Zakaj računalniki ne znajo (niti) brati - Kdo je jedel magdalenice?
Umetna inteligenca in globoko učenje blestita pri analizi velikih količin besedil in luščenju statističnih korelacij. Čeprav noben človek ne more prebrati vseh besedil, je človeško razumevanje prebranega na kvalitativno višji ravni kot pri umetni inteligenci. A tudi pri šahu smo bili včasih neprekosljivi …
Umetna inteligenca je v preteklem desetletju izjemno napredovala in nikjer ni to očitneje kakor pri razumevanju naravne besede. Google ni več le iskalnik po ključnih besedah, temveč do neke mere razume človeška vprašanja. Vprašajmo ga »Kdaj je 1. januar postal prvi dan v letu?«, pa bo nad iskalnimi zadetki okvirček s kratkim odstavkom, da se je to prvikrat zgodilo leta 45 pr. n. št. To drži, je pa zgodovina prezapletena, da bi bil to celovit odgovor. V poznem starem in srednjem veku so to malo pozabili in šele s prehodom na gregorijanski koledar, kar se ni zgodilo v vseh deželah hkrati, je 1. januar dokončno postal prvi dan leta.
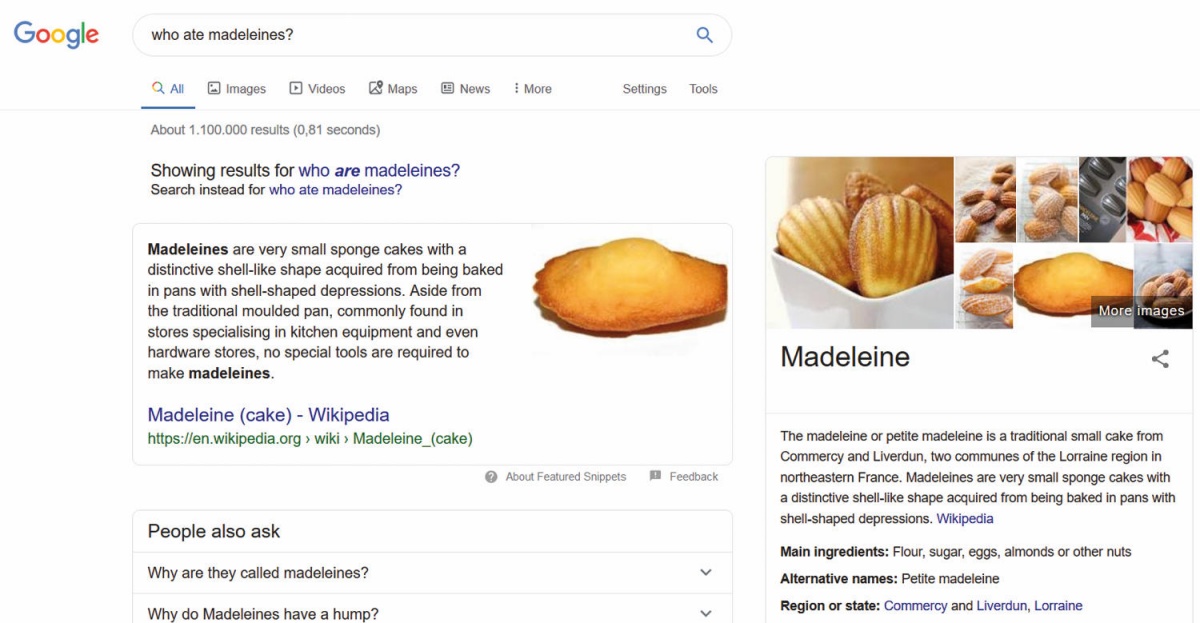
Po drugi strani pa lahko Google poskusimo vprašati »Kdo je jedel magdalenice?«, kar bi moral vedeti vsak splošno izobražen posameznik. V romanu V Swannovem svetu, ki ga bolj poznamo kot del cikla z naslovom V iskanju izgubljenega časa, je Marcel Proust magdalenice uporabil kot figuro pri opisu nehotnega spomina. Gre za odlomek iz cikla romanov, ki je za vedno spremenil književnost. Zaradi tega so magdalenice tako zelo znane. Čeprav se marsikdo ne spominja naslova romana ali skupnega naslova cikla, morda je že pozabil Proustovo ime, skoraj vsi vedo za magdalenice. Odgovor na vprašanje, kdo je jedel magdalenice, bi zato znal poiskati vsakdo. Vedel bi, da gre za prelomno književno delo, ki je kanon pouka književnosti v zahodnem svetu, da gre za slaven odlomek, ki uvaja nehotni spomin, da je evropsko delo. Te informacije bi zadostovale, da bi po nekaj časa brskanja ugotovil vse podrobnosti.
