Kako deluje COVID sledilnik - Podatkovna odličnost v boju z epidemijo
Ena najbolj obiskanih spletni strani v zadnjih mesecih, ki je za Slovence postala de facto vir podatkov o poteku epidemije, je Sledilnik. Za stranjo, na kateri so preverjeni podatki profesionalno predstavljeni, stoji skupnost več kot 250 prostovoljcev, ki ure in ure dnevno posvečajo razumevanju dogajanja in informiranju javnosti. Mimogrede pa so še dokazali, da so odprta orodja in razvoj omogočili tehnologijo uporabiti sleherniku. Sledilnik mesečno stane manj kot zaboj piva.
Če izredne situacije iz ljudi izvabijo najboljše in najslabše, je projekt COVID-19 Sledilnik gotovo v prvi skupini. Odprtokodni in odprtopodatkovni projekt je marca letos začel Luka Renko, da bi do vzpostavitve profesionalnega sistema v kateri do (državnih) instituciji zbiral podatke o stanju epidemije koronavirusa in jih delil z javnostjo. A tekli so tedni in meseci, epidemija je vmes splahnela in se v naslednjem valu vrnila še v okrepljeni obliki, Sledilnik pa je vztrajal in rasel. Pri projektu, brez katerega bi si danes težko predstavljali spopadanje z epidemijo, sodeluje že več kot 250 ljudi. Programerji, statistiki, prevajalci, spletni oblikovalci, komunikatorji, fiziki, matematiki, biologi, zdravniki, epidemiologi in številni drugi profili, denimo psihologi, sociologi ter celo režiserji, že devet mesecev v projekt vlagajo stotine ur svojega časa.
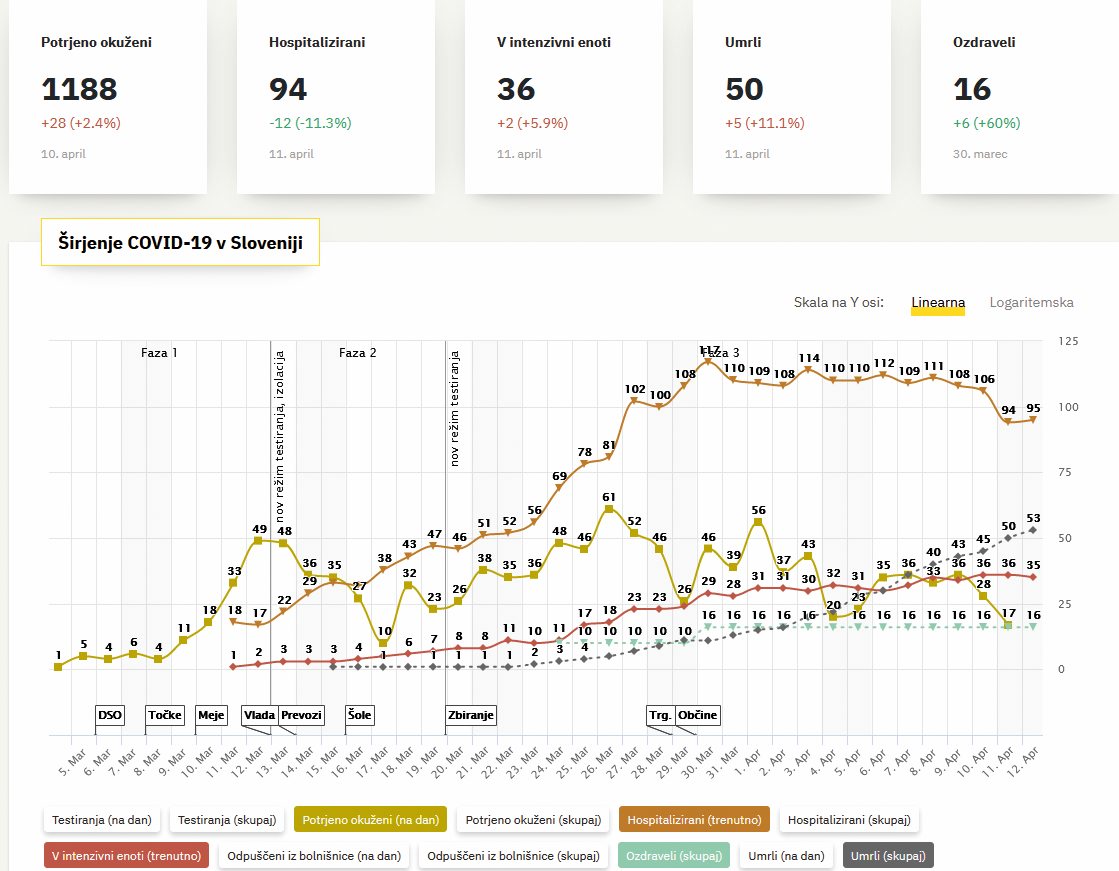
Sledilnikova spletna stran aprila letos.
