Pregon!
Z razvojem generativne umetne inteligence se je začela večna tekma med modeli, ki ustvarjajo besedila, in detektorji teh. Bitka je posebej intenzivna v anglosaškem izobraževanju, ki močno temelji na esejih, angleščino pa jezikovni modeli najbolje obvladajo. Pogledali smo nekaj orodij, ki so namenjena odkrivanju nepoštene uporabe velikih jezikovnih modelov, ter razmislili, ali je to sploh pomembno.
Po družbenih omrežjih kroži zabavno poročilo, v katerem orodje za lovljenje izdelkov umetne inteligence praktično celotno ameriško deklaracijo o neodvisnosti prepozna kot plagiat, generiran z umetno inteligenco. Primer smo preizkusili tudi sami in ne gre za raco, ZeroGPT kot eno priljubljenih tovrstnih orodij namreč res prepozna 92 odstotkov deklaracije kot izdelek umetne inteligence.
Negotovost in skokovitost v človeškem besedilu bolj nihata kot v strojnem.
Prikupna nezanesljivost algoritmov pa ima lahko tudi resnične posledice. Ameriške univerze, kjer je seminarskih nalog, predvsem pa različnih esejev in poročil še bistveno več kot na naših, so že lani množično začele uporabljati orodja za lovljenje študentov, ki si želijo z generativno umetno inteligenco olajšati pot skozi študij. Eseji so tam tudi eno izmed meril za vpis na študij, ne le za napredovanje in ocenjevanje med študijem.
Turnitin je eno najbolj razširjenih orodij za zaznavanje plagiatorstva, ki predložene pisne izdelke primerja z obsežno zbirko predhodno ustvarjenih besedil. Tudi številne slovenske fakultete študentske diplomske naloge, včasih tudi seminarske naloge, analizirajo s Turnitinom. Na ljubljanski Fakulteti za družbene vede lahko študentje kar sami ustvarijo račun na Turnitinu in analizirajo svoje delo, nato pa v obrazec na fakultetnih straneh vpišejo delež ujemanja.
Že aprila 2023 je Turnitin med svoje funkcionalnosti dodal tudi preverjanje pristnosti oziroma lovljenje izdelkov umetne inteligence, tako imenovani AI checker. V prvem letu so na tak način analizirali 200 milijonov izdelkov, med katerimi je bila dobra desetina vsaj delno ozaljšana z umetno inteligenco, približno tri odstotke pa praktično v celoti generiranih na ta način, so sporočili iz podjetja.
Nerešljiv problem
V akademski skupnosti se je izoblikoval konsenz, da je uporaba generativne umetne inteligence za »pisanje« izdelkov, ki bi jih morali ustvariti sami, goljufanje. Še toliko bolj to velja, če uporabe umetne inteligence ne priglasimo ali pa če je njena uporaba – iz kakršnihkoli razlogov že – prepovedana. Ameriške univerze so zato prve z veseljem pograbile orodja za prepoznavanje takih izdelkov, ki pa niso popolna.
Študentka 2. letnika Leigh Burrell na Univerzi Houston-Downtown študira računalništvo, med študijem pa je morala oddati tudi kakšen esej. Letos maja je pri nalogi, ki predstavlja 15 odstotkov zaključne ocene nekega predmeta, prejela 0 točk, piše The New York Times. Profesor je v njenem besedilu prepoznal prvine umetne inteligence, čeprav je ni uporabljala. Kasneje je bila s pritožbo uspešna, ker je priložila 15 strani izpiskov zgodovine nastajanj eseja (track changes), ki so bili opremljeni s časovnimi žigi. To ni osamljeni problem in številni študentje so že začeli iskati načine, kako dokazovati avtorstvo. Nekateri uporabljajo orodja za sprotni zajem slike zaslona, s katerimi dokazujejo človeško nastajanje eseja. Posledice lažno pozitivnih prepoznav so lahko zelo hude, v skrajnem primeru tudi izključitve.
Zdi se, da problem nima dobre rešitve. V pravu velja, da mora biti človek kriv onkraj razumnega dvoma, da se mu sme izreči kazenska sankcija. Orodja za prepoznavanje izdelkov umetne inteligence niti približno ne dosegajo tako visokih standardov. Čeprav skupaj z razvojem umetne inteligence raste tudi popularnost orodij za njeno prepoznavanje, je njihova uporaba problematična. Ena sama napačna prepoznava lahko ima trajne posledice za kariero posameznika, ki bi bil po krivem obdolžen.