Uporaba tudi v komercialnih izdelkih
Prve drobce algoritemske obdelave besedil in pisanja že uporabljamo. Google že nekaj časa ponuja funkcijo Smart Compose, ki s predlogi za dokončanje stavkov lajša pisanje elektronskih sporočil v Gmailu. Poldrugo leto stara funkcija uporabi algoritme za razumevanje sporočila in ponudi najverjetnejše odzive. Paul Lambert, ki vodi razvoj te storitve, pojasnjuje, da so idejo dobili ob programiranju, kjer je veliko standardnega ponavljanja zapisanega, zato je samodokončevanje pogosta funkcija večine orodij. Smart Reply je ista tehnologija še v drugi obliki, torej za odgovarjanje na elektronska sporočila. V ozadju je precej pameti, tako da besedo »Lep« v petek pogosteje dopolni z »vikend« kakor v ponedeljek. Ker se uči na naših izdelkih, sčasoma pobere tudi ton in način pisanja, ki je značilen za avtorja.
Gmail uporablja Smart Compose za pametno dopolnjevanje sporočil.
Google na to vprašanje jedrnatega odgovora ne da. Poleg receptov in članka v Wikipediji se sicer pojavi nekaj zadetkov, ki omenjajo Prousta, a enostavnega odgovora, kdo in v katerem romanu jih je okušal, ne dobimo. Pa to ne pomeni, da je Googlova umetna inteligenca kakšno knjigo preskočila ali da je neumna – odgovor na to vprašanje zahteva preveč navzkrižnega znanja in razumevanja kulture, da bi ga umetna inteligenca lahko našla. Za zdaj.
Google še ne ve, da so Proustove magdalenice spremenile tok književnosti.
Kdo bo vse to prebral
Sredi lanskega leta je bilo na Youtube vsako minuto naloženih za 500 ur novih vsebin, pravijo uradni podatki iz Googla. Niti teoretično ni mogoče, da bi kdo vse to pogledal, kar je sprožilo marsikateri monolog o kakovosti vsebin in smiselnosti tega početja. A to sploh ni nov argument. Že ob izumu tiskarskega stroja so se intelektualci spraševali, kdo bo vse nove knjige prebral. Pred natanko desetletjem so v Googlu z algoritmi in s podatki iz projekta digitalizacije knjig ocenili, da je bilo v zgodovini napisanih 130 milijonov knjig. Do danes jih je nastalo gotovo še dvakrat toliko.
Že ob izumu tiskarskega stroja so se intelektualci spraševali, kdo bo vse nove knjige prebral. Danes vemo kdo – Google.
In to je tudi odgovor na vprašanje, kdo bo vse to prebral. Google jih je. Projekt Google Books se je začel leta 2004 in digitalizira vse knjige ter veliko periodike, ki se objavijo. Sodelujejo avtorji, založniki in knjižnice. Oktobra lani se je Google pohvalil, da so digitalizirali že 40 milijonov kosov gradiva. Anglosaška vsebina je nesorazmerno močno zastopana, a bolje to kot nič. Google torej vse ve, vprašanje pa je, ali razume.
Kaj se je mogoče na pamet naučiti iz knjig, ne da bi razumeli kontekst, si ahko pogledamo v projektu Google Talk to Books (books.google.com/talktobooks/). Medtem ko Googlov običajni iskalnik uporablja skrivni algoritem in informacije iz čim več virov, da bi nam postregel z relevantnimi odgovori, je Talk to Books osredotočen na knjige. Projekt je leta 2018 predstavil znameniti futurist Ray Kurzweil, ki je pri Googlu zaposlen kot vodja inženirjev. Talk to Books je spoj umetne inteligence in načitanosti iz knjig. Vprašanja sprejema v naravni angleščini, odgovarja pa s citati iz knjig, ki glede na algoritem najbolj ustrezajo. In odgovor na vprašanje, kdo je jedel magdalenice, je seveda predvidljivo napačen: rezultati so spet večinoma kuharske knjige z recepti.