Spletna stran Sledilnik domuje na naslovu covid-19.sledilnik.org, kjer najdemo izčrpno, sistematično in pregledno predstavitev podatkov o epidemiji. Ker si lahko na začetni strani ogledamo število aktivnih primerov, hospitaliziranih in na intenzivni terapiji, umrlih in odpuščenih, vse skupaj razvrščeno tudi po demografiji (občine, starosti itd.) in vizualizirano z različnimi grafi in zemljevidi, bi za projektom pričakovali velikansko bazo, zmogljive strežnike, hierarhično organiziranost armade programerje in ogromen proračun. Resnica je bistveno bolj prozaična. Luka Renko je v neko tabelo na Google Sheet vpisal prvi potrjeno okuženi primer 4. marca 2020, iz česar je nastal Sledilnik.
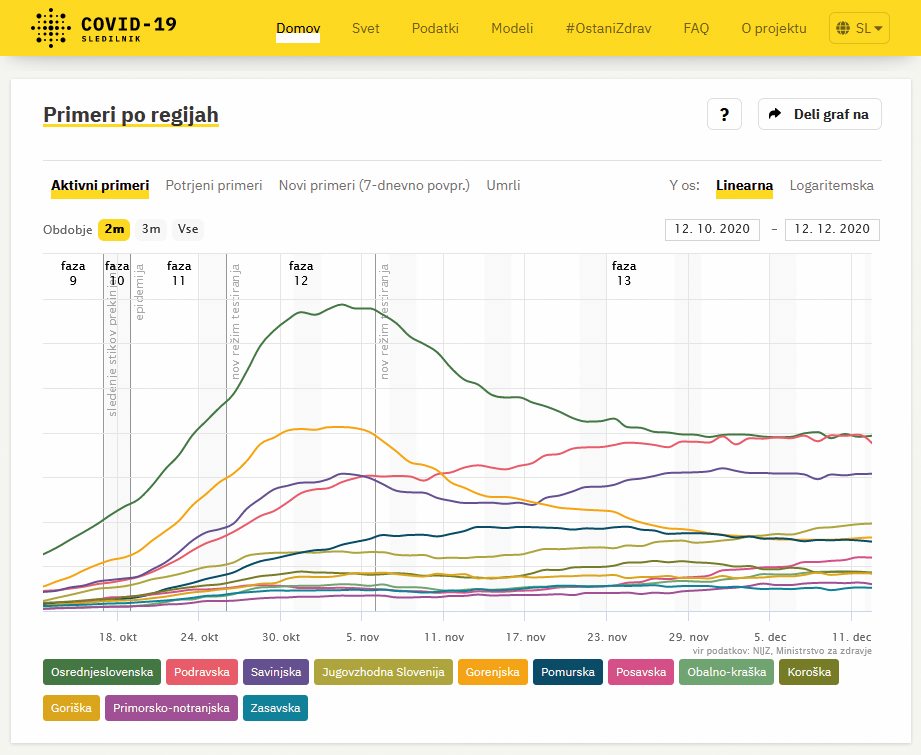
Ena izmed vizualizacij v Sledilniku.
Iz nosu do Sledilnika
Srce Sledilnika so podatki o testiranjih, stanju v bolnišnicah in umrlih. Vsak zabeleženi test se je, vsaj do prihoda hitrih antigenskih testov decembra, začel z nosno-žrelnim brisom. Te jemljejo na številnih lokacijah po Sloveniji, predvsem v bolnišnicah in zdravstvenih domovih. Režim testiranja se je sicer med epidemijo večkrat spremenil, a to ta hip ni pomembno. Ti brisi potem potujejo do Inštituta za mikrobiologijo in imunologijo (IMI), Nacionalnega laboratorija za zdravje, okolje in hrano (NLZOH) z izpostavami v Mariboru, Kopru, Novem mestu, Kranju in Murski Soboti, Klinike Golnik ali bolnišnic v Celju, Novi Gorici in Slovenj Gradcu, kjer izvajajo teste PCR (verižna reakcija s polimerazo). Od tam pa potem podatki romajo na najrazličnejše naslove in po nekaj ovinkih z več strani tudi do ekipe Sledilnika.
Podatki do Sledilnika ne pridejo v lično urejeni elektronski obliki, po možnosti iz enega vira. Nasprotno, ekipa zbira in kombinira podatke iz obilice uradnih poročil in virov, kot je na spletnem predavanju v okviru Spletnih uric Maribor pojasnila Maja Založnik. Večina jih je sicer že v obliki Excelovih preglednic, kar je bolje od slik v nizki ločljivosti, nad katerimi bi bilo treba delati OCR – tudi tako je bilo na samem začetku. Manjka pa Excelovim datotekam redundanca oziroma kontrola polja.
Sledilnik je dokazal, da je dandanes tehnologija na voljo vsakomur. Orodja, ki jih uporablja, so odprtokodna. Infrastruktura, na kateri teče, je na voljo skoraj zastonj. Strežnik na Hetznerju stane pet evrov na mesec, še toliko info@sledilnik.org na GSuitu.
Podatki začno pritekati že zjutraj. IMI je do 3. decembra pripravljal poročilo (»LAB«) o testih in pozitivnih primerih, ki je bilo prva informacija in jo je Sledilnik lahko že zjutraj objavil na Twitterju. Ko so v petek, 4. 12. 2020, objavili, da podatkov nimajo, je to v javnosti sprožilo različne špekulacije, a kriva je bila sprememba podatkovnega toka. Poročilo »LAB« zdaj pripravlja Nijz, a je nekoliko drugačno in ne vsebuje več razreza po testih glede na laboratorij. In tako je ta podatek po 3. decembru izginil s Sledilnika. Podobnih primerov je še več, ker so se med epidemijo pač spreminjali režimi in delovni tokovi, poročila so dobivala drugačno obliko in naslovnike itd.
Drugo pomembno poročilo (»HOS«) o stanju v bolnišnicah pripravi ministrstvo za zdravje. Za 13 bolnišnic, dve negovalni bolnišnici in pet psihiatričnih, ki imajo oddelke za covid, obstaja skupna aplikacija, kamor se vnaša stanje na oddelkih za covid. Te podatke potem na ministrstvu zberejo v skupno poročilo, ki vsebuje informacijo o številu bolnikov, odpuščenih in umrlih. Števila sprejetih v poročilu ni, se pa seveda v Sledilniku izračuna, a se s tem izgubi ena možnost redundance za navzkrižno preverjanje. Aplikacija je primarno namenjena informacijam o številu prostih mest v bolnišnicah na ravni države, dobrodošel stranski učinek pa je pregled nad pretokom bolnikov. V poročilu je tudi podatek o številu bolnikov na intenzivni terapiji, a le kumulativa.
To pa ni velik problem, ker je ta rešen drugače. V prvem valu, ko je bilo intenzivnih enot le pet (Ljubljana, Maribor, Celje, Novo mesto in Golnik), so se ti podatki zbirali v tabeli v Wordu, kar je počel dr. Matjaž Jereb, vodja oddelka za intenzivno terapijo na kliniki za infekcijske bolezni in vročinska stanja v ljubljanskem UKC. V drugem valu je takih intenzivnih oddelkov 13, zato je kar Sledilnik poskrbel za lažjo obravnavo podatkov. V pripravljeno Excelovo datoteko (»ICU«) oddelki intenzivne terapije sami vnašajo podatke o številu intubiranih bolnikov na respiratorju (invazivna ventilacija), o sprejetih, odpuščenih in umrlih ter jo posredujejo neposredno Sledilniku. Tabela ima kontrolna polja, zato je kakovost podatkov na visoki ravni.
Podatkovna odličnost je termin, ki ga člani Sledilnika večkrat radi poudarijo kot eno glavnih vodil. Pri prejemanju podatkov iz najrazličnejših virov, kjer so nekateri tudi v zaostanku, se neizogibno pojavljajo tudi odstopanja. Teh je zdaj manj in jih večinoma polovijo s kontrolnimi polji, a posodabljanje za nazaj, ko se pojavijo nove informacije (npr. o umrlih v domovih za starejše občane), ni nič neobičajnega niti spornega.