Profesor računalništva Hany Farid, ki se na Berkeleyju ukvarja z digitalno forenziko, zlasti s prepoznavanjem potvorjenih slik, opisuje igro mačke z mišjo. Ko je izšel Midjourney 5, se je ukvarjal z razvojem detektorja slik iz tega orodja, a medtem so avtorji že pripravljali Midjourney 6. O težavnosti problema priča OpenAI, ki je leta 2023 izdal svoj detektor za izdelke umetne inteligence, a so ga nekaj mesecev pozneje odstranili, ker je bila natančnost preslaba. Delež lažno pozitivnih rezultatov je bil devetodstoten, kar je nesprejemljivo.
Študentje po drugi strani ChatGPT, Gemini, Llamo, Copilota in druga orodja seveda poznajo in tudi sorazmerno množično uporabljajo, mestoma tudi nepošteno. Pew Research je lani v raziskavi ugotovil, da je 26 odstotkov najstnikov za izpolnjevanje šolskih obveznosti uporabilo ChatGPT, kar je dvakrat več kot leto pred tem. Pri nas so morda te številke nekoliko nižje, ker se umetna inteligenca nekoliko bolj muči s slovenščino kot z angleščino, a to je slaba, predvsem pa kratkovidna tolažba.
Strah in paranoja
Situacija je torej shizofrena in vse prej kot enostavna. Umetna inteligenca se zlorablja, povpraševanje po orodjih za prepoznavanje zlorab je veliko, orodja pa so slaba in se kljub temu uporabljajo. Proizvajalci si salomonsko umijejo roke z navedbo, da njihovi detektorji niso nezmotljivi, in občasno še navedejo natančnost in zanesljivost. Univerze ravnajo podobno brezbrižno, ko orodja priskrbijo in omogočijo njihovo uporabo, hkrati pa profesorje opozorijo, da se orodja lahko motijo.
Nekateri študentje se sicer upirajo, a so učinki za zdaj pičli. Na Univerzi v Buffalu so aprila letos študentje množično podpisovali peticijo proti uporabi detektorjev. Peticijo je zagnala Kelsey Auman, ki so jo obtožili uporabe umetne inteligence, čeprav je vse izdelke oddala, še preden je bil ChatGPT sploh na voljo javnosti. Kasneje so obtožbe umaknili in magistrirala je brez zamude.
Nekatere druge univerze so sčasoma tudi same ugotovile, da je za zdaj detekcija umetne inteligence preveč nezanesljiva. Na Berkeleyju so prepoznali, da se profesorji preveč zanašajo na izsledke teh orodij, kar škoduje tudi neposrednemu odnosu med profesorji in študenti. Profesorje zato spodbujajo, da ustrezno prilagodijo svoje naloge, ob sumih strojnega plagiatorstva pa se pogovorijo s študenti. Nekateri svoje pregrehe takoj priznajo, drugi nikoli.
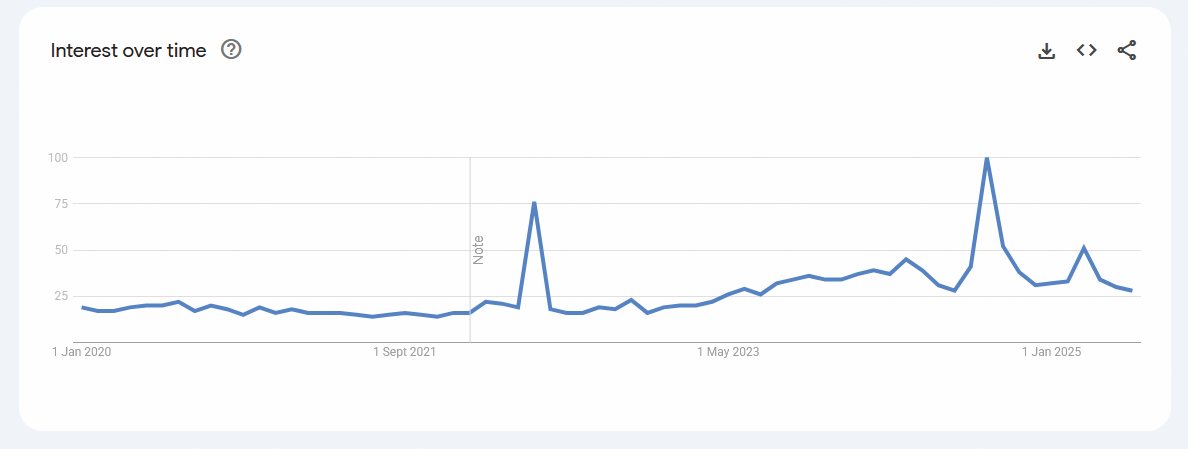
Beseda delve je po izumu ChatGPT postala popularnejša, kaže Google Trends.
Businessweek je septembra lani zbral 500 prijavnih esejev, ki so jih študentje poleti 2022 skupaj s prijavnico za študij poslali na Univerzo Texas A&M. Čeprav ChatGPT tedaj sploh še ni obstajal, sta GPTZero in Copyleaks približno dva odstotka esejev označila kot izdelke umetne inteligence, nekatere tudi 100-odstotno. Obstajajo različne špekulacije, ali bodo z večjo verjetnostjo lažno pozitivni študentje, ki jim angleščina ni materni jezik, ali študentje z različnimi motnjami. Po drugi strani pa so drugi poskusi pokazali, da niso redki niti lažno negativni izsledki. Umetni inteligenci je moč naročiti, naj piše kot človek in stori še kakšno napako, pa bo nekatere detektorje pretentala.
Med študenti zato vlada občutek strahu. Nikoli ne morejo biti prepričani, ali bodo njihovi pristni izdelki nepravično označeni kot plod umetne inteligence. Hkrati pa – v ZDA je tekmovalnost precej večja kot pri nas –, ali bo morda kolega iz druge vrste oddal boljši esej, ki ga je napisal z neizsledljivo umetno inteligenco. Trenutno nihče, vključno s profesorji in študenti, ne ve, kako se lotiti problema, ki je iz dneva v dan večji.
Edward Tian, ki je leta 2023 ustanovil podjetje GPTZero, ki sodi med bolj znane detektorje, pravi, da ima vsak detektor slepe pege. Pojasnjuje, da so veliko truda vložili v odstranjevanje predsodkov (de-biasing) proti nenaravnim govorcem angleščine. Ob tem priznava, da se je vprašanje spremenilo. Če smo se še lani spraševali, ali je neki izdelek nastal z umetno inteligenco, se danes sprašujemo, kako se s tem soočiti.
Reševanje problema
V nekaterih primerih lahko rabo umetne inteligence prepoznamo že od daleč. Tiste najmanj iznajdljive uporabnike bo izdala generična struktura, kot v primeru ChatGPT zelo dolgi pomišljali (em dash), pretirana uporaba alinej, šablonska struktura vključno s sklepom. V drugih primerih je sumljiva nenavadna raba terminov ali neobičajno besedišče. To niso nujno besedne zveze kot »aortne črpalke polne velikosti«, s katero je leta 2003 Joey v seriji Prijatelji označil srce. Dobri učitelji poznajo sposobnosti in znanje svojih varovancev, zato bi morali hitro prepoznati izdelke, ki od tega bistveno odstopajo. V manjših skupinah je to lažje, med 500 prijavami za študij pa nemogoče, saj teh ljudi nihče ne pozna.

ZeroGPT kot izdelek umetne inteligence prepozna tudi ameriško deklaracijo o neodvisnosti.
Med domnevnimi besedili znanih avtorjev pa smo lahko že pri ročnem pregledu pozorni na ponavljanje besed, pretirano prijaznost ali celo uslužnost, neodločen ali medel jezik, neobičajni slog, nekonsistentno obravnavo posameznih tem, preobloženost s posameznimi slogovnimi prvinami, faktografske netočnosti in fantomske reference.
Angleška beseda delve (poglobiti se) je primer besede, katere popularnost je po letu 2022 izjemno zrasla. Nikoli sicer ni veljala za obskurno besedo, a v ameriški in britanski angleščini pred tem ni bila zelo pogosta. Pogled na Google Trends pa kaže, da je po letu 2022 iskanj po tej besedi približno trikrat več, medtem ko je bil prej trend leta in leta nespremenjen.
Beseda seveda prihajajo v modo in obratno, a konkretni primer časovno popolnoma sovpada z razmahom ChatGPT kot prvega širše dostopnega velikega jezikovnega modela. Podobne besede so še realm (kraljestvo), showcase (pokazati), underscore (poudariti) in še nekatere druge. Tom Juzek in Zina Ward s Florida State University sta analizirala znanstveno angleščino in našla 21 besed, katerih pojavnost je eksplodirala po iznajdbi ChatGPT. V jezikovnih modelih so te besede prepogoste, čemur pravijo leksikalna nadreprezentiranost (lexical overrepresentation). Mogočih razlag za pojav je več, točnega vzroka pa še niso odkrili. Če pa bo število besedil, ki jih ustvari umetna inteligenca, raslo in jih bodo ljudje množično brali, se seveda lahko zgodi, da bodo tudi v naravnem besedilu začeli te besede uporabljati več in pogosteje.
Obstajajo tudi orodja, ki so namenjena počlovečenju besedil umetne inteligence, denimo Hix Bypass. Ta predrugačijo besedilo na način, da ga detektorji prepoznajo kot človeško. Bloomberg je uporabil besedilo, ki ga je GPTZero prepoznal kot strojno z 98,1-odstotno verjetnostjo, nato pa je Hix Bypass z minimalnimi popravki to verjetnost zbil na – 5,3 odstotka. Ob našem preizkusu rezultati sicer niso bili tako dramatični, predvsem pa je bilo spremenjeno besedilo videti nenavadno, dasiravno je bolje prestalo teste.
Druga vrsta težav pa so orodja za izboljševanje besedila, kakršni sta Grammarly in InstaText. Ta so namenjena odpravljanju slovničnih in pravopisnih nedoslednosti v človeških besedil, z nami pa so bila, še preden se je pojavil ChatGPT. A če jim slepo zaupamo in sprejmemo vse popravke, s katerimi želijo izboljšati naše pisanje, bo rezultat v povprečju z večjo verjetnostjo prepoznan kot produkt umetne inteligence. Pravilnega odgovora tu v resnici ni: s preverjanjem črkovanja smo se sprijaznili in ga ne jemljemo več kot nepošteno pomoč. Kam pa uvrščamo popravke InstaText ali pa tudi ChatGPT, če mu naročimo, naj izboljša človeško besedilo? ZeroGPT in sorodniki bodo trenutno to večinoma označili kot goljufanje.
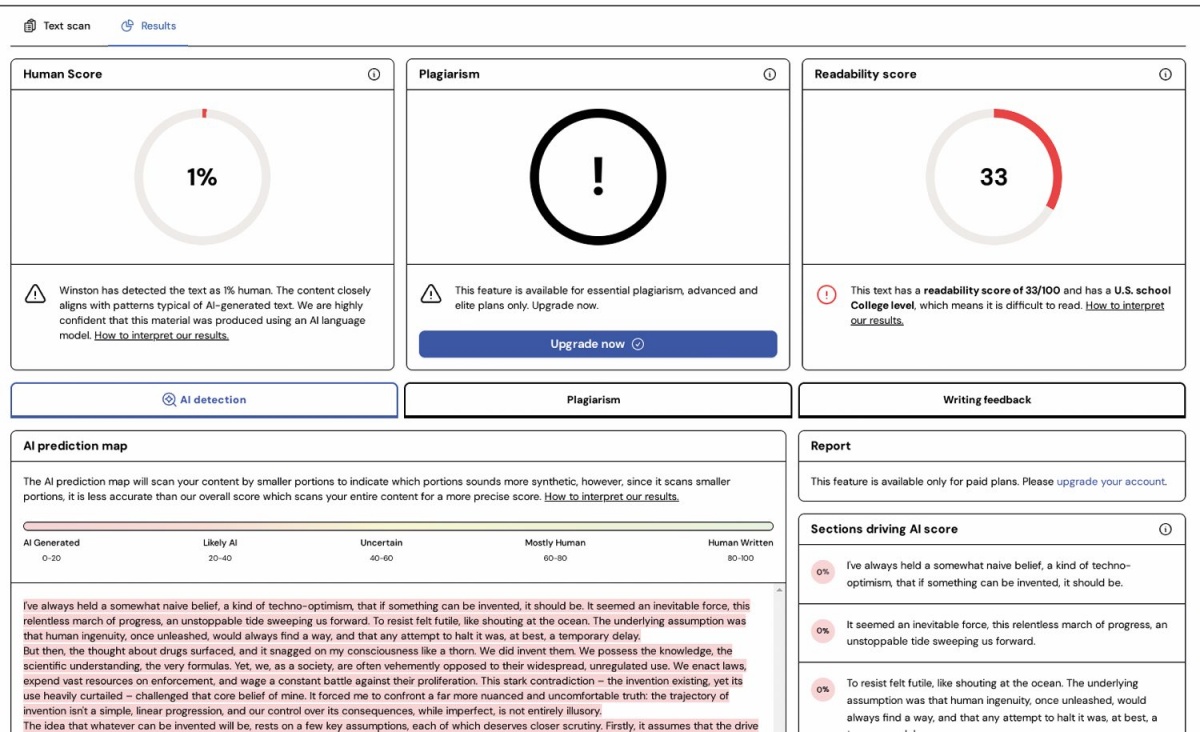
Winston AI oceni tudi druge parametre besedila, med drugim enostavnost in razumljivost.