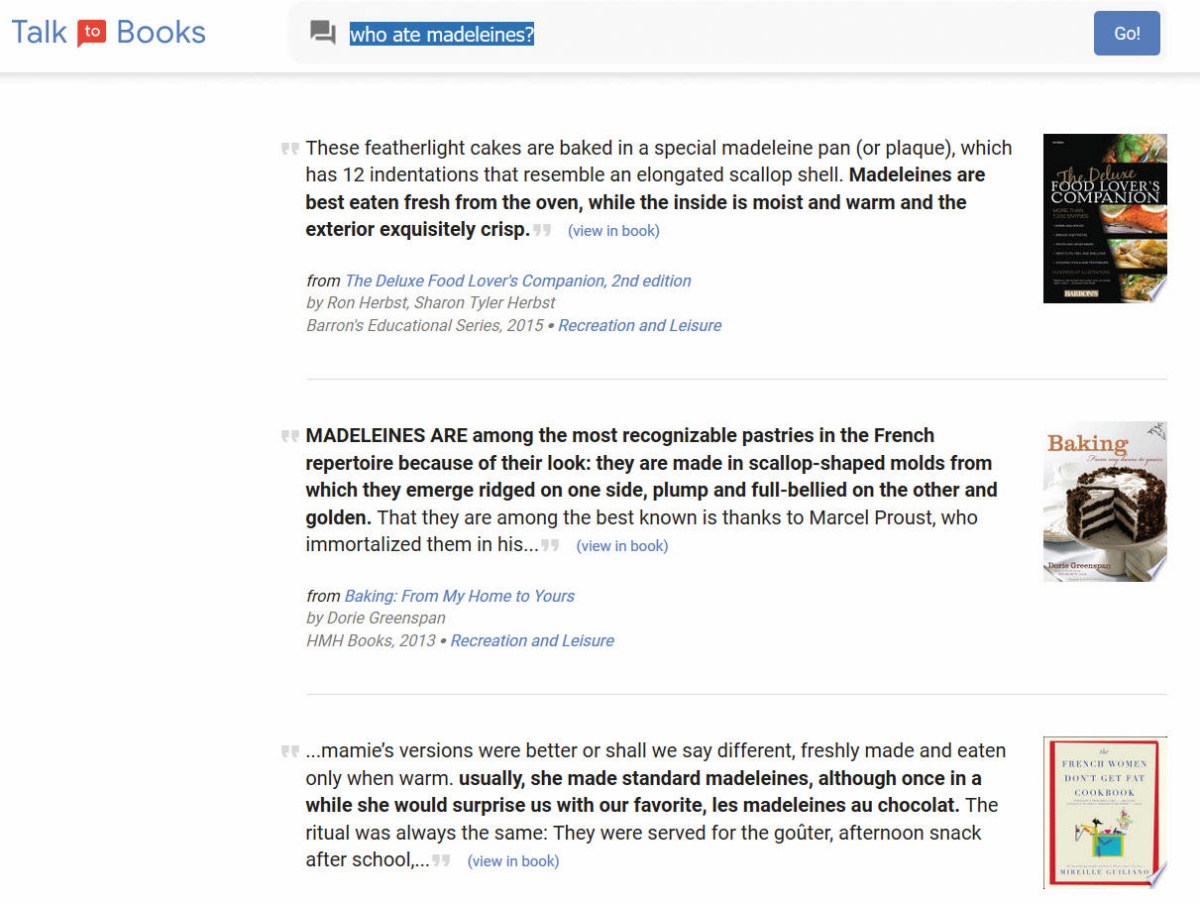
Tudi Google Talk to Books, ki vrača citate iz svetovne književnosti, ne ve, kdo je jedel magdalenice.
Vsakokrat ko prijatelju napišem »Človek nizkotnež«, mi bo brez izjeme odgovoril »se vsega navadi«. Citat, ki se nam je v možgane vtisnil med gimnazijskim prebiranjem Dostojevskega, sodi med sorazmerno znane odlomke. Za Google je to najlažji zalogaj. »Man grows used to everything, the scoundrel!« je pač dobesedno zapisan na koncu drugega poglavja romana Zločin in kazen. Talk to Books odgovor najde takoj. A zadostuje že, da stavek zasučemo v vprašalno obliko (Who is the scoundrel who gets used to everything?), pa niti Google niti Talk to Books nimata pojma, o čem se pogovarjamo. Kdor je preštudiral Dostojevskega, bi na takšno vprašanje odgovor izstrelil. Gre za več kot citat, gre za stavek, ki povzema eno osrednjih tem romana.
Kaj pomeni razumeti
Gary Marcus in Ernest Davis v knjigi Rebooting AI: Building Artificial Intelligence We Can Trust plastično analizirata, zakaj so ta vprašanja za umetno inteligenco tako težka. Razumeti besedilo je namreč tako neprimerno več kakor zgolj poznati pomen besed in sintakse, sposobnost človeškega uma za povezovanje koščkov informacij pa tako izjemna in lahkotna, da je razkorak težko doumeti. Kot primer vzameta odlomek iz otroške zgodbe Farmer Boy, ko Almanzo vpraša gospoda Thompsona, ali je morebiti izgubil denarnico. Ta se zdrzne, hitro potipa žep in krikne, da jo je res, in to s petnajstimi dolarji. Almanzo vpraša, ali je to tale, in gospod Thomson jo brž pograbi, prešteje bankovce in ugotovi, da ni nihče ničesar ukradel.
Tako preprost opis je za umetno inteligenco trenutno še nerešljiva uganka. Resnično splošna inteligenca (general artificial intelligence) bi morala znati odgovoriti na vprašanja, zakaj se je gospod Thompson potrepljal po žepu, ali je pred dogodkom vedel, da nima denarnice, na kaj je Almanzo mislil z zaimkom tale in ali je bil v denarnici še ves denar. Zdijo se trivialna, a odgovor zahteva poznavanje ogromno informacij, ki jih v besedilu ni. Med drugim moramo vedeti: da ljudje lahko nevede izgubimo predmete; da denarnice pogosto nosimo v žepu; da ob informaciji, da nekaj za nas pomembnega morda ne drži, želimo to takoj preveriti; da je denarnica pomemben predmet; da lahko s tipanjem žepa preverimo, ali je prazen; da je denar v obliki bankovcev; da vzeti denar iz tuje denarnice ni sprejemljivo in pomeni krajo. Vse to nakopičeno znanje ves čas nosimo s seboj in se ga sploh ne zavedamo, dokler ne poskusimo tega dopovedati računalniku ali ne beremo pravljic malim otrokom.
Računalniki pišejo
Februarja lani je laboratorij za strojno inteligenco OpenAI iz Kalifornije sporočil, da so izdelali algoritem za samodejno generiranje besedil, ki je prenevaren za splošno uporabo. OpenAI ni kar nek laboratorij. V njem sodelujejo tehnični direktor Greg Brockman, ki je bil svoj čas tehnični direktor zagonskega podjetja Stripe, Elon Musk, Sam Altman iz Y Combinatorja, Ilya Sutskever iz Google Braina in kot poslovni angeli Peter Thiel, Reid Hoffman in drugi. Microsoft je v OpenAI vložil milijardo dolarjev.
Algoritem GPT2 so v OpenAI sestavili pri raziskovanju strojnega prevajanja, botov za spletne pogovore in drugih aspektov strojnega učenja. Rezultat je bil algoritem, ki je sposoben dokončati vpisano besedilo na realističen in človeški način. Po mnenju OpenAI je predober, da bi ga spustili v javnost, ker bi to izrabili troli in manipulatorji za širjenje dezinformacij.
Razumeti moramo, da je OpenAI profitna ustanova, ki ji je seveda v interesu ustvariti čim več zanimanja za svoje izdelke. In res, novembra so zloglasni algoritem GPT2 (verzijo 1558M) priobčili spletu, da se lahko z njim igra vsakdo. Najdemo ga na spletni strani Talk to Tranformer (talktotransformer.com), kjer v okencu vpišemo besedilo v angleščini, