Že 30 let na internetu vztraja prostovoljni dogovor, ki zapoveduje lepo vedenje pajkov tehnoloških gigantov. In ti ga v veliki meri upoštevajo. Razvoj umetne inteligence pa je prinesel prve resne izzive, saj so interesi spletišč in ponudnikov umetne inteligence dovolj različni, da so zadnji nemalokrat ignorirali gentlemanski dogovor, ki je veljal desetletja.

Pred 30 leti je bil internet manjši in bolj obvladljiv kot danes. Shajali smo tudi brez iskalnikov, zadostovali so seznami spletnih strani in priporočila prijateljev, sčasoma pa smo točno vedeli, kam zaviti in komu pisati. Razlika je bila zares neverjetna, saj je bilo leta 1994 na internetu milijonkrat manj strani kot danes.
Šele konec leta 1994 je izšel legendarni brskalnik Netscape Navigator, število spletišč pa je zraslo z dobrih 600 na začetku leta do približno deset tisoč konec leta. Tistega leta je zaživela tudi stran Yahoo, v Sloveniji pa smo se orientirali na sveži Matkurji, ki je bila nekakšen splošni imenik.
Današnji internet je v številnih pogledih bistveno drugačen, a na (skoraj) vsaki domeni še danes najdemo datoteko z enakim imenom in istovrstno vsebino, kot si jih je leta 1994 zamislil Martijn Koster. Datoteka robots.txt je preživela dolga tri desetletja, a zdi se, da ji je umetna inteligenca zdaj zabila zadnji žebelj v krsto. Bodimo pravzaprav pošteni – tega ni storila umetna inteligenca, temveč s svojo lakomnostjo človeška inteligenca, ki vodi podjetja za razvoj umetne inteligence.
Roboti niso zaželeni
Zgodnji internet so sestavljale strani, ki so večinoma gostovale na manjših, neodvisnih strežnikih. Enega takšnih je upravljal nizozemski računalnikar Martijn Koster, ki je tedaj delal v britanskem podjetju Nexor in je med drugim leta 1993 spisal tudi prvi iskalnik ALIWEB (Archie-Like Indexing for the Web). Ta je za nekaj mesecev prehitel WebCrawlerja, ki je aktiven še danes.
Podrobnosti nastanka datoteke robots.txt so delno izgubljene v labirintih zgodovine, ker si vsak izmed akterjev zgodbo predstavlja nekoliko po svoje, a največkrat ponovljena različica gre nekako takole. Pajek Websnarf, ki je za istoimenski iskalnik želel indeksirati internetne strani, je februarja 1994 zaradi napačne konfiguracije Kosterjev strežnik obiskal tolikokrat, da je ta pokleknil. Koster se je zato domislil, da bi lahko podobne pajke lepo prosil, naj njegov strežnik preskočijo. Čeprav se zdi tak pristop danes neverjeten, ne pozabimo, kako zelo drugačen je bil internet leta 1994. Bolj kot na današnjo džunglo strani, ljudi, korporacij in interesov je spominjal na prijazen vaški trg, kjer so se skoraj vsi poznali in je vladalo medsebojno zaupanje.
Nekoč je Google za vsakih 10–20 obiskov pajka na spletno stran poslal enega človeškega uporabnika. Danes ima Anthropicov ClaudeBot to razmerje 70.000 : 1, pajki OpenAI pa dosegajo vrednosti okoli 2.000 : 1.
Če bi torej pajke lepo prosil, naj spletne strani ali določenih podstrani ne obiskujejo, ali pa bi jim postavil omejitve frekvence obiskov, ni prav nobenega razloga, da tega ne bi spoštovali, je razmišljal Koster. Od njegove naivnosti je bolj fascinantno zgolj dejstvo, da je več kot 20 let to v resnici delovalo, neuradnega standarda so se prostovoljno držali tudi največji velikani.
Namesto dobrodošlice
Prva različica ideje je uporabljala datoteko RobotsNotWanted.txt, ki je pozneje postala preprosto robots.txt. Še danes je to ena izmed datotek, ki bo prisotna na skoraj vsaki domeni, zato jo pajki uporabijo kot dobrodošlico oziroma prvo informacijo, kam se smejo napotiti. Če je ni, je dovoljen vsakršen obisk brez omejitev.

Primer datoteke robots.txt.
Zaradi svoje zgodovine je robots.txt preprosta besedilna datoteka in ne kakšen novejši format XML ali podobno in zato je razumljiva tudi ljudem. Vsebuje tri glavne ključne besede: user-agent, kjer navedemo ime pajkov, za katere veljajo posamezna pravila, ter allow in disallow za podstrani, ki jih smejo ali ne smejo obiskati. Uporabiti je moč tudi jokerje, denimo * za vse (preostale) pajke ali podstrani. Nianse so pomembne, saj zapis »disallow: /« pomeni prepoved za vse podstrani, zapis »disallow:« pa za nobeno (ker je seznam prazen).
Spletne strani želja uporabnikov niso spoštovale
Poldrugo desetletje po uveljavitvi robots.txt se je pojavila še ena prostovoljna iniciativa, ki pa zaradi spremenjenega okolja nikoli ni zares zaživela. Leta 2007 so se pojavile prve zamisli o uvedbi mehanizma, s katerim bi obiskovalec spletni strani izrecno sporočil, da ne želi sledenja. Do Not Track (DNT) je leta 2009 življenje začel kot vtičnik za Firefox, ki so ga kasneje posvojili tudi Chrome, Safari, Internet Explorer, Edge, Opera in drugi.
Vloge so bile torej obrnjene, saj smo od spletnih strani pričakovali prostovoljno spoštovanje želja drugih akterjev. Sprva je kazalo, da se bo DNT uveljavil, a je v dveh letih postalo jasno, da bo ostal mrtva črka na papirju. Leta 2012 je Internet Explorer privzeto vključil DNT za vse uporabnike, kar je močno razburilo oglaševalce. Ti so ves čas zagovarjali, da mora uporabnik sam, informirano in aktivno izbrati DNT, ne pa da je prednastavljen za vse. Ko je tudi delovna skupina pri W3C po letu 2013 praktično nehala delovati, je bil DNT že klinično mrtev.
Podrobno smo o zgodovini DNT pisali februarja (Zaton dobre zamisli, Monitor 02/25).
Na takšen način so nato ustvarjene datoteke robots.txt, ki segajo od dvovrstičnih do nekaj sto vrstic natančnih navodil. Eno daljših ima Wikipedija, Monitor pa precej krajšo. Ogledamo si jih lahko tudi sami, če v naslovno vrstico v brskalniku preprosto vpišemo www.monitor.si/robots.txt.
Zares je neverjetno, da se tudi danes v zelo veliki meri robots.txt spoštuje, pa čeprav gre le za vljudno prošnjo. Eden izmed pomembnih razlogov je zgodovinski, saj je robots.txt nastal leta 1994 v povsem drugačnem okolju od današnjega, nato pa nihče izmed velikih igralcev ni želel spremeniti statusa quo. Še danes vljudno prošnjo spoštujejo tudi največji, denimo Google, Bing, DuckDuckGo, Yahoo!, Yandex in drugi.
Kako zelo prostovoljen je (bil) robots.txt, priča Googlov predlog iz leta 2019 (!), da bi delovna skupina za standardizacijo interneta in protokola TCP/IP, IETF (Internet Engineering Task Force), standardizirala tako imenovani Robots Exclusion Protocol. Standard RFC 9309 je nato luč sveta ugledal leta 2022, skoraj tri desetletja po prvi uporabi robots.txt. Ves ta čas je obstajal kot de facto standard, ki ni bil nikjer formalno opredeljen.
Wikipedija je letos zabeležila osem odstotkov manjši človeški obisk kot v istem obdobju lani, kar se je zgodilo prvikrat.
To pa ne pomeni, da ni bil preizkušen tudi na sodišču. V eni prelomnih sodb, ki je zacementirala njegovo spoštovanje, je eBay leta 1999 tožil podjetje Bidder's Edge, ker je njihov pajek zbiral podatke o dražbah z njegovih strani. To je eBay prepovedoval tako v pogojih uporabe kakor v robots.txt. eBay je za krajši čas podjetju dovolil zbiranje podatkov s svoje spletne strani, a nato podjetji nista našli skupnega jezika o tehničnih podrobnostih, zlasti o pogostosti tega početja. Na koncu se je eBay odločil, da Bidder's Edge tega ne sme več početi, njihove IP pa so tudi fizično blokirali. A Bidder's Edge je početje nadaljeval prek posredniških strežnikov, zato je decembra 1999 eBay vložil tožbo. Sodišče je sprva pritrdilo eBayu in izdalo začasno odredbo, da mora Bidder's Edge prekiniti plazenje po eBayevih spletnih straneh, ker da gre za motenje posesti (trespassing). Podjetji sta se kasneje poravnali, popustil je Bidder's Edge.

Pred leti je Google postavil tudi šaljivi killer-robots.txt kot referenco na Terminatorja.
Začetek konca
Prostovoljne zaveze se začno krhati, ko se posamezni igralci začno odločati, da jih ne bodo več spoštovali. Četudi imajo morda argumentirane razloge, to neizbežno sproži plaz podobnih razmislekov pri vseh ostalih akterjih, kar se nemalokrat konča z žalostnim koncem. Robots.txt sicer še ni tako daleč, dasiravno mu je že precej velikih igralcev obrnilo hrbet. Začelo se je, kot ponavadi, na videz neškodljivo.
Aprila 2017 je direktor Wayback Machina, Mark Graham, sporočil, da se datoteke robots.txt ne ujemajo s cilji Wayback Machina, ki deluje v okviru Internet Archiva in si prizadeva arhivirati spletne strani, kakršne so bile v posameznih trenutkih. Internet Archive želi ustvariti čim bolj celovite in pristne zgodovinske posnetke spletnih strani – kar ima zelo koristne učinke, denimo pri navajanju spletnih virov, ko se tudi Wikipedija sklicuje nanje –, zato mu prepovedi v robots.txt niso povšeči. Graham je trdil, da so navodila v robots.txt namenjena pajkom, ki jih uporabljajo iskalniki, ne pa obče koristni rabi, kakršno zasleduje Internet Archive. Na načelni ravni se s tem lahko strinjamo, a hudič se skriva v podrobnostih. Ko pravila nehajo veljati za nekoga, se krhko soglasje hitro začne rušiti.
Zemljevid strani
Obratno nalogo od datoteke robots.txt opravljajo zemljevidi strani, ki običajno domujejo v datotekah sitemap.xml. Posamezno spletišče jih lahko ima več, pot do njih pa bo zapisana prav v robots.txt.
Sitemaps je zemljevid organiziranosti spletnih strani na domeni, ki služi kot kažipot in povabilo za pajke, katere strani naj obiščejo. Oblikovan je v formatu xml, poleg naslovov podstrani pa lahko vsebuje tudi dodatne informacije, denimo, kdaj je bila posamezna podstran posodobljena, kako pogosto se posodablja, kje v logični strukturi spletišča se nahaja in kako pomembna je. Z uporabo tega zemljevida lahko pajki učinkoviteje prečešejo spletišče in najdejo tudi osamelce, do katerih neposredno ne vodi nobena povezava na strani.
Sitemaps je sicer mlajša tehnologija, ki jo je iz povsem logičnih razlogov leta 2005 uvedel Google. Danes te zemljevide z veseljem uporabljajo vsi iskalniki, poleg naslova v robots.txt pa lahko lokacijo sitemaps za lastno spletno stran neposredno posredujemo iskalnikom v upanju, da bodo čim prej in čim bolje poindeksirali naše spletišče. Vsi iskalniki opozarjajo, da to ni zagotovilo, da bodo res obiskali celotno strukturo, a da običajno to storijo.
Protokol Sitemaps se od leta 2006 ni spremenil v nobeni pomembni obliki. Logika je dobro zamišljena in deluje, zato potrebe po nadgradnjah ni bilo.
Graham je tedaj dejal, da so že pred meseci prenehali spoštovati robots.txt na vladnih in vojaških spletnih straneh, pa niso opazili nobenih neželenih stranskih učinkov. Zato so napovedali razširitev te politike in danes, osem let pozneje, Internet Archive ne spoštuje več robots.txt. Žal še zdaleč ni edini. Tedaj je Graham sicer namignil, da bi želel kakšno drugo rešitev, ki bi nastala v sodelovanju več deležnikov, a se to ni zgodilo.
Varnost
Kljub strogemu besedišču (allow in disallow) je bil robots.txt od nekdaj le prošnja, vljuden namig. Če ga pajki niso spoštovali, so lahko upravljavci spletnih strani le nemočno zavzdihnili ali pa uporabili močnejša orožja. Takšna nuklearna možnost je seveda blokiranje posameznih naslovov IP, ki je še danes pogost ukrep iz zelo različnih razlogov, od pravnih (ko se tuje strani ne želijo ukvarjati z evropsko zakonodajo) do tehničnih (boj proti spamu ali napadom DDoS).

Martijn Koster je leta 1994 takole napovedal robots.txt.
Marsikdo bi pomislil, da je lahko robots.txt tudi kontraproduktiven ali dejansko škodljiv. V datoteki, ki tiči na predvidljivem mestu in je dostopna vsakomur, so namreč nanizane podstrani, ki se želijo aktivno skriti pred pajki. Celemu svetu torej razglašamo, kam naj pajki ne pogledajo. Mar ni to ravno najboljše povabilo, da vendarle pokukajo tja? Če robots.txt in druga orodja za zaščito spletnih mest uporabljamo pravilno, to ni problem.
Robots.txt nikoli ni bil mišljen kot orodje za zagotavljanje varnosti ali prikrivanje podatkov. Razvil se je kot orodje za obvladovanje obiska na spletni strani, da pajki strežnika ne bi preveč obremenili. V ta namen se uporablja nestandardna, a široko razumljiva ključna beseda crawl-delay, ki določa zamik med zaporednima poizvedbama pajka, isto pa lahko dosežemo tudi z vrnitvijo napake 429 (Too Many Requests).
Poleg tega robots.txt omogoča boljše rangiranje spletnih strani v iskalnikih. Številna spletišča imajo podvojene strani in druge strani, ki jih iskalniki ne bi rangirali prav visoko ali bi jih celo kaznovali. Robots.txt se zato uporablja za SEO (search engine optimization), da so iskalnikom res vidne tiste podstrani, ki štejejo. Prav tako si morda ne želimo, da bi bile posamezne bolj zasebne podstrani indeksirane, dasiravno niso skrivnost in ni nobena katastrofa, če jih kdo vidi. To so nameni, zaradi katerih obstaja robots.txt.
Po drugi strani pa ni bil nikoli namenjen zaščiti pred dostopom ali varovanju posameznih informacij. V informacijski varnosti je že dlje časa jasno, da varnosti ni mogoče doseči s skrivanjem (security through obscurity), temveč z ustreznim načrtovanjem tehničnih specifikacij (security by design). To priporočajo vse avtoritete na tem področju, od slovenskega SI-CERT do ameriškega Nacionalnega inštituta za standarde in tehnologijo NIST).
Zidovi
Kakor moderne aplikacije za šifrirano sporočanje ne računajo na skrivne šifre, temveč na matematično nezlomljive ključe, tako moramo tudi spletne strani zaščititi drugače, odvisno od cilja. Naslovi IP, ki jih uporabljajo posamezna podjetja s svojimi iskalniki, so dobro znani. Google ima na svojih spletnih straneh objavljena imena pajkov (npr. googlebot), njihove domenske naslove (reverse DNS mask, npr. crawl-***-***-***-***.googlebot.com) in vse pripadajoče naslove IP. Kdor želi, lahko na svojem strežniku te naslove blokira.

OpenAI javno razkriva, s katerih naslovov prihajajo njegovi pajki.
Internet danes je precej drugačen, obvladujejo pa ga veliki igralci, ki so povzročili fragmentacijo v konkurenčne silose. Namesto vsesplošnega sodelovanje, povezovanja in spoštovanja današnji internet temelji na pogodbah, plačilih in tehničnih ovirah v obliki različnih vrst avtentikacij. Plačljivi dostop prek različnih vmesnikov API, plačljivi zidovi (paywalls) in ekskluzivne licence so dandanes sestavni del interneta.
Požrešna inteligenca
Status quo, v katerem je robots.txt relikt nekega drugega časa, ki pa ga s stisnjenimi zobmi večina legitimnih akterjev spoštuje, je vztrajal do vzpona umetne inteligence. V aktualnem desetletju na internetu mrgoli pajkov nove vrste, ki so jih ustvarili in v divjino spustili avtorjih velikih jezikovnih modelov. Umetna inteligenca je pametna le toliko, kolikor človeških izdelkov prebere, najlažje pa do njih pride na internetu. Ovire, kot je mila prošnja za izogibanje posameznim podstranem, pa ne morejo stati na poti razvoja najpomembnejše tehnologije moderne dobe, so pomislili razvijalci umetne inteligence.
Javno tega ne priznavajo, a situacija je v praksi precej neurejena. Junija lani je podjetje TollBit, ki se ukvarja z licenciranjem vsebin na spletu, imetnike avtorskih pravic opozorilo, da po njihovih podatkih razvijalci umetne inteligence ne spoštujejo robots.txt. Javno niso želeli izpostaviti nobenega podjetja, a so to storili drugi. Forbes je javno obtožil Perplexity, da brez dovoljenja in v nasprotju z robots.txt zbira podatke. Tudi neodvisna novinarska preiskava revije Wired je potrdila, da Perplexity kljub prepovedi svoje pajke pošilja prečesavat Forbesove strani.
Še danes Forbes kot nezaželene označuje pajke vseh večjih razvijalcev umetne inteligence (Amazonbot, anthropic-ai, Applebot-Extended, Bytespider, CCBot, ChatGPT-User, ClaudeBot, cohere-ai, Diffbot, FacebookBot, FriendlyCrawler, GPTBot, ImagesiftBot, meta-externalagent, Meta-ExternalAgent, omgili, omgilibot, PerplexityBot), izrecno pa dovoljuje iskalnik OAI-SearchBot. Pri tem ni edini, saj podobno želijo tudi drugi veliki založniki, denimo The New York Times. TollBit pravi, da Perplexity ni edini kršitelj.
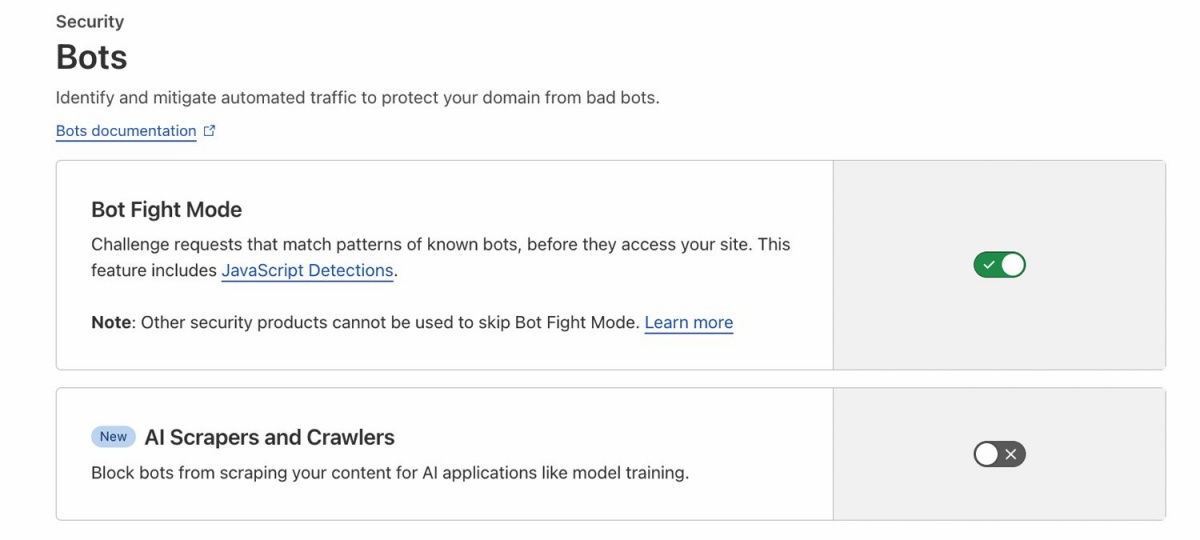
CloudFlare za svoje stranke nudi različne stopnje zaščite.
Business Insider je lani poročal, da OpenAI in Anthropic za potrebe svoje umetne inteligence z interneta strgata ogromne količine podatkov. Četudi sta trdila, da spoštujeta robots.txt, je Business Insider opazil več indicev, da to ne drži vedno.
Tudi danes situacija ni urejena. Cloudflare, ki gosti ali varuje ogromno spletnih strani in ima tudi zaradi tega unikaten vpogled v dogajanje na internetu, je avgusta Perplexity ponovno obtožil nespoštovanja robots.txt. Perplexity ni zgolj ignoriral navodil, temveč so se njegovi pajki namenoma prikrivali in izdajali za druge uporabnike (tako da so spremenili polje user agent). Perplexity je vsa namigovanja in obtožbe zavrnil, rekoč, da želi Cloudflare zgolj oglaševati in prodajati svoje storitve. A drži lahko oboje.
Tu smo že bili
Dolga leta je na internetu vladalo zavezništvo. Spletne strani so bile vesele obiska Googlovih pajkov, ker je indeksiranje spletišča v iskalnikovi zbirki predstavljalo zagotovilo, da bo stran vidna med rezultati iskanj. Iskalniki in strani so živeli v sožitju, kjer so iskalniki v zameno za indeksiranje na spletno stran usmerjali iskalce in ji s tem zagotavljali promet, to pa se prevede v prihodke.
Prvi znaki krhanja tega odnosa so se pojavili že pred umetno inteligenco, ko si je Google zamislil, da bi v storitvi Google News stregel precej obsežne povzetke novic. Ker je to predstavljalo nevarnost, da uporabniki sploh ne bodo več obiskali primarnega vira, so založniki povzdignili glas. Po večmesečnem napenjanju mišic, obojestranskih grožnjah in tožbah je Google moral popustiti in s številnimi skleniti dogovore o odplačni uporabi novic. Google je Kanadi pred dvema letoma celo grozil, da bo v državi preprosto ukinil Google News.
Manjkalo ni niti kazni, denimo 500-milijonska globa, ki jo je pred štirimi leti Googlu izrekla Francija, ker se ta ni pogajal v dobri veri. Takšno pogajanje mu zapoveduje francoska zakonodaja. Še eno, 250-milijonsko globo si je Google prislužil lani, prav tako v Franciji. Sklenitev tovrstnih dogovorov zahteva čedalje več držav, denimo Avstralija in Kanada, ki krog zavezancev širita, tako da bodo dogovore sklepali tudi upravljavci družbenih omrežij, denimo Meta.
Na kocki je preživetje
Zdi se, da tečemo še en krog istih razprav, le da je na kocki še več, ne »le« založniki in novinarske hiše. Google že nekaj mesecev pri iskanju na vrhu strani, še preden prikaže seznam rezultatov, izpiše povzetek informacij z več relevantnih spletnih strani, ki ga je ustvaril Gemini. Tudi drugi modeli umetne inteligence so že zelo dobri pri iskanju, agregiranju in povzemanju informacij s spleta. Uporabnik lahko dobi vso, predvsem pa kakovostno informacijo neposredno v ekosistemu Perplexity ali OpenAI, ne da bi obiskal eno samo spletno stran, s katere izvirajo informacije. To pa predstavlja eksistencialno težavo, ker stranem obisk začenja upadati. Brez obiska pa ni denarja.
Česa robots.txt ne more
Robots.txt je prostovoljen tehnični signal, ki je namenjen usmerjanju pajkov. Sam ne more preprečiti indeksacije (za to se uporablja oznaka noindex), ne zagotavlja zasebnosti, predvsem pa ni pravna podlaga. Ne daje nobenih jamstev zaščite pred zlonamernimi pajki in ne more fizično blokirati dostopa pajkom ali uporabnikom, ki se pravil ne držijo.
Ne gre le za teoretične strahove, temveč so trendi že opazni. Spletne strani merijo razmerje med pajki in človeškimi obiskovalci, ki so jih ti pajki oziroma njihovi skrbniki nato napotili na stran (crawl-to-referral ratio). V dobrih starih časih pred izumom modernih jezikovnih modelov je bilo to razmerje med 10 : 1 in 20 : 1, kar je bilo obvladljivo. Za vsakih 10–20 obiskov Googlovega pajka je Google na stran poslal enega človeškega uporabnika. Agenti in pajki umetne inteligence so to razmerje povsem izmaličili. Anthropicov ClaudeBot ima to razmerje 70.000 : 1, so junija letos ocenili pri Cloudflaru. Pajki OpenAI pajki dosegajo vrednosti okoli 2.000 : 1. Spletišča trpijo zaradi sprememb na obeh straneh enačbe: rastoči promet zahteva močnejše in dražje strežnike (ali zakupe gostovanja), čedalje manj človeških obiskovalcev pa klesti prihodke. Roboti pač ne gledajo reklam.
Wikipedija je letos zabeležila osem odstotkov manjši človeški obisk kot v istem obdobju lani, kar se je zgodilo prvikrat. Podobne trende opažajo tudi na drugih spletnih straneh, pametnih rešitev pa še ni. Eno izmed novih pobud je zagnal Cloudflare in se imenuje Content Signals. S tem mehanizmom želijo dati založnikom možnost, da na ravni kategorij določajo pravice za dostop. Kategorije so ai-train, ai-input, search in podobno, s čimer se izognemo mukotrpnemu naštevanju vseh znanih (in neznanih) pajkov, ki delajo za umetno inteligenco. Tudi tu velja prostovoljno upoštevanje, trenutno pa še ne gre za standard, temveč produkt komercialnega podjetja.
Svet je danes drugačen
Še pred desetimi leti je bil internet drugačen, bolj sproščen. Google je tedaj v šali na svoje domene postavil tudi datoteko killer-robots.txt, v kateri je za agenta T-1000 in T-800 prepovedal dostop do Larryja Pagea in Sergeya Brina. Referenca na franšizo Terminator bi bila težko bolj očitna. Kakšna spletna stran ima še danes tudi datoteko humans.txt, ki je namenjena ljudem. V praksi se ne uporablja, pred desetimi leti pa ja zaživela kot napol šaljiv antipod robots.txt. Še vedno jo nudita The New York Times in Google.
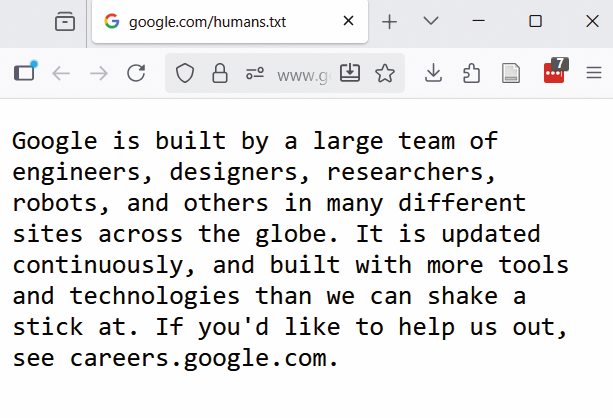
Nekoč so spletne strani uporabljale tudi humans.txt, kar je danes redkost.
Prihodnost robots.txt ostaja nejasna. Za zdaj si nihče izmed velikih ne upa javno napovedati, da ga ne bo več spoštoval, četudi za zaveso marsikdo to tudi počne. A prepričani smo lahko, da se bodo evropski regulatorji odzvali, če bodo tehnološki velikani začeli ogrožati zasebnost Evropejcev ali preživetje spletnih strani. Evropski odbor za varstvo podatkov (EOVP) je decembra lani že sprejel mnenje o uporabi osebnih podatkov za razvoj in uvedbo modelov umetne inteligence. Med drugim poudarja stališče, da je robots.txt tehnični signal, ne pa pravna podlaga.
Evropska komisija je že večkrat pokazala, da se ne boji odločno ukrepati proti tehnološkim velikanom. Upamo lahko, da bo robots.txt preživel brez sodne prisile kot lep ostanek nekih drugih časov.