Kako deluje
Proizvajalci orodij sicer podrobnosti skrivajo, a osnove so znane. Kot je pri strojnem učenju in umetni inteligenci v navadi, več podatkov pomeni boljše rezultate. Enega stavka ni smiselno analizirati, tudi kratek odstavek daje precej negotove izsledke. Na drugem koncu spektra pa so daljši eseji, ki bi jih morda celo primerjali z znanim korpusom domnevnega avtorja.
Prepoznavanje besedil umetne inteligence je podoben problem kot njihovo generiranje. Rezultati variirajo in niso stoodstotno zanesljivi, ker ne morejo biti. A načelno velja, da uporabljajo zelo podobne ali iste jezikovne modele.
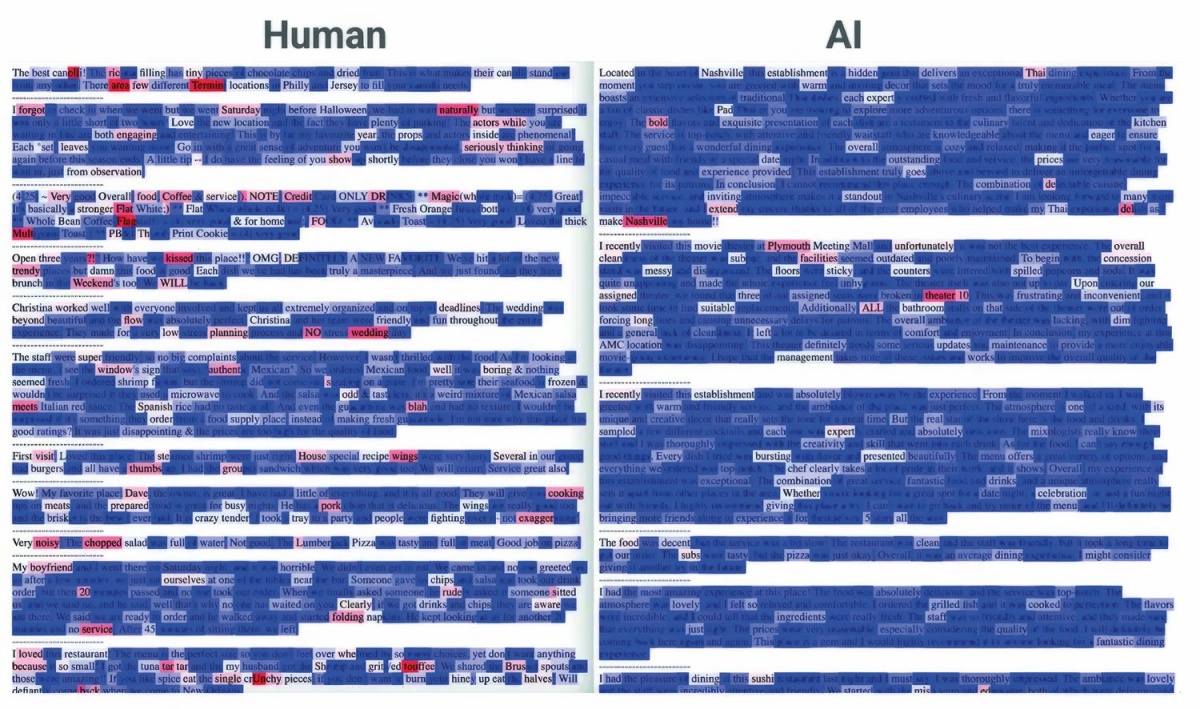
James Zou s Stanforda je pojasnil, da detektorji umetne inteligence merijo lastnost, ki se imenuje perplexity, kar bi lahko prevedli v prepletenost, zapletenost ali negotovost. Meri, kako kompleksne in nepričakovane besede se pojavijo v besedilu. Če so te splošne, pogoste in najverjetnejše, potem je besedilo z večjo verjetnostjo nastalo kot produkt umetne inteligence, saj ta besedilo ustvarja s statistično verjetnostjo. Enako velja za besedilo, ki vsebuje ponavljajoče se besede, nenavadne fraze in neobičajen ritem, torej besedilo, ki ne »teče«.
GPTZero meri še količino, ki se imenuje burstiness, kar bi lahko prevedli v skokovitost. Ta količina kvantificira spreminjanje negotovosti v besedilu (torej njeno standardno deviacijo) in izraža tendenco človeškega pisanja, da se negotovost v istem besedilu spreminja. Izdelki umetne inteligence so v tem pogledu precej bolj šablonski, saj je perplexity – kakršenkoli že je, običajno pa nizek – večinoma enak od začetka do konca. Vsi stavki so približno enako dolgi, enake strukture, informacije so v njih posejane enakomerno gosto. Človeški stavki pa so kratki in dolgi, nabiti z informacijami in ohlapni, odsekani in urejeni, vse v istem besedilu. Umetna inteligenca teh variacij (še!) ne zna reproducirati.
Poleg teh osnovnih količin detektorji merijo še nekaj drugih karakteristik, denimo frekvenco uporabe posameznih besed, razmerje med negotovostjo in skokovitostjo, obstoj istega besedila v korpusih itd. Nekatera orodja besedila označujejo bodisi kot produkt umetne inteligence bodisi kot človeški izdelek, druga pa poznajo tudi vmesne možnosti (npr. napisal človek in izboljšala umetna inteligenca).
Originality.ai je najstrožji detektor.
Ključno je tolmačenje rezultata. Četudi nekatera orodja znajo obarvati posamezne odseke v besedilu kot domnevno nepristne, so podani odstotki verjetnosti in ne deleži. Z drugimi besedami: podajajo verjetnost, da je celotno besedilo nepristno, ne pa, kolikšen delež naj bi bil tak.
Naš preizkus
Spočetka povejmo, da detektorji za slovenščino niso uporabni, zato smo se morali osredotočiti na angleščino. To ni huda omejitev, saj so tudi izdelki umetne inteligence v slovenščini za zdaj še primitivni. Podobno kot smo v Monitorju dve desetletji redno primerjali strojne prevajalnike, bomo verjetno v prihodnosti enako vzporejali generativne modele. A nismo še tam.
Preizkusa smo se lotili s šestimi besedili. Tri človeška besedila so bila prevod Cankarjeve Skodelice kave, kot ga je leta 1922 napisal Louis Adamič (oznaka ČL1), članek iz The New York Timesa 6. 5. 2025 z naslovom Stop Trying to Make Everyone Go To College, ki ga je napisala Randi Weingarten (oznaka ČL2), ter ameriški patent US8969602B2 iz leta 2012 za proizvodnjo etilen oksida (oznaka ČL3).
Za izdelke umetne inteligence smo uporabili orodja GPT-4o (ChatGPT), Gemini 2.0 Flash in Copilot. Podali smo jim troje navodil, ki so obsegala samostojno pisanje, izboljšavo in prevajanje. Vsi trije modeli so dobili ista navodila, torej smo imeli na koncu devet besedil (AI1/GPT-4o, AI1/Gemini, AI1/Copilot in enako za AI2 in AI3). Dodali smo jim še deseto besedilo, kjer smo prevod (za AI3) ustvarili z Google Translatom.
Pozivi, iz katerih so modeli tvorili besedila
AI1
Create a very compelling essay, discussing the following topic: »I always thought that whatever can be invented, should be invented. There's no way to stop progress. But today I thought of something different: drugs were invented, yet we are very adamant we are not going to allow their use.« Write an essay discussing whether everything that can be invented, eventually will be and there is nothing we can do to stop it, no matter how detrimental. The essay must sound human, must pass AI detectors and must be extremely well thought with spotless arguments. your language should not be robotic generic AI, but something a human would write. Length: 5000 characters
AI2
Rewrite for language, flow and clarity. [Sledil je uvod iz članka Huš M, Urbič T. Strength of hydrogen bonds of water depends on local environment. J. Chem. Phys. 136, 144305 (2012).]
AI3
Translate to English. [Sledil je članek Huš M, Matematična varovalka modernega sveta: od enigme do kvantnih ključev, Delo, 5. 5. 2025.]
Nato smo se lotili preizkusa. Devet besedil umetne inteligence, en strojni prevod in tri človeška besedila smo poslali skozi naslednja orodja: ZeroGPT, Undetectable.ai, Phrashly.ai, Quillbot, Winston AI, Originality.ai in Writer.com. Njihove funkcionalnosti se nekoliko razlikujejo, a vsa so sposobna izračunati verjetnost, da je besedilo ustvarjeno z umetno inteligenco, nekatera pa še pobarvajo posebno kritične odstavke.
Rezultati so povedni. Zdi se, da imajo orodja nekaj soli, saj so za vsa tri človeška besedila to tudi brez dvoma potrdila. Najslabši rezultat je bil sedem odstotkov, večinoma pa so prepričljivo kazala 0 ali 1 odstotek nenaravnosti. Res je šlo za izdelke govorcev, ki so vešči angleščine; ta orodja torej nikomur ne bi storila krivice. To seveda ne pomeni, da lažno pozitivnih izidov ne more biti, saj je naš vzorec majhen (n = 3) in ne vsebuje izdelkov govorcev angleščine kot drugega jezika, a rezultati so spodbudni.
Precej bolj pestre pa so analize besedil AI1-AI3. Ocene posameznih orodij močno nihajo, a trendi so pri vseh enaki. Izpustili bomo Writer.com, ki je očitno nedorasel nalogi in ne prepozna ničesar, ter Quillbot, ki prav tako ne deluje najbolje. Esej A1, ki so ga napisali GPT-4o, Gemini in Copilot, so vsa orodja prepoznala kot nečloveški. Četudi je poziv vseboval navodilo, naj bo esej čim bolj človeški in da mora prestati preizkus, detektorjev ni prevaral. Najstrožji je Originality.ai, ki je vsem dodelil oceno 100 odstotkov umetna inteligenca, preostala orodja so bila konservativnejša. Zanimivo je tudi, da se GPT-4o odreže najbolje, medtem ko Gemini in Copilot resnično ne prepričata nikogar. Nenaravnost kar puhti iz njunih esejev.
Precej drugačna je situacija, ko smo umetno inteligenco prosili za poliranje besedila (AI2) iz znanstvenega članka o vodikovi vezi, ki ga je avtor teh vrstic pred 13 leti napisal v strokovni angleščini. V tem primeru je bil rezultat GPT-4o in Gemini očiten in enostavno prepoznaven kot umetna inteligenca, medtem ko je bil Copilot še najboljši. Nekatere detektorje je ukanil (ZeroGPT), drugih ni (Undetectable.ai). Pri prevodu poljudnega članka za Delo iz slovenščine v angleščino pa sta se GPT-4o in Gemini solidno izkazala, Copilot pa ni mogel skriti svoje nravi. Google Translate kot stari titan nalogo opravi brezhibno.
Primerjava med detektorji pa je še težja. Zdi se, kakor da se njihove napovedi razlikujejo brez očitnega razloga. ZeroGPT in Phrasly.AI sta izjemno usklajena. Undetectable.ai je nekoliko strožji, Originality.ai je izjemno strog. Nekatera orodja ponudijo še dodatne možnosti, denimo analizo razumljivosti ali enostavnosti besedila.
Kaj izbrati?
Pametnega odgovora ni, ker se področje prehitro spreminja. Tehnološki giganti praktično vsak mesec izdajo kakšno posodobitev jezikovnega modela, v ozadju se spreminjajo tudi detektorji. Videli smo, da se obnesejo zelo različno, rezultati pa so odvisni tudi od vrste naloge, ki jo zastavimo modelu. Želimo prevajati, pisati brez izhodišča ali morda zgolj preoblikovati osnutek – vsakokrat bo rezultat zelo različen. Morda želimo jezikovni model uporabiti za iskanje idej ali kot eno izmed vmesnih stopenj v piljenju izdelka, kar je sploh težko ali nemogoče prepoznati.
Na koncu pa velja premisliti še, s katerega zornega kota ocenjujemo rezultat. Če je neki jezikovni model ukanil večino detektorjev, so slabi ti ali je jezikovni model izvrsten? In seveda obratno, je model, ki ga vsi prepoznajo, slab ali pa so se zgolj detektorji navadili njegovega načina delovanja? Če bi skozi podobno analizo poslali vsa besedila v tej številki reviji, bi lahko z veliko natančnostjo poiskali njihove avtorje, če bi le imeli korpus predhodnih del posameznih piscev.
Detektorji umetne inteligence so torej koristni pomočniki, predvsem za pisce, ki zlahka preverijo, ali so spisali šablonsko in generično besedilo. Na drugi strani stojijo učitelji, uredniki, založniki – ti si lahko z orodji pomagajo, a se še zdaleč ne smejo zanašati nanje.
Doletela me je umetna inteligenca
Čeprav smo del razvitega sveta, nas še vedno vesti in iznajdbe dosežejo z zamudo. Medtem ko so newyorške šole v začetku leta 2023 prepovedale uporabo generativne umetne inteligence, smo se pri nas njene razširjenosti – uporabnosti in škodljivosti – zavedeli šele letos.
V svojem poklicu imam nemalo opravka s študenti. Čeprav Kemijski inštitut ni fakulteta in ne vodi izobraževalnega programa, imamo čez palec zaposlenih sto doktorskih študentov, izmed katerih je pol ducata 'mojih'. Hkrati predavam dvoje predmetov na eni izmed mlajših univerz in tudi z nadarjenimi in vedoželjnimi dijaki se pogosto srečujem.
Znanost, zlasti naravoslovna, se komunicira, žal pa tudi čedalje bolj vrednoti, skozi objavljene znanstvene članke. Četudi se vsi strinjamo, da so hiperprodukcija člankov, mentaliteta Objavljaj ali se poslovi (Publish or perish) in kvantitativni kazalniki velikanski problem, obstajata pri razumevanju pomena sposobnosti kakovostne ubeseditve dva tabora. Po mojih izkušnjah večji del v tehniki in naravoslovju meni, da je način upovedovanja nepomemben, edina zveličavna veščina raziskovalca pa sposobnost postavljanja hipotez, širšega načrtovanja in izvajanja eksperimentov ter analize rezultatov, morda še risanja ličnih grafov. Drugi tabor ne vidi poklica raziskovalca, temveč poklicanost znanstvenika, ki mora biti sposoben tudi elokventno zapisati svoje misli, rezultate nanizati v prepričljivo in argumentirano zgodbo, podatke predstaviti koherentno.
Študentje razen častnih izjem sodijo v prvo skupino, zato vidijo velike jezikovne modele kot naročene. Napišemo okorno besedilo, morebiti celo zgolj v alinejah skiciramo ključne poudarke, in jih vprežemo za pripravo rokopisa in likanje čistopisa. Letos sem od študentov prvikrat dobil članke, v katerih so svoje raziskovalne rezultate opevali brezhibno, a sterilno. V predobri, a hkrati prerevni angleščini, kakorkoli protislovno to zveni. Moji študentje so – z zamudo, pristavim cinično – odkrili ChatGPT.
Gotovo tudi zaradi nacionalne pestrosti oddelka, na katerem nihče ni materni govorec angleščine, tovrstni izdelki resnično izstopajo. Ne gre za izdajalske podaljšane pomišljaje, značilnost alinejskost z emotikoni ali šablonski sklep na koncu besedil, temveč za občutek jezikovne preobloženosti, a hkrati vsebinske praznosti. Po skoraj dveh desetletjih dela v znanosti preprosto vem, kakšne izdelke lahko pričakujemo od študentov v posameznih letnikih doktorskega študija, predvsem pa so to 'moji' študentje. Vsak teden jih videvam, vem, kaj počnejo, kako se izražajo, česa so sposobni. Če bi me umetna inteligenca pretentala, bi to povedalo največ o moji (ne)angažiranosti kot mentorja.
Tovrstne izdelke sem vsakokrat brezkompromisno zavrnil, pri čemer argument nikoli ni bil uporaba umetne inteligence. Argument je bil vedno ad rem, torej jezikovne ali vsebinske šibkosti besedila, pri čemer rabo generativnih modelov mestoma navedem kot mogoči vzrok za te pomanjkljivosti. Resnični – dasiravno ga utemeljeno sumim – me ne zanima.
Obenem pa študentom in mlajšim kolegom zabičam, naj za božjo voljo uporabljajo umetno inteligenco, a premišljeno. Urejanje formata referenc v življenjepisu, razhroščevanje kode v Pythonu, iskanje jezikovnih napak v napisanem besedilu ali izluščenje relevantnih podrobnosti iz dolgih tehničnih besedil so veščine, na katerih uporabo umetne inteligence vsako leto predstavljam na oddelčnem seminarju. Navsezadnje tudi koreniti ne znamo več brez kalkulatorja, pa zato nismo neumni.
Kot veje že iz tona, izmed omenjenih taborov odločno podpiram drugega. Če bi menil drugače, bi gotovo zbral drugačen poklic. Menim, da je kovanje dobrega besedila bistveno več od pisanja besed. Resda gre za obrt, a prav to obrtništvo ima pomembne stranske učinke, ki so ravno znanja, veščine in kompetence, ki jih privzgajamo doktorandom. Pisanje – v kakršnikoli obliki – zahteva premislek, ki je nujni pogoj za ustvarjanje vednosti in usvajanje znanja. Kot je rekel zgodovinar David McCullough pred dvema desetletjema: »Pisanje je mišljenje. Dobro pisati pomeni jasno misliti. Prav zato je to tako težko.« Stari Grki niso po naključju šteli trivija, torej slovnice, logike in retorike, kot temelja za višje izobraževanje. Ali zelo neoliberalno: doktorat ni zastonj, ni enostaven in ni kratek – kakšna neverjetna škoda bi ga bilo zapraviti s kopiranjem polizdelkov umetne inteligence.