Kako delujejo svetovni podatkovni centri - Kje domujejo oblaki
Vse spletne strani, vsi podatki »v oblakih«, vse računske zmogljivosti za najem imajo svoje mesto v podatkovnih centrih, ki stojijo po vsem svetu in poganjajo infrastrukturo, brez katere si danes ne predstavljamo več življenja. Postaviti en strežnik res ni huda znanost, povsem drugače pa je poskrbeti za usklajeno delovanje milijonov procesorjev in diskov, ki brnijo v več halah na različnih tektonskih ploščah.
Enačba je preprosta. V veliko betonsko stavbo vodimo elektriko, iz nje odvajamo toploto. Obenem vanjo pošiljamo podatke, ki se premeljejo in uskladiščijo, nazaj pa dobimo še več podatkov. Toda kot ve povedati vsak inženir, je prehod na večje velikostne razrede (scale-up) vedno izziv, saj se pojavijo problemi in okoliščine, ki jih prej ni bilo. Ne moremo zgolj povezati tisoč računalnikov in dobiti podatkovnega centra.
Podatkovni center je po definiciji vsak obrat, kjer domujejo računalniški sistemi. Poslovni (enterprise) podatkovni centri so prilagojeni potrebam in segajo od majhnih strežniških sobic z enim UPSom do velikih strogo zastraženih obratov z desettisoči strežnikov, ki porabijo toliko energije kot manjše mesto. Osredotočili se bomo na centre, ki imajo več kot deset tisoč strežnikov, ki se danes imenujejo tudi hipercentri (hyperscale data center). Manjši centri lahko uporabljajo komercialno opremo, v hipercentrih pa je precej nestandardnih in prilagojenih rešitev, ki so optimalne za konkretni primer.
Pod izrazom podatkovni center si navadno predstavljamo zgolj veliko halo s strežniki, a je v njej še precej več. Poleg prostorov, ki so zaradi ljudi (garderobe, menze, varnosti), tudi tehnologija pogojuje še vrsto podpornih sistemov. To so med drugim lastna razdelilno transformatorska postaja, dizelski generatorji, UPSi, strojnica s hladilnim sistemom, zunanje hladilne enote itd. Veliki podatkovni centri so kot mesto v malem, le da imajo bolj malo prebivalcev.

Microsoft podatkovni center za Azure v Dublinu. Slika: Microsoft.
Računalniška oprema
Srce vsakega podatkovnega središča je računalniška oprema. V osnovi gre za strežnike (matična plošča, procesor, pomnilnik, disk, povezljivost, lahko tudi grafični čip za GPGPU), ki jih sestavljajo običajne poceni komponente. Včasih so bili podatkovni centri polni eksotičnih in dragih komponent, danes pa se zaradi velikosti najbolj splača vgrajevati poceni komponente množične proizvodnje, ki jih je mogoče poceni menjati. Programska oprema tehnične podrobnosti tako ali tako abstrahira.
Strežniki so nameščeni drug nad druge v omari (rack), te so med seboj povezane v gruče (cluster). Kakšno opremo ima posamezen podatkovni center, je povsem odvisno od njegovega namena in lastnika. Nekateri uporabljajo, kar je mogoče kupiti, drugi dizajnirajo in naročijo posebej prilagojeno opremo. Google je tak primer, saj uporablja tako posebej prilagojeno strojno opremo kakor lastno programsko opremo. Colossus je njihov podatkovni sistem, Google F1 je distribuirana zbirka podatkov (namesto MySQL), Google Web Server je lasten spletni strežnik na Linuxu itd.

Hala s strežniki v Googlovem podatkovnem centru v Oklahomi. Slika: Google.
Povezljivost
Notranja povezljivost je ključna, saj je v enem centru lahko več deset tisoč strežnikov, ki komunicirajo z več kot petabiti na sekundo, to je več od prometa po celotnem internetu. Ne glede na to, ali gre za velik Googlov podatkovni center ali za gostovanje več različnih najemnikov, je malo programov, ki se izvajajo v le enem fizičnem strežniku. Zato je hitra komunikacija nujna.
Izbor je stvar financ. Gigabitna stikala z 48 vrati so danes poceni, stanje pa je drugačno, če želimo stikala z več vrati in višjo prepustnostjo. Za 10-krat višjo prepustnost plačamo okrog 100-krat več. Zaradi tega so centri povezani hierarhično. Povezave med strežniki ene omare (rack) so urejene prek cenejših stikal, povezave celotnih gruč (cluster) pa so dražje.
Dolgoletno povprečje kaže, da na leto odpove 1-2 odstotka diskov. V velikem podatkovnem centru s petabajti prostora to pomeni, da bodo okvare vsakdanji pojav.
Čeprav centri načeloma strežejo zahtevam, ki prihajajo iz geografske bližine, morajo med seboj komunicirati. Google na primer uporablja lastno omrežje z imenom B4 (WAN interconnect), ki omogoča komunikacijo podatkovnih centrov med seboj. Zlasti storitve YouTube, iskanje, zemljevidi, Photos, Hangouts ter posodobitve za Android in Chrome terjajo veliko zmogljivosti. B4 teče na arhitekturi SDN (Software Defined Networking). Uporablja protokol OpenFlow na poceni preprostih usmerjevalnikih, ki se množično izdelujejo, in optimizacijski protokol TE (Traffic Engineering). B4 ni del javnega interneta. Več podrobnosti najdemo v članku o Googlovih zaposlenih B4: Experience with a Globally-Deployed Software Defined WAN. Imajo pa tudi B2, ki nosi promet, ki je namenjen na javni internet.
Shranjevanje podatkov
Posamezni diski (ali SSDji) so lahko povezani neposredno v posamezne strežnike in dostopni prek globalnega distribucijskega sistema (npr. Googlov GFS in Colossus), lahko pa so del namenskih polj NAS (network attached storage) ali SAN (storage area network). Navadno je ločitev podatkovnega dela (NAS) od računskega enostavnejša rešitev, je pa počasnejša in prostorsko potratnejša. Pri NAS je za redundanco poskrbljeno na ravni posamezne naprave (RAID), pri GFS pa s kopijami podatkov na več strežnikih. Tak sistem je robusten in odporen za izpad posameznih strežnikov ali celotnih omar, predvsem pa je cenejši, hitrejši pri branju in zanesljivejši, zato ga uporablja tudi Google.
Po ocenah s konca leta 2017 so podatkovni centri globalno porabili 416 TWh energije, kar ustreza moči približno 50 GW, to pa približno ustreza porabi električne energije v vsej Franciji.
Lastniki velikih podatkovnih centrov pogosto uporabljajo sorazmerno poceni diske, ker se pri več milijonih diskov tudi pri najdražjih modelih ni mogoče izogniti vsakodnevnim okvaram. Zato je ekonomičneje uporabiti bistveno cenejše modele, ki se kvarijo malo pogosteje. Menjave bodo tako ali tako potrebne. Najcenejši modeli za domačo rabo sicer niso namenjeni neprestanemu delovanju, zgolj nekoliko dražji nearline diski in najcenejši enterprise diski pa so čisto dovolj. V zadnjem času postajajo tudi SSDji cenovno sprejemljivi in zato uporabni, kjer je intenzivnost pisanja in branja (I/O) visoka.
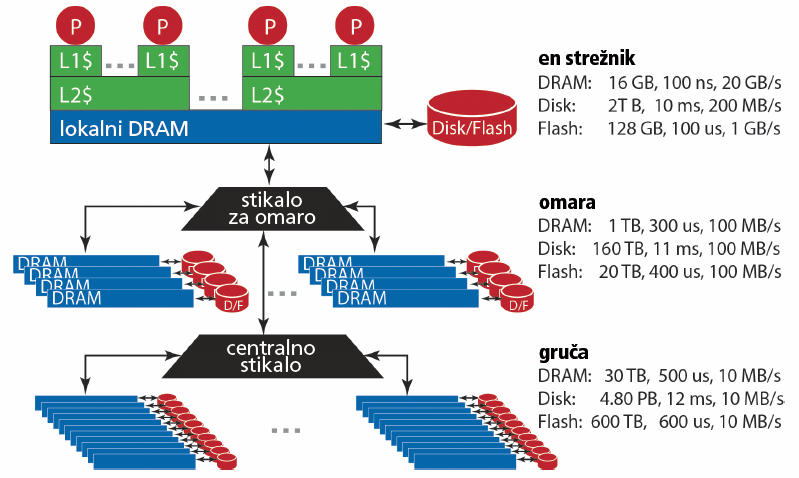
Hierarhija shranjevanja podatkov. Slika: Barroso et al., The Datacenter as a Computer, 2013.
Napajanje
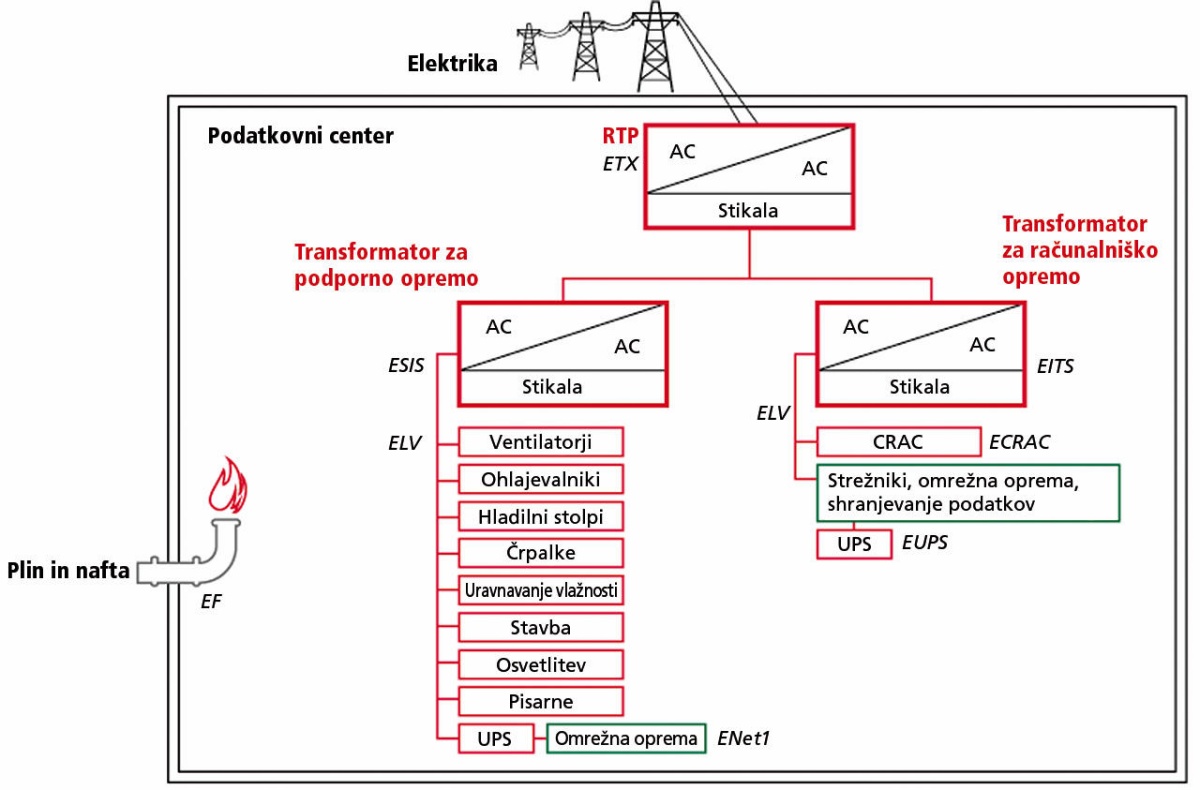
Podatkovni centri lahko porabijo tudi nekaj sto megavatov energije, zato seveda nimajo 230 V priključka. Priključeni so na visokonapetostne vode (npr. 110 kV), ki se na lastni razdelilni transformatorski postaji transformira na srednjo napetost (nekaj kilovoltov). Ta se potem transformira še enkrat do omrežne napetosti, ki teče do UPSov (uninterruptible power supply). Ti jo pretvorijo v enosmerno napetost in z njo tako polnijo akumulatorje kakor prek razsmernika znova pretvarjajo v sinusno izmenično napetost (v Evropi običajno trifaznih 400 V, ker ena faza in nevtralni vodnik dasta efektivnih 230 V), ki se uporablja za dejanski pogon računalniške opreme. Za to skrbijo PDU (power distribution unit).
Podatkovni centri morajo biti sposobni delovati, tudi če se dobava električne energije prekine. V ta namen so na UPSe priključeni tudi dizelski generatorji. Namen UPSov ni poganjati podatkovnega centra brez električne energije. Njihova funkcija je glajenje napetosti (dvojna pretvorba AC-DC-AC) in premostitev sekund med izpadom napajanja in vključitvijo dizelskih generatorjev.
Vsak dejanski strežnik ima potem še svoj napajalnik. V zadnjem času se pojavljajo tudi rešitve z visoko enosmerno napetostjo (HVDC), ker so tako izgube pri distribuciji in zadnji transformaciji nižje.
Energetska učinkovitost
Eden izmed ključnih dejavnikov vsakega podatkovnega centra je energetska učinkovitost, ki predstavlja levji delež stroškov obratovanja. Neil Rasmussen iz Schneider Electric je že leta 2011 ocenil, da približno polovico vseh stroškov odpade na energijo za pogajanje strežnikov, opremo za napajanje, hlajenje in nadzor.
Termodinamično gledano, niso podatkovni centri nič drugega kot orjaške elektropeči. Vsa energija, ki jo za delovanje porabi računalniška oprema, konča svojo pot kot toplota. Toda ker ta elektropeč ne deluje pri visokih temperaturah, moramo vso ustvarjeno toploto učinkovito odstranjevati.
Energetsko učinkovitost je težko smiselno definirati. Intuitivno bi jo želeli podati kot energijo, ki jo sistem potrebuje za obdelavo neke količine podatkov (na primer petabajta), a niti dva sistema ne prežvekujeta enakih podatkov. Podjetja se navadno hvalijo z nizkimi vrednostmi PUE, a zgodba je širša.
Učinkovitost sestavljajo (1) PUE (power usage effectiveness), (2) SPUE (server PUE) in (3) učinkovitost obdelave podatkov. PUE podaja razmerje med vso energijo za obratovanje centra in energijo, ki jo porabijo računalniške komponente. Razlika odpade na hlajenje, prezračevanje, razsvetljavo, črpalke, UPSe in drugo (overhead). Medtem ko je bil še leta 2006 PUE nad 3 povsem običajen, danes podjetja tekmujejo v nižanju PUE. Leta 2012 je bil povprečni PUE 1,8-1,9, današnje Googlovo povprečje pa je 1,12. To pomeni, da le 12 odstotkov energije porabijo za podporne sisteme. Tudi drugi velikani omenjajo vrednosti pod 1,2, le da niso tako transparentne. Prav tako so razlike, kaj se šteje pod podporne sisteme – ali so izgube na transformatorjih in kablih del porabe računalniške opreme ali ne? Prav tako je PUE močno odvisen od dejanske trenutne porabe energije.
Električne izgube niso velike. Transformacija visoke napetosti v srednjo napetost in potem do običajnih ravni prinese manj kot odstotek izgube, UPSi delujejo z izkoristkom 88–98 odstotkov, še dva ali tri odstotke izgubimo po vodnikih, saj so centri veliki, prenašanje nizkih napetosti na dolge razdalje pa neučinkovito. Od dva- do trikrat več energije se porabi za hlajenje, kjer so možni največji prihranki. Ta del enačbe je tudi najbolj občutljiv za okoljske vplive, zato niha tako med različnimi lokacijami na svetu kot med letnimi časi. Več o hlajenju v nadaljevanju.
Drugi faktor SPUE podaja informacijo o učinkovitosti same opreme in je definiran analogno kakor PUE. Gre za razmerje med celotno porabo energije enega strežnika in koristno energijo (za ploščo, diske, procesor, kartice itd.). Razlika so notranje izgube, poraba za transformiranje, interno hlajenje (ventilatorji). Danes SPUE dosegajo vrednosti pod 1,10. Googlovi centri dosegajo kombiniran TPUE (total PUE, torej produkt PUE in SPUE) 1,3.
Najpomembnejši prihranki pa se skrivajo v potratnosti obdelave podatkov. Po Moorovem zakonu se računska moč povečuje približno eksponentno, poraba energije in prostora pa seveda ne. Zmanjšuje se litografija (danes 7 nm ni nič nenavadnega, napajalne napetosti padajo itd.). Današnji procesor s 100 W postori milijonkrat več kot pred dvajsetimi leti. Žal se tudi tu napredek upočasnjuje, ker s trenutno tehnologijo počasi trkamo na fizikalne omejitve (velikost atoma). Za nadaljnji napredek bo potreben konceptualni preskok, podobno kot niso do onemoglosti izboljševali elektronk, temveč so izumili tranzistorje. Učinkovitost obdelave podatkov lahko ocenimo s sintetičnimi testi, denimo LINPACKom (katerega rezultate dvakrat na leto najdemo tudi na lestvici najhitrejših superračunalnikov Top 500), a to je zgolj približek. Vsak podatkovni center je prilagojen obdelavi svojih podatkov, ne sintetičnim testom.
Po ocenah s konca leta 2017 so podatkovni centri globalno porabili 416 TWh energije, kar ustreza moči približno 50 GW, to pa približno ustreza porabi električne energije v vsej Franciji. Posamezen Amazonov ali Googlov center zlahka porabi do 500 MW električne energije. V zadnjem času se je okrepilo zavedanje, da je pomemben tudi vir energije, zato podjetja poizkušajo uporabljati čim več energije iz obnovljivih virov. Google je leta 2017 prvikrat uporabljal izključno obnovljive vire energije (glede na pogodbe z dobavitelji).
Cilj modernih podatkovnih centrov je zmanjšati porabo energije za podporne sisteme. Povzeto po: Google.
Hlajenje
Izjemno pomemben del dizajna vsakega centra je hlajenje, ki tudi bistveno vpliva na stroške. Ni presenetljivo, da ima Google najvišji PUE v singapurskem centru (1,18), najnižjega pa na Finskem (1,09). Če upoštevamo, da približno četrtino izgub odpade na električne komponente, ki so podobne povsem po svetu, lahko čez palec ocenimo, da singapurski center porabi trikrat več energije za hlajenje od Finskega. To pa ni poceni.
Ko je Facebook leta 2010 napovedal 450 milijonov vreden center v Forest Cityju v Severni Karolini, je gradnja prinesla veliko gospodarske aktivnosti. Po letu 2012, ko je bila končana, pa je v centru redno zaposlenih 21 ljudi, še toliko pa imajo zunanjih sodelavcev.
Pri snovanju načina hlajenja moramo določiti način odstranjevanja toplote, način distribucije zraka v prostoru in tudi lokacijo hladilne enote. Pri distribuciji zraka imamo tri možnosti: pomešano (flooded), usmerjeno (targeted), nadzorovano (contained). V prvem primeru črpamo v prostor hladen zrak in iz njega toplega, z mešanjem v prostoru pa se ne ukvarjamo. Taka rešitev je najmanj učinkovita. Če tok zraka nekako usmerimo, zmanjšamo mešanje in dobimo učinkovitejše hlajenje. Pri nadzorovanem toku zraka pa povsem preprečimo mešanje med toplim in hladnim zrakom. Ker imamo tako pri dovodu kakor odvodu zraka na voljo te tri možnosti, je na voljo skupaj devet kombinacij. Iz praktičnih razlogov se po navadi uporablja usmerjena ali nadzorovana distribucija zraka samo na eni strani (recimo na odvodu – »vroča cona«), kar zadostuje.
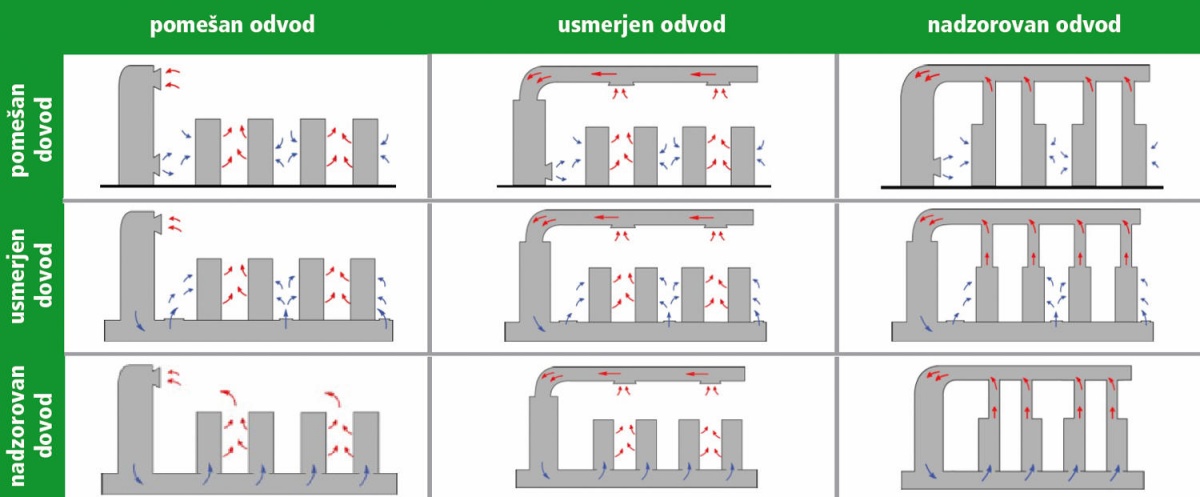
Osnovni načini distribucije zraka v halah s podatkovnimi centri. Slika: Neil Rasmussen, The Different Types of Air Distribution for IT Environments.
Naslednji pomemben dejavnik je odstranjevanje toplote. Za prenos toplote potrebujemo medij, ki je lahko zrak, lahko pa tudi kaj drugega. Poznamo trinajst osnovnih načinov, ki se razlikujejo po načinu prenosa toplote z računalniških komponent, medija in načinu prenosa toplote v zunanjost. Na notranji strani imamo lahko CRAC (computer room air conditioner), ki deluje kot kompresor pri klimatski napravi, CRAH (computer room air handler), kjer se zrak hladi ob stiku s hladnimi kačami (spirale), ali preprost zajem hladnega zraka iz zunanjosti. Medij za prenos toplote je zrak, ohlajena voda, glikol ali hladilna tekočina. Na zunanji strani toploto odvajamo z evaporacijskim odhlapevanjem, hladilnimi stolpi, preprosto z zrakom itd. V praksi nikoli ne pihamo hladnega zraka iz zunanjosti neposredno v notranjost, ker bi s tem tvegali onesnaženje in vnos vlage – hladno zunanjost uporabimo kot rezervoar.
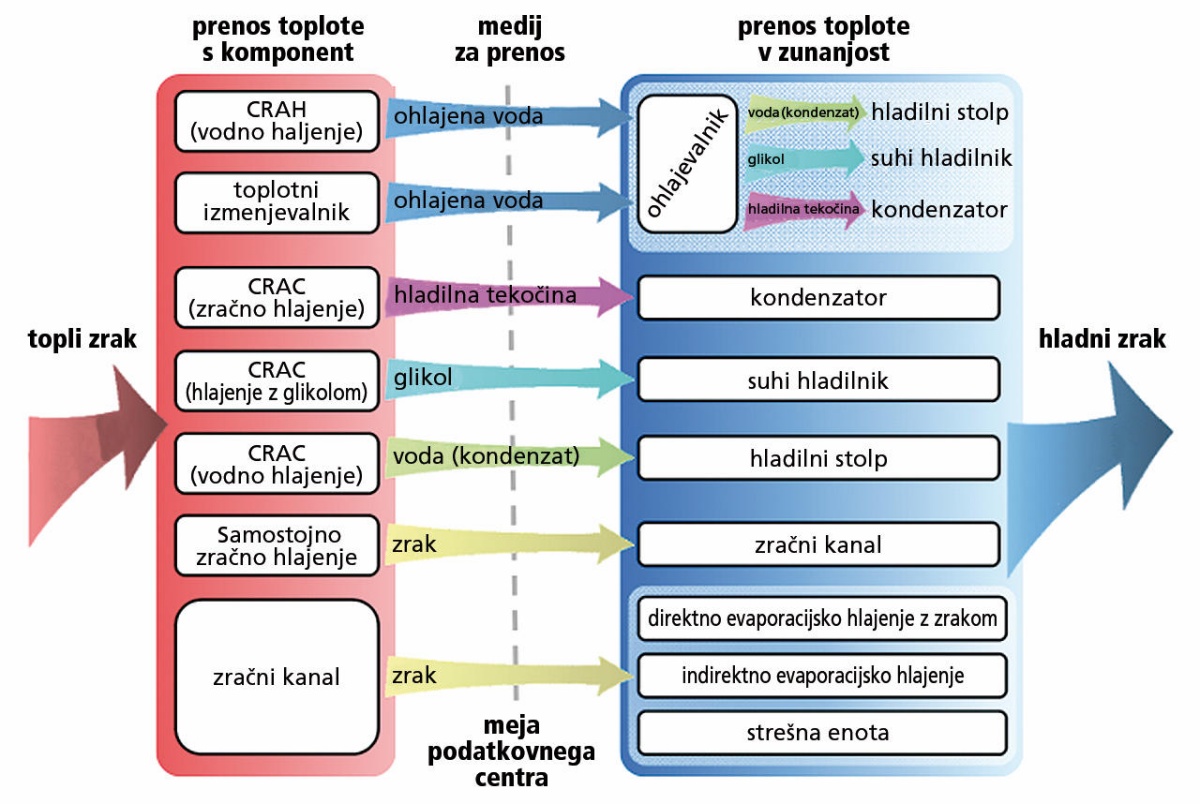
Načini za odstranjevanje toplote iz podatkovnih centrov. Slika: Neil Rasmussen, The Different Technologies for Cooling Data Centers.
Eden najpogostejših načinov so dvignjena tla ter ločitev hladnih in toplih con. Klimatske naprave dovajajo hladen zrak pod dvignjena tla, na katerih so strežniki, od tam ga ventilatorji potisnejo kvišku. Ohlajeni zrak potuje do strežnikov in skoznje, potem pa kot topli zrak zapušča prostor na vrhu hale. Za večjo učinkovitost imamo ločene hladne in tople cone, tako da so strežniki z eno stranjo obrnjeni v hladno cono (od tam vlečejo zrak) in ga izpihujejo v toplo cono.
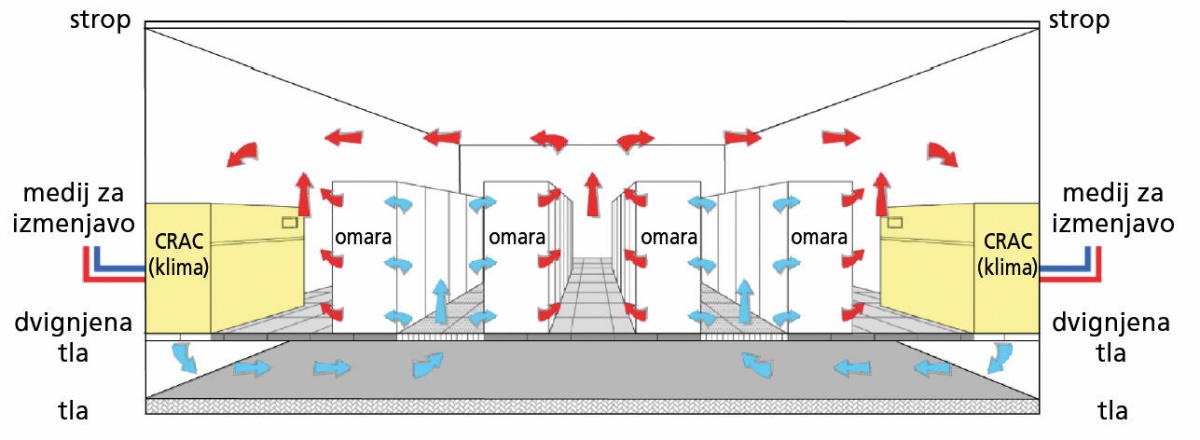
Najpogostejši način hlajenja vsebuje dvignjena tla ter hladne in tople cone. Slika: Barroso et al., The Datacenter as a Computer, 2013.
Okvare
Računalniške komponente se kvarijo. Doma je to redka nevšečnost, v velikih sistemih pa statistična gotovost. Vzemimo za primer diske, katerih zanesljivost že več let sistematično spremlja BackBlaze. Dolgoletno povprečje kaže, da na leto odpove 1-2 odstotka diskov. V velikem podatkovnem centru s petabajti prostora to pomeni, da bodo okvare vsakdanji pojav. Podobno velja tudi za druge komponente. Tudi če uporabljamo najboljše strežnike s povprečnim časom med napakami 30 let (MTBF = 10.000 dni), bo v podatkovnem centru z 10.000 vsak dan odpovedal eden! Če k temu dodamo še programsko opremo, ki lahko zataji, saj navadno teče več slojev ali programskih modulov (virtualizacija), ki ima vsak svoje hrošče, postane jasno: sistem mora delovati tudi, ko odpovedujejo posamezni deli. To je tudi učinkoviteje, saj so »povprečne« komponente bistveno cenejše od najbolj zanesljivih, manko pa nadoknadimo s kvantiteto. Tako postane zmožnost strojne opreme, da sama odpravlja napake (pomnilnik ECC, polja RAID), manj bistvena. Če njena cena ni bistveno višja (npr. ECC), se jo seveda splača uporabiti, drugače pa poskrbimo zgolj, da imamo urejeno zaznavanje napak, programska oprema pa bo našla pot okrog okvarjenih strežnikov.
Tudi če uporabljamo najboljše strežnike s povprečnim časom med napakami 30 let (MTBF = 10.000 dni), bo v podatkovnem centru z 10.000 vsak dan odpovedal eden!
Napake na ravni storitve se razdelijo v štiri kategorije: nepopravljiva okvara podatkov (corruption), nedosegljivost (unreachability), zmanjšana učinkovitost (degraded performance) in prikrite končnim uporabnikom (masked). Raziskave kažejo, da lahko zgolj kakšnih 25 odstotkov težav pripišemo odpovedim strojne opreme – za preostanek so krive človeške, programske ali omrežne težave.
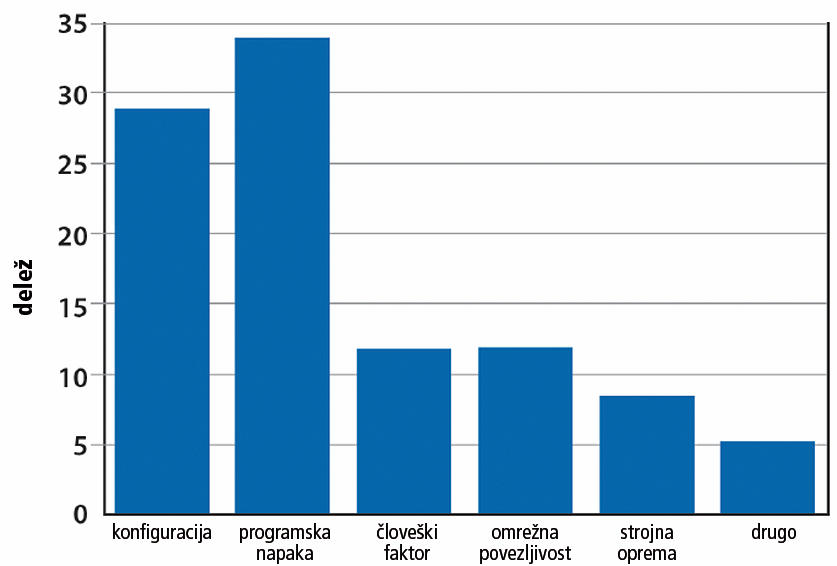
Razlogi za motnje dostopnosti storitev pri Googlu. Podatki: Robert Stroud.
Najpogostejša motnja je vnovični zagon posameznega strežnika. Pri Googlu so ugotovili, da se je v šestih mesecih približno polovica strežnikov v centrih vsaj enkrat spet zagnala. Razloge je mnogokrat težko najti, ker je hrošče včasih težko razlikovati od prehodnih strojnih napak. Statistika kaže, da lahko zgolj 10 odstotkov novih zagonov pripišemo težavam z diski in pomnilnikom, preostanek pa ni diagnosticiran.
Varnost
Ker so podatkovni centri ključni za delovanje kopice internetnih storitev in ker v resnici večina zaposlenih v na primer Googlu tam nima kaj iskati, tja niti ne morejo. Zelo malo jih ima pravico sploh vstopiti v podatkovni center. Ravni varovanja je več. Že pri vstopu na samo posest je treba vratarju pokazati izkaznico, ki mora biti na seznamu. Nadaljnje kontrole so še pri vstopu v zgradbo, vstopu v koridorje ob podatkovnem centru in pred vstopom v halo s strežniki. Da pridemo tja, se je treba večkrat vpisati, iti mimo biometričnih senzorjev in več varnostnikov. Celotna posest je zastražena kot kakšna vojaška postojanka.
To seveda ni vse!
Na tako malo prostora je nemogoče napisati vse o tako obširni temi, kot so podatkovni centri. Ti so si med seboj tako različni, kakor so posebne njihove naloge in različni njihovi lastniki. Nekateri so o svojih centrih bolj gostobesedni (npr. Google), drugi so zelo skrivnostni (npr. Apple). Smo pa poizkusili predstaviti osnovna načela, ki veljajo v vseh centrih ne glede na njihovo velikost. Princip je isti, vse ostalo so nianse (je povedal že Balašević).
Lokacije podatkovnih centrov
Pri izbiri lokacije za gradnjo podatkovnega centra je treba upoštevati več dejavnikov, med katerimi so najpomembnejši podnebje (zaradi hlajenja), cena in v zadnjem času tudi »zelenost« električne energije, elementarna tveganja (tektonika, bliža letališč, vojaških postojank, kemične industrije itd.), lokacija uporabnikov oziroma strank ter delovna sila (izobraženost, cena).
Zato ni presenetljivo, da je največ podatkovnih centrov v ZDA in severni Evropi. Google je le tri od svojih petnajstih centrov postavil drugod (Čile, Tajvan, Singapur), vsi drugi so v ZDA ali severni Evropi. Facebook ima celo vse svoje podatkovne centre v ZDA in Evropi, najema pa nekaj kapacitet tudi v Aziji. Amazon ima zaradi narave svojih storitev – ponuja računske zmogljivosti – nekoliko bolj razgiban vzorec s centri tudi v Avstraliji, Indiji in na Kitajskem, a še vedno prevladujeta Evropa in ZDA.
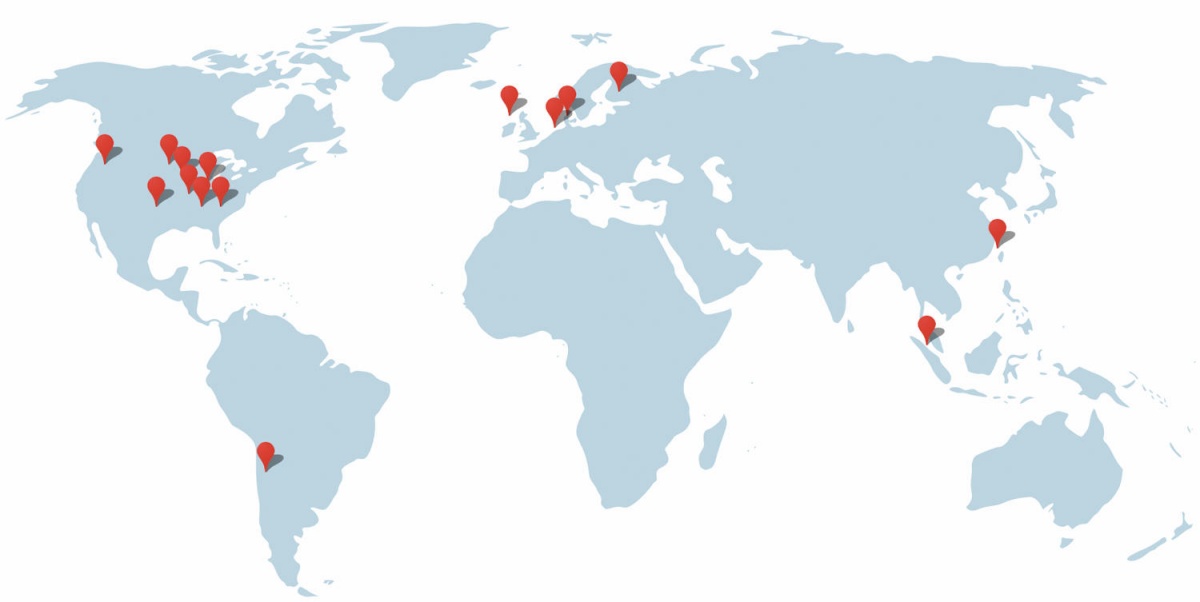
Google ima petnajst podatkovnih centrov, še dva (na Danskem in v Nevadi) sta v gradnji. Slika: Google.
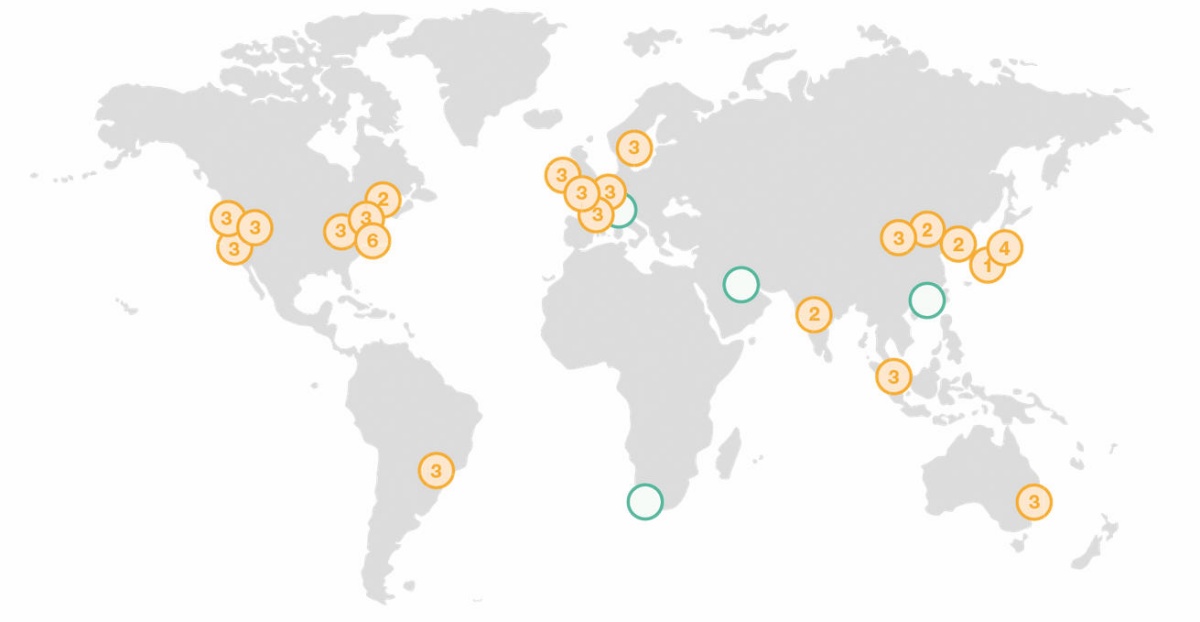
Amazon ima svoje podatkovne centre po vsem svetu, prihajajo (zeleni krožci) celo v Afriko. Slika: Amazon.
Ali računalniki sploh znajo šteti?
Če si pozorno ogledamo kakšen zelo priljubljen videoposnetek po YouTubu ali kontroverzno objavo po Twitterju, bomo videli zanimive stvari. Števec ogledov ali deljenj se načeloma povečuje, včasih pa tudi usahne ali zastoji. Kaj se dogaja? Je šteti zares tako težko?
Na velikih sistemih je. Enostavno opravilo, kot je povečanje števca, je sestavljeno iz vsaj treh operacij. Iz zbirke podatkov ne moramo prebrati vrednosti števca, mu prišteti ena in podatka zapisati nazaj. Ob velikem navalu en sam strežnik tega ne bi zmogel, zato bi začeli izgubljati oglede. Če sistem prejme hkrati dva zahtevka in obema odgovori z isto vrednostjo, bosta oba prištela ena in zapisala (še vedno enak) rezultat drug čez drugega. Temu pravimo tekmovalna okoliščina (race condition).
Štetje ogledov je pomembno, ker je od tega odvisno plačilo, ni pa tako pomembno, da bi ga izvajali v realnem času. Važno je, da prej ali slej pridemo do pravilnega odgovora, ne potrebujemo pa ga v vsakem trenutku (eventual consistency). Zato svoje oglede sešteva vsak strežnik, ki streže videoposnetek delu gledalcev, potem pa se periodično usklajujejo vrednosti v centralni zbirki podatkov.
Podobno velja tudi za prikazovanje podatkov. Nima smisla, da bi vsak gledalec poslal svojo zahtevo, naj iz centralne baze prejme podatke o številu ogledov. Ta podatek periodično preberejo vmesni strežniki in si ga zapomnijo (caching) ter posredujejo vsem, ki v tem času od njih dobijo videoposnetek. Ker ob vsakem ogledu komuniciramo z drugim strežnikom, dobimo vsakokrat malce drugačen odgovor.
So pa primeri, ko niti to ni dovolj in resnično potrebujemo povsem zanesljivo informacijo v realnem času. Če kupujemo vozovnice ali vstopnice s sedežnim redom, jih ne moremo prodati dvakrat. Taki sistemi so zato počasnejši, včasih nas celo postavijo v čakalno vrsto (queue), če je obremenitev previsoka.
Zadostuje že malo ljudi
Čeprav so podatkovni centri večstomilijonske investicije, ki strežejo podatke milijonom uporabnikov, v njih dela sorazmerno malo ljudi. Med gradnjo posredno podpirajo več tisoč zaposlitev v okolici, kasneje pa imajo neposredno zaposlenih zelo malo. Veliki center ima do 100 zaposlenih, ki pokrivajo vse naloge za nepretrgano (24 ur na dan) obratovanje.
Ko je Facebook leta 2010 napovedal 450 milijonov vreden center v Forest Cityju v Severni Karolini, je gradnja prinesla veliko gospodarske aktivnosti. Po letu 2012, ko je bila končana, pa je v centru redno zaposlenih 21 ljudi, še toliko pa imajo zunanjih sodelavcev.
Microsoftov podatkovni center Alluvion v Iowi je stal 1,1 milijarde dolarjev, obvezani (zaradi subvencij) pa so bili zaposliti 84 ljudi. Microsoftov center na Finskem skupno zagotavlja delo 200 ljudem, torej redno zaposlenim in zunanjim sodelavcem.
Gradnja podatkovnega centra v državi je vsekakor dobrodošla investicija, a njen vpliv na gospodarstvo ni tako velik, kot bi naivno pričakovali. Gre za infrastrukturo, pravi dobički pa se ustvarjajo drugje (recimo v irskih podružnicah, kjer so sedeži za Evropo).