Druge vsebine Sledilnika
Poleg osnovne spletne avtorji Sledilnika objavljajo informativne vsebine na Mediumu (medium.com/sledilnik), kjer najdemo različne sestavke s poglobljeno interpretacijo podatkov. Tam razložijo, zakaj je epidemija dolge tedne vztrajala na platoju, za katerega se je izkazalo, da je kombinacija pojemajoče in rastoče faze epidemije v različnih regijah; kdo hodi na obiske; kako in zakaj nastanejo valovi epidemije in podobno. Na Mediumu objavljajo tudi odgovore na novinarska vprašanja, preverjene informacije o virusu itd.
Kogar zanimajo surovi podatki, jih bo našel na Githubu (github.com/sledilnik). Poleg podatkov v obliki CSV so tam še orodja za njihovo obdelavo. Z API-strežnika (github.com/sledilnik/data-api) jih lahko dobimo tudi avtomatizirano v strojem prijazni obliki.
Ekipa je postavila tudi stran Covid-SPARK (covid-spark.info), ki ni namenjena sledenju okužbam, temveč obveščanju stikov okuženih. Medtem ko aplikacija #ostanizdrav, ki jo je pripravila država, omogoča anonimno sledenje stikov in obveščanje, je SPARK namenjen neanonimnemu obveščanju kontaktov, s katerimi smo bili v stiku, prek SMS, ki so tehnologija, do katere ima dostop praktično vsak (v nasprotju z aplikacijo).
Četrto poročilo podaja število umrlih. Del te informacije je pripotoval že iz bolnišnic, drugi del pa predstavljajo smrti v domovih za starejše občane (DSO). Te podatke v poročilo (»EPIDSO«) zbere Nijz in ga posreduje vladi, Sledilnik pa ga ne dobi. Ta informacija se kasneje znajde na vladnih straneh, a najhitrejši kanal je Twitter. Sledilnik dobesedno prepiše te podatke z vladnega računa na Twitterju. Dan se počasi prevesi v popoldne, Sledilnik pa posodobi grafe in podatke na strani.
Popoldne, okrog 14. ali 15. ure, dobi Sledilnik še veliko epidemiološko poročilo Nijz (»EPI«), ki sicer nastane že v dopoldanskih urah in je do oktobra tudi prihajalo med 10. in 11. uro, potem pa se je zaradi preobremenjenosti epidemiološke službe poročanje zamaknilo. V tem poročilu so podatki o vseh opravljenih (pozitivnih) testih ter demografski podatki (spol, starost, občine). Nijzu namreč poročajo tudi vse zdravstvene ustanove in vsi DSO. Enkrat tedensko poročilo vključuje tudi podatke o viru okužb, uvoženih primerih in okužbah med zdravstvenimi delavci. Tudi tu se lahko podatki spremenijo za nazaj, ko se informacije izboljšajo ali postanejo znane.
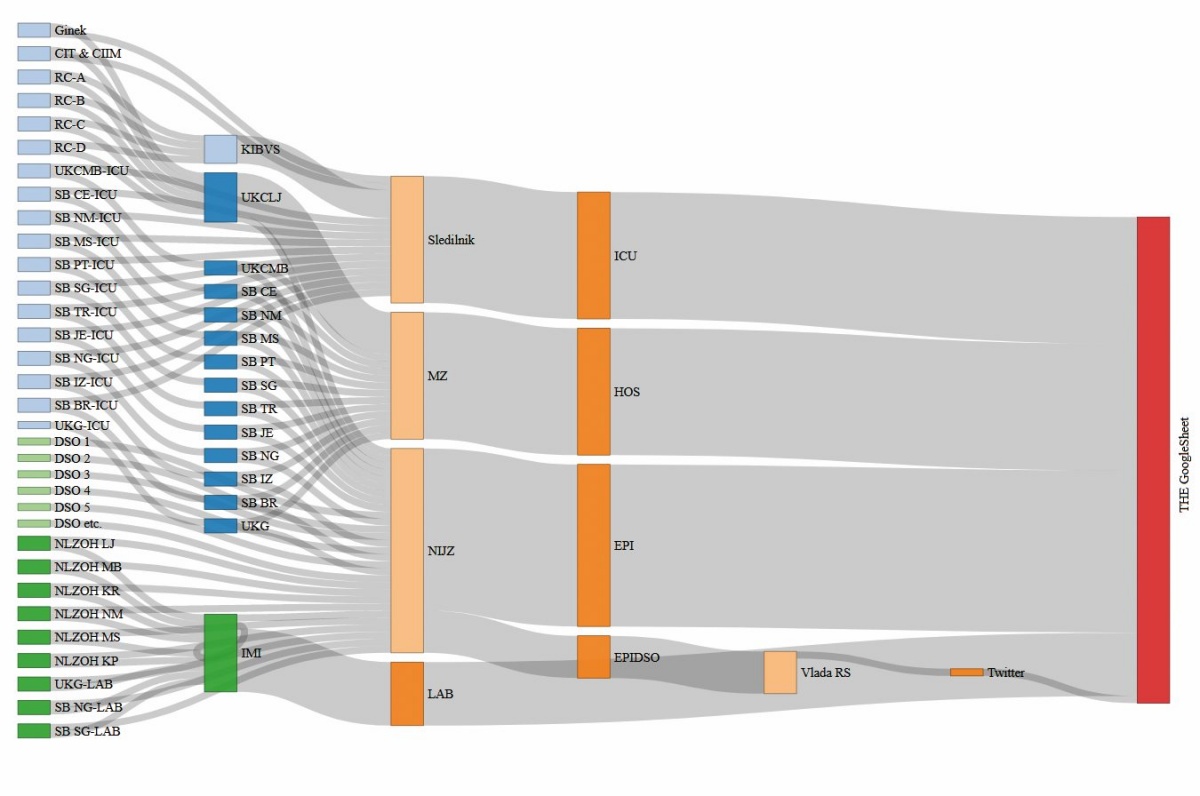
Poenostavljena shema pretoka informacij, ki se zbirajo v Sledilniku. Slika: Maja Založnik, Sledilnik (majazaloznik.github.io/sledilnik-data_pipelines/)
V Sledilniku
Pri taki množici poročil, ki po obširnosti segajo od kratkega čivka na Twitterju (izvleček poročila »EPIDSO«) do obsežnega epidemiološkega poročila (»EPI«) s šestimi velikimi tabelami, se seveda pojavijo odstopanja in neujemanja. Poročila so tudi precej različna po obliki.
Ni namreč vsak podatek v računalniku že računalniku prijazna oblika. Nekatera poročila so v obliki besedil v elektronski pošti, druga so Wordovi dokumenti, tretja Excelove datoteke in še kaj. Najbolj avtomatizirana je komunikacija z aplikacijo #ostranizdrav, kjer s strežnika na ministrstvu za javno upravo (MJU) podatki tečejo samodejno.
Za nekatera poročila so člani Sledilnika napisali skripte, ki avtomatizirajo njihovo branje in ureditev podatkov, za druge pa tega (še) niso storili. Razloga sta dva, oba sta povezana. Prvič, pisanje skriptov traja, zato se je opravila smiselno lotiti zgolj, če ga bo mogoče uporabiti večkrat. In drugič, poročila se spreminjajo in nekatera tudi izginejo.
Do konca oktobra so, na primer, zdravstveni domovi z vstopnih točkah za covid 19 poročali o obravnavanih primerih, zdaj teh podatkov ni več, ker se poročilo ne pripravlja več. V drugih primerih podatki obstajajo, a niso uporabni za predstavitev. Ministrstvo za izobraževanje, znanost in šport ima API, od koder je mogoče pridobiti informacijo o okužbah v šolah, a ker je podatek kumulativen, ne pa razvrščen po posameznih šolah, o čemer te sicer poročajo ministrstvu, Sledilnik tega podatka (še) ni uporabil. Za poročila, ki jih ne obdelujejo s skripti, in podatke iz drugih virov pa ostaja preverjena metoda ročnega vnašanja. Na začetku delovanja niso bili redki niti skeni, ki jih je bilo treba optično prebrati (OCR). Ročnega dela torej ni malo.
Toda tako kot so nekatera poročila izginila, so se pojavila nova. V prihodnosti Sledilnik načrtuje uporabo podatkov Nacionalnega inštituta za biologijo, ki meri prisotnost virusa v odpadnih vodah. To je podatek o obremenjenosti področja z obolelimi, ki ima še krajši odzivni čas od testov ali hospitalizacij. Prav tako se pripravlja vključitev modelnih napovedi članov ekipe Sledilnik v spletni prikaz. Po uspešnem pilotnem preizkusu se pripravlja redni monitoring na sedmih velikih čistilnih napravah, kjer bo Sledilnik sodeloval pri validaciji, vizualizaciji in integraciji podatkov z modeli.
Poročilo, ki ga na svoji spletni strani javno objavi Nijz (www.nijz.si/sl/dnevno-spremljanje-okuzb-s-sars-cov-2-covid-19).
Za Sledilnikom
Projektu se vidi, da je nastal ljubiteljsko in da nihče ni pričakoval, da bo tako dolgo v uporabi ali da se bo razrasel do takšnih razsežnosti. Spočetka so vsi menili, da bo slej ko prej takšen portal postavila ali prevzela uradna institucija. A ga ni, zato so podatki shranjeni v nepričakovani obliki.
Citat: Do 11. decembra je Sledilnik vse podatke zbiral v ogromni preglednici Google Sheet, po 12. decembru se podatki zbirajo v drugi obliki, ker so razvijalci trčili ob omejitve Googlove preglednice.
Do 11. decembra je Sledilnik vse podatke zbiral v ogromni preglednici Google Sheet (tinyurl.com/sledilnik-gdocs), ki ima dobrih 40 zavihkov, na posameznih pa prek 100 stolpcev in več sto vrstic ter prek 1.000 komentarjev. Približno polovica polj se izračunava iz drugih polj, v ostala se podatki vpisujejo. Takšen način ni optimalen, a za zdaj deluje. Podatki se izvažajo tudi v več datotek CSV, ki jih lahko snamemo s strani Sledilnika ali pa do njih dostopamo prek REST API. Vsi podatki Sledilnika so prosto dostopni in vsakomur na vpogled, prav tako so na njihovem Githubu na voljo orodja za obdelavo (github.com/sledilnik/data/).
Po 12. decembru se podatki zbirajo v drugi obliki, ker so trčili ob omejitve Google Sheeta. Kot je razložil Luka Renko, ena velika preglednica z ogromno različicami, komentarji in formulami, ki jo ureja deset članov ožje ekipe in si jo ogleduje še do sto uporabnikov, ni več obvladljiva. Po posameznem vnosu se tudi za minuto ali dlje zablokira, kot da bi potekala sinhronizacija na Googlovih strežnikih, zato so morali zbiranje razbiti v več manjših preglednic, kjer ima pravice za urejanje manj ljudi, javnosti pa še niso odprte.
Prednik Sledilnika je nastal, ko je Luka Renko marca 2020 začel zbirati podatek o epidemiji v omenjeni Googlovi preglednici. Andraž Vrhovec je 12. marca dodal skript za samodejni izvoz v CSV, ki se objavlja na Githubu. Pet dni pozneje so si postavili Slack za organizacijo dela, ki ga še vedno uporabljajo (in to brezplačno različico, kar prinaša določene omejitve, a za zdaj zadostuje). Slack je namreč ob izbruhu epidemije skupnostim, ki so se ukvarjale z epidemijo, omogočil večkrat podaljšano uporabo brezplačne različice, ki pa se počasi izteka. Ali bodo še naprej uporabljali Slack ali pa bodo prešli na kaj odprtokodnega, se še niso odločili. Prva izvedenka spletne strani je bila napisana 18. marca, od 25. marca pa domuje na domeni sledilnik.org. Mesec dni pozneje je dobila svoj strežnik, 2. maja pa še strežnik API, ki podatke servira v obliki JSON.
Tok podatkov za spletno stran je trenutno takle: Google Sheet -> datoteke CSV na GitHubu -> API-strežnik -> predstavitev na spletni strani v obliki grafov in kartic.
Sledilnikova spletna stran je statična, kar je z vidika varnosti koristno. Obiskovalci na stran ne morejo dodajati ničesar, temveč si lahko le ogleduje vizualizirane podatke. Kot že omenjeno, sta vir podatkov API-strežnik in dokument na Google Sheet. Tok podatkov za spletno stran je trenutno takle: Google Sheet -> datoteke CSV na GitHubu -> API-strežnik -> predstavitev na spletni strani v obliki grafov in kartic. Najmanj avtomatiziran je postopek polnjenja Google Sheeta, kaj podatki prihajajo iz najrazličnejših virov (glej zgoraj), medtem ko gre od tam dalje po bolj ustaljenih in avtomatiziranih poteh.
Seveda pa se stran sproti razvija: dodajajo nove vizualizacije, nove izračune, nove vrste podatkov itd. V prvih 280 dneh obratovanja, ki poteka po principu continuous delivery pipeline, so imeli 739 dopolnitev (pull request).
O obsegu projekta priča dejstvo, da pri njem sodeluje dobrih 250 članov (kakšnih 60 je aktivnih vsak dan), ki na Slacku komunicirajo prek 51 kanalov. Ko nekdo predlaga spremembo, odkrije napako ali ima kakšen drug predlog, se v niti pod sporočilom začne pogovor, kaj je mogoče narediti. Tehnični del strani ureja približno 25 ljudi. Ti imajo dostop do 17 repozitorijev na Githubu. Ko se konča pull request, sprememba pa sprogramirana, se samodejno pretoči v glavno vejo in postavitev kode v testno različico spletne strani. Po odobritvi dobi spremembo tudi glavna veja.
O obsegu projekta priča dejstvo, da pri njem sodeluje dobrih 250 članov (kakšnih 60 je aktivnih vsak dan), ki na Slacku komunicirajo prek 51 kanalov.
Medtem ko so imeli spomladi občasno težave z nedosegljivostjo GitHub Pages, je strežnik API to rešil. Danes Sledilnik domuje v oblaku (Hetzner Cloud), kjer lahko statična stran gostuje že za pet evrov na mesec, ki jih pokrije fizična oseba (do zdaj Luka). Da ob velikem obisku stran še vedno ostaja dosegljiva, skrbi Cloudflare v brezplačni različici. Danes Sledilnik poganja infrastruktura Kubernetes, Ansible, Helm in GitHub Actions. Spletna stran je narejena v Vue.js (framework za JavaScript), grafi so izrisani v knjižnici Highcharts, koda pa v programskem jeziku Fsharp.
Sledilnik sledi okužbam s koronavirusom, ne pa svojim obiskovalcem, zato obsežne statistike o prometu nimajo, lahko pa iz podatkov Cloudflara sklepajo, koliko obiskovalcev imajo: okrog 80–100 tisoč unikatnih obiskovalcev dnevno, na mesec pa 800–900 tisoč.
Citat: Danes Sledilnik poganja infrastruktura Kubernetes, Ansible, Helm in GitHub Actions. Spletna stran je narejena v Vue.js (framework za JavaScript), grafi so izrisani v knjižnici Highcharts, koda pa v programskem jeziku Fsharp.
Pomemben del Sledilnika je tudi modeliranje. V skupnosti sodeluje več skupin, ki se ukvarjajo z različnimi vrstami modeliranja. Model SEIR (susceptible, exposed, infected, recovered) pripravlja dr. Janez Žibert z ljubljanske zdravstvene fakultete. Inštitut za biostatistiko in medicinsko informatiko ljubljanske medicinske fakultete pod vodstvom dr. Maje Pohar Perme ocenjuje stopnjo reprodukcije virusa, dr. Žiga Zaplotnik z ljubljanske FMF pa modelira širjenje virusa po družabnem omrežju prebivalcev Slovenije.
Modelov je seveda še bistveno več, Sledilnik pa ima objavljene povezave na številne izmed njih ter tudi izide napovedi. Vsi modeli imajo svoje omejitve in tega se moramo zavedati. Niso kristalna krogla, ki bi napovedala prihodnost, temveč orodja za napoved, kaj lahko prinesejo posamezna ravnanja in ukrepi v prihodnosti, ter analizo, zakaj smo, kjer smo.
Sledilnik ima tudi močno razvojno komponento, saj se stran ves čas posodablja. Ne gre le za tehnične nadgradnje, temveč aktivno dodajajo nove funkcionalnosti in podatke, če jih le lahko pridobijo. Poleg že omenjenega vzorčenja odpadnih voda za hitrejšo informacijo o razširjenosti virusa imajo zanimive podatke tudi mobilni operaterji. Ti zelo dobro vidijo, kod in kdaj se ljudje gibljejo. Agregirani in anonimizirani podatki o gibanju prebivalstva že obstajajo, nekateri operaterji jih že tržijo (Digitalne drobtinice, Monitor 06/19), zato se Sledilnik z enim večjih operaterjev pri nas dogovarja za dostop tudi do teh podatkov in njihovo uporabo. Zamisel je, da bi najprej na starih podatkih (iz septembra) pilotno pokazali, kako jih je mogoče uporabiti pri obvladovanju epidemije.
Po Sledilniku
Epidemije bo nekoč konec in tedaj bo ugasnil tudi COVID-19 Sledilnik. Skupina je nastala iz ljudi, ki se pred tem niso poznali, in je organsko rasla, nato pa šele decembra začela postopke za registracijo kot znanstveno društvo in imela ustanovni zbor članov. Ves ta čas je Sledilnik deloval kot neformalno, nestrukturirano združenje posameznikov, ki zbirajo, obdelujejo, predstavljajo in modelirajo podatke o najhujši epidemiji v zadnjih sto letih. Kot znanstveno društvo želi Sledilnik obstati tudi po epidemiji.
Sledilnik je dokazal, da je dandanes tehnologija na voljo vsakomur. Orodja, ki jih uporablja, so odprtokodna. Infrastruktura, na kateri teče, je na voljo skoraj zastonj. Strežnik na Hetznerju stane pet evrov na mesec, še toliko info@sledilnik.org na GSuitu. Hkrati pa so avtorji Sledilnika pokazali, da timski duh lahko doseže veliko. Ker je covid 19 prva globalna pandemija, ki poteka v informacijski dobi, bodo zbrani podatki, izkušnje in orodja neprecenljivi tako v kateri od prihodnjih pandemij kot tudi pri drugih izzivih modernega časa, denimo podnebnih spremembah.
Pri vseh teh velikih izzivih namreč potrebujemo troje: čim več kakovostnih podatkov, ljudi, ki znajo te podatke obdelati in iz njih razbrati pomembno, ter prebivalstvo, ki bo ponotranjilo sporočilo. Sledilnik in podobni projekti opravljajo vse tri naloge.
Makedonski sledilnik
Iz slovenskega Sledilnika je nastal tudi makedonski klon, ki sta ga zagnala Luka Renko in Vladimir Nešković, sicer gonilna sila slovenskega projekta, zdaj pa se vzpostavlja še lokalna makedonska ekipa. Makedonski sledilnik (covid-19.treker.mk) ima enako vizualizacijo podatkov in podoben tok, prilagojen makedonskim virom.
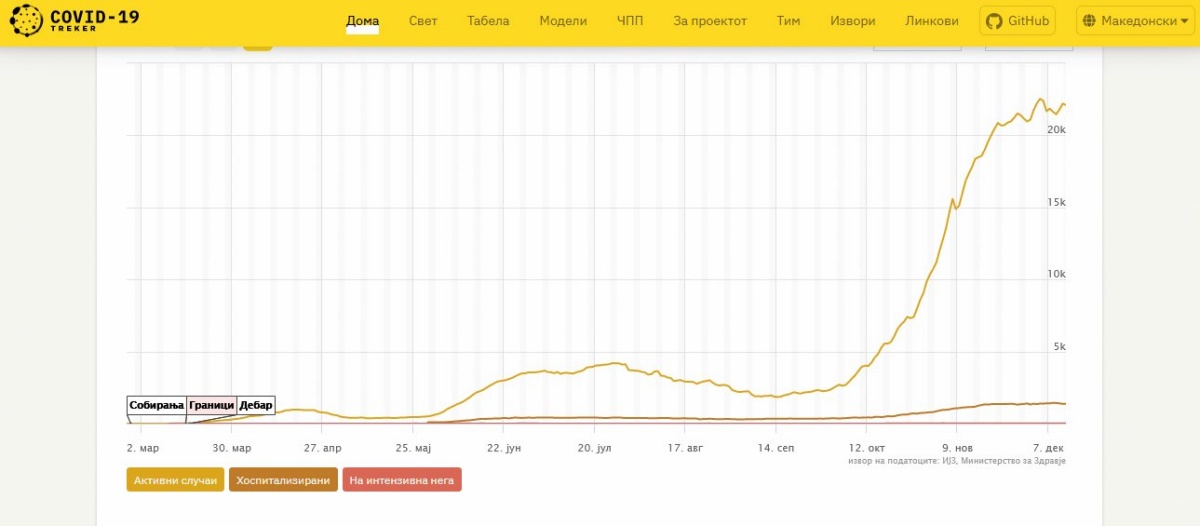
Makedonski Treker je klon slovenskega Sledilnika.