorica na Oddelku za prevajalstvo Filozofske fakultete Univerze v Ljubljani, kjer poučuje računalniško podprto prevajanje, lokalizacijo, prevajalske tehnologije in terminologijo. Raziskovalno se ukvarja z razvojem sistemov za samodejno luščenje znanja (terminov, definicij in semantičnih relacij) iz eno- in večjezičnih besedil, z empiričnim raziskovanjem značilnosti prevodov in razvojem slovenskega znakovnega jezika. Sodelovala je pri več kot deset nacionalnih in mednarodnih raziskovalnih projektih s področja korpusnega jezikoslovja in jezikovnih tehnologij. V prostem času organizira znanstvena in strokovna srečanja in predseduje Slovenskemu društvu za jezikovne tehnologije.
Kako deluje statistični prevajalnik
V drobovju statističnega prevajalnika sta prevodni in jezikovni model. Za prevodni model algoritem potrebuje vzporedna besedila v obeh jezikih, se pravi izvirnike in prevode, ki jih je mogoče samodejno stavčno poravnati. Iz takega vzporednega korpusa besedil je za vsako besedo izvirnega jezika mogoče izluščiti niz najverjetnejših prevodnih ustreznic, in to ne da bi karkoli vedeli o obeh jezikih. Če si predstavljamo, da se v angleško-slovenskem vzporednem korpusu evropskih besedil v izvirniku nekajkrat pojavi beseda fishing, in če smo že v fazi predobdelave vsakemu angleškemu stavku določili njegov slovenski prevod, lahko domnevamo, da se bo v naboru teh slovenskih stavkov dosledno pojavljala beseda, ki je prevod za fishing, denimo ribolov. Vsa takšna sopojavljanja se zapišejo v prevodni model kot verjetnosti, da se bo določena beseda prevedla s ciljno besedo, algoritem pa na podoben način obdela tudi verjetnosti večbesednih enot.
Google je v svojih rosnih letih kot vir vzporednih besedil uporabil dokumente Združenih narodov, kmalu pa so njihovi pajki v svoje mreže potegnili tudi dokumente drugih večjezičnih tvorb, kot je EU, različne vzporedne korpuse in tudi večjezična spletišča, za katera zna pajek hitro ugotoviti, ali gre resnično za prevod ali zgolj za tujejezično prirejeno različico.
Če bi imel prevajalnik na voljo le prevodni model, bi se posamezne besede in besedne zveze sicer pravilno prevedle, a bi bila struktura ciljnega stavka še vedno praktično identična izvirniku. Prav tako se prevajalnik zgolj na podlagi prevodnega modela težko odloča med različnimi oblikoslovnimi možnostmi prevoda: naj se red prevede kot rdeč, rdeča, rdečim, rdečimi…? Da bi bil torej ciljni stavek kar najbolj podoben običajnim slovnično pravilnim stavkom ciljnega jezika, ima prevajalnik na voljo še jezikovni model. Tudi ta se zgradi iz velikanskih količin besedil, le da je tu na voljo še bistveno več virov, saj je zanj teoretično moč uporabiti kar vse spletne strani v ustreznem jeziku. Jezikovni model zazna verjetnosti pojavitve besednih nizov, dolgih navadno od 2 do 5 besed, in tako lahko prevajalnik hitro ugotovi, da je v slovenščini kombinacija rdečih zastava bistveno manj verjetna kot rdeča zastava.
Čeprav Google o svojih tehnoloških pogruntavščinah razmeroma malo govori in piše, lahko iz vse boljših prevodov sklepamo, da se algoritmi sčasoma izboljšujejo ne le zaradi vse večjih količin učnih podatkov, temveč tudi zaradi množicanja; spletni gigant uporabniku ponuja, da strojni prevod popravi, s človeškimi popravki pa se izboljšuje prevodni model. Tudi Googlova Zbirka prevajalskih orodij (Translator Toolkit), ki ponuja okolje za urejanje in popravljanje strojnih prevodov, je namenjena predvsem zbiranju novih in kakovostnih jezikovnih podatkov.
Vsakršna naivnost v zvezi z Googlovo dobrosrčnostjo, ker svoj prevajalnik ponudi zastonj, je seveda odveč – za vsako resno rabo prevajalnika potrebujemo API, ta pa že nekaj časa ni več zastonj. Mesečna naročnina je 20 dolarjev, če s svojimi prevodi ne presežete milijon znakov (okrog 600 strani).
Statističnih strojnih prevajalnikov je danes veliko, za slovenščino je glavni tekmec Googla Microsoft s svojim Bingom. Bing deluje podobno in je naučen iz sorodnih podatkov, vendar sodeč po evalvacijah, kot bomo videli v nadaljevanju, po kakovosti še nekoliko zaostaja. V največji prevajalski »agenciji« na svetu, Generalnem direktoratu za prevajanje Evropske komisije, kjer je stalno zaposlenih 2500 prevajalcev in kjer prevedejo več kot dva milijona strani na leto, se je v zadnjem letu prav tako zgodil premik: MT@EC je statistični strojni prevajalnik, za katerega so bili uporabljeni prosto dostopni algoritmi Moses, podatke pa je prispeval gigantski korpus evropskih besedil Euramis. Modeli so bili zgrajeni za vseh 23 uradnih jezikov EU v kombinaciji z angleščino, torej tudi za angleško-slovenske in slovensko-angleške prevode. Kljub začetnemu odporu prevajalcev je MT@EC danes integriran v prevajalsko okolje in pomembno prispeva k produktivnosti.
Evalvacija strojnega prevajanja
Jezikovna industrija je ena najhitreje rastočih industrij na svetu. Ker lahko strojno prevajanje močno zniža stroške, ki jih globalna podjetja sicer namenjajo za lokalizacijo svojih proizvodov, je vprašanje, kako čim bolj objektivno oceniti kakovost strojnega prevajalnika, zelo pomembno. Ena možnost je, da strojni prevod preberejo človeški ocenjevalci in podajo svoje mnenje. V ZDA so že pred leti razvili enotno metodologijo za človeško ocenjevanje strojnih prevodov, pri čemer ocenjevalec ovrednoti dva vidika prevoda: slovnično pravilnost (fluency) in natančnost (adequacy); slednje se nanaša predvsem na zvesto ohranjanje vseh informacij, ki so bile podane v izvirniku. Težave človeškega ocenjevanja so zamudnost, saj navadno potrebujemo več ocenjevalcev, ki ocenjujejo isto besedilo; to posledično pomeni stroške; nadaljnja težava pa so še neskladja med ocenjevalci, saj so nekateri strožji do posameznih vrst napak kot drugi.
Za to, da bi se izognili takim zagatam, so se v zadnjih dvajsetih letih razvile številne metode za računalniško evalvacijo strojnih prevodov, pri katerih strojni prevod primerjamo z referenčnim (človeškim) prevodom in na različne načine izračunamo stopnjo odstopanja. Te metode, ki jim pravimo tudi metrike, se trudijo čim bolj približati človeškim evalvacijam, ob tem pa ponujajo hitrost in robustnost, saj jih lahko uporabimo s poljubnim prevajalnikom, če imamo za izvirno besedilo na razpolago tudi referenčni prevod.
Najbolj razširjene metrike so BLEU, NIST, GTM, METEOR, ROUGE, TER in TERp. Nekatere so zelo enostavne in merijo razliko med strojnim in referenčnim prevodom v smislu Levenshteinove razdalje (število potrebnih izbrisov, vstavljanj in zamenjav), druge si pomagajo tudi s pomenskimi leksikoni in so zmožne prepoznavati tudi sinonime.
Značilne napake prvih in drugih
Če malce razumemo delovanje statističnih strojnih prevajalnikov, lažje interpretiramo njihove napake. Tako nam je pri spodnjem zgledu hitro jasno, od kod Googlu zamisel, da se angleška beseda tender prevede z razpis. V spletnih virih, od koder prevajalnik črpa prevodne ustreznice, je pravljic bolj malo, pravnih in ekonomskih besedil pa zelo veliko (Zgled 1).

Zgled 1
Na naslednjem zgledu (Zgled 2) pa se dobro vidi, da statistični prevajalniki nikdar ne opravijo skladenjske analize celotne povedi, temveč prevajajo po nekaj besed dolgih koščkih. Tako je ujemanje v spolu in sklonu znotraj posamezne fraze pravilno (je ona izbrala enega), ni pa spol osebka ohranjen v vsej povedi (izbrala - mikala - tekel - dobil).

Zgled 2
Amebisov Presis, ki pri prevajanju uporablja slovnični analizator, glagolske predloge in obsežne dvojezične leksikone, ima drugačne težave (Zgled 3).
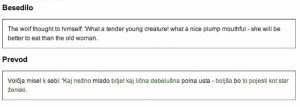
Zgled 3
Ker Presis ne uporablja statistike, se pri prevajanju ne opira na verjetnost oziroma pogostost. Angleška besedna zveza wolf thought je teoretično večpomenska, saj je lahko thought samostalnik misel ali glagol v pretekliku mislil. Na podoben način je teoretično večpomenskih veliko angleških besednih zvez; razvpiti stavek Time flies like an arrow lahko računalnik prevede kot Časovne muhe imajo rade puščico, Štopaj muhe kot puščico ali Čas leti kot puščica. Tako se Presis odloči za možno, a ne preveč verjetno izbiro volčja misel. Po drugi strani pa Presis nima težav z besedo tender, saj je v danem stavku beseda očitno pridevnik, ki ima v angleško-slovenskem slovarju možne prevode nežno, milo in razpisno. Presis ponudi prvi prevod, preostale možnosti pa so na voljo s klikom zeleno obarvane besede (Zgled 4).
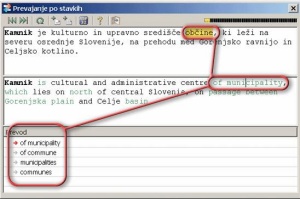
Zgled 4
Google, Bing ali Amebisov Presis?
Pred kratkim je bila na Oddelku za prevajalstvo Filozofske fakultete Univerze v Ljubljani opravljena študija, ki je ocenjevala kakovost treh največjih strojnih prevajalnikov za slovenščino, se pravi Googlovega in Microsoftovega statističnega prevajalnika ter Amebisovega Presisa, ki temelji na pravilih. Z njo smo želeli primerjati uveljavljene prevajalnike za angleško-slovensko in slovensko-angleško smer prevoda in jih oceniti tako s človeško kot z avtomatsko evalvacijo.
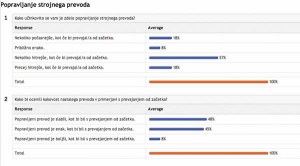
Za človeško evalvacijo je bilo uporabljenih šestdeset naključno izbranih stavkov s spletnega portala EU News, na katerem so objavljene novice z različnih področij delovanja Evropske unije. Vsak od treh prevajalnikov je prevedel po dvajset stavkov, ocenjevalci pa so dobili premešane stavke in niso vedeli, od katerega prevajalnika je kateri. Ocenjevali so slovnično pravilnost in informativnost prevoda, za slednjo so imeli vpogled tudi v izvirno besedilo. Pri avtomatski evalvaciji je bil uporabljen obsežen korpus novic EU s skupaj več kot 8000 stavki, za obe smeri prevoda pa smo računali metrike BLEU, GTM, METEOR in TERp. Pri obeh vrstah evalvacije in pri obeh smereh prevoda je bil vrstni red prevajalnikov enak: nesporni zmagovalec je Google, sledi mu Bing, na zadnjem mestu pa je prevajalnik domače izdelave, Presis.
Če smo pošteni, moramo poudariti, da morda opisani preskus ni bil povsem pravičen do Presisa, kajti oba statistična prevajalnika si pomagata z vsemi možnimi spletnimi viri, kar jih njunim pajkom uspe najti. Tako ni izključeno, da so bile vsaj nekatere izmed uporabljenih novic že uvrščene v učni algoritem ali pa je statistični prevajalnik vsaj zelo »vajen« sloga takih besedil.
Bodo računalniki prevladali?
Morda se iz zgornjih zgledov zdi, da so strojni prevajalniki še precej daleč od tega, da bi dali resnično uporabne prevode, vendar si moramo najprej priznati, da je prevajanje otroških pravljic (in literarnih besedil nasploh) opravilo, pri katerem tako prevajalci kot naročniki čutijo najmanj želje po tehnološki podpori. Po drugi strani bliskovito narašča trg tehničnih, pravnih in specializiranih prevodov, kjer so se v zadnjih dvajsetih letih trdno zakoreninila prevajalska namizja. Prevajalsko namizje (vodilni na trgu je SDL Trados, razširjena pa so še druga orodja) je specializirana programska aplikacija, namenjena profesionalnemu prevajalcu, njena glavna funkcija pa je upravljanje pomnilnikov prevodov. Poenostavljeno rečeno, tak pomnilnik nam pomaga reciklirati stare prevode, saj se vanj zapisujejo stavki in njihovi prevodi iz različnih besedil, algoritem pa med prevajanjem samodejno išče identične ali podobne že prevedene stavke, s katerimi si prevajalec lahko pomaga. Če si predstavljate, da prevajate navodila za uporabo telefona Nokia Lumia 920, pred tem pa ste prevedli že navodila za Lumio 900 in Lumio 800, je verjetno očitno, da bo ponavljanja in reciklaže precej.
Ker se statistični strojni prevajalniki učijo prav iz tipov besedil, ki se največ prevajajo, so posledično zanje tudi najbolj uporabni, poleg tega pa je načeloma strojni prevajalnik mogoče prilagoditi lastnim potrebam. V tem smislu je zasnovan tudi MT@EC pri Evropski komisiji: ker je prevajalnik naučen na zajetnih zbirkah prevodov evropske zakonodaje, se pri prevajanju sorodnih besedil dobro odreže. Tipični delovni scenarij tako ne izbira med strojem in človekom, temveč združuje vse dane vire in tehnologije v enotno prevajalsko okolje. Besedilo, ki se prevaja, se najprej analizira in primerja s pomnilnikom prevodov. Vsi stavki, za katere program najde identičen stavek v zbirki, ki ga je že nekdo nekoč prevedel, se samodejno nadomestijo. Stavki, ki so že prevedenim stavkom v zbirki zgolj podobni, se prav tako samodejno prevedejo, vendar je tak približen prevod barvno označen in ga mora prevajalec urediti. Če v pomnilniku prevodov ni nobenega podobnega stavka, se vključi MT@EC in stavek strojno prevede, tudi tak prevod mora prevajalec popraviti in potrditi.
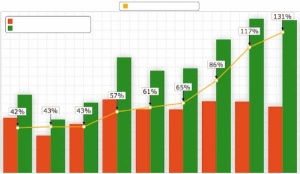
Opravljenih je bilo že več raziskav, ki so ugotavljale, ali je popravljanje strojnega prevoda bolj ali manj zamudno od prevajanja »od začetka«, pri čemer imajo jezikovni par, smer prevoda in tip prevajalnika pomembno vlogo. Večina raziskav kaže, da je pri vseh jezikovnih parih z uporabo statističnega strojnega prevajalnika mogoče prihraniti precej časa, saj se je produktivnost prevajalcev povečala za 42 (kitajščina) pa vse do 132 odstotkov (francoščina). Rezultate raziskave kaže spodnji graf, v rdečem stolpcu je produktivnost pri običajnem prevajanju, v zelenem pa produktivnost pri popravljanju strojnega prevoda.
Med evropskimi jeziki so najspodbudnejši rezultati za romanske jezike (francoščina, španščina, italijanščina, portugalščina in romunščina), najslabši pa za nekatere jezike ugrofinske skupine (madžarščina, finščina) in nemščino; pri slednji so še vedno v prednosti prevajalniki na podlagi pravil. Slovenščina je nekje vmes, a vsekakor nad »pragom uporabnosti«; tudi za naš jezik je torej z uporabo strojnega prevajanja mogoče doseči bistveno večjo produktivnost. Čeprav so profesionalni prevajalci načeloma nenaklonjeni takemu delu, pa celo anketa, ki je bila opravljena med študenti magistrskega študija prevajanja decembra 2012, kaže, da jih večina meni, da je hitreje popravljati Googlov strojni prevod, kakor pa prevajati »od začetka«, da ni končni rezultat zato nič slabši in da se jim popravljanje strojnega prevoda ne zdi bistveno manj ustvarjalno od prevajanja.
Prihodnost prevajalskega poklica je vsekakor prepletena s tehnologijami in vprašanje, ali bodo strojni prevajalniki kdaj izpodrinili ljudi, je pravzaprav napačno zastavljeno. Če, denimo, uporabite Googlov prevajalnik, da si z njim prevedete zanimivo spletno stran iz tujega jezika, ki ga sicer slabo razumete, s tem človeškega prevajalca po vsej verjetnosti niste izpodrinili. Če prevajalnika ne bi bilo, se verjetno ne bi ubadali z iskanjem prevajalske agencije, oddajo naročila, čakanjem na dostavo prevoda in plačevanjem računa. Precejšen segment uporabnikov strojnega prevajanja torej potrebuje informativne približne prevode, in potrebujejo jih takoj. Šele z rastočo kakovostjo prevajalnikov pa so ti postali tudi orodje za profesionalne prevajalce, in v ne tako daljni prihodnosti si lahko predstavljamo, da bodo morali biti slednji pravzaprav jezikovni tehnologi, ki bodo prilagajali algoritme, upravljali zbirke podatkov in statističnim orodjem dodajali jezikovne podatke, bolj rutinska opravila pa bodo prevzeli manj usposobljeni ljudje in anonimne virtualne množice.
Viri
• Amebis Presis, presis.amebis.si.
• Bing Translator, www.bing.com/translator.
• Google Translate, translate.google.com.
• Guerberof, Ana (2009). Productivity and quality in MT post-editing. www.mt-archive.info/MTS-2009-Guerberof.pdf
• Pilos, Spyridon (2012). The Machine Translation Service at the European Commission. Videolectures predavanje, videolectures.net/w3cworkshop2012_pilos_machine_translation
• Statistical Machine Traslation, www.statmt.org/
• Vrščaj, Aljoša (2011). Evalvacija strojnih prevajalnikov: diplomsko delo. Oddelek za prevajalstvo FF UL, mentorica Špela Vintar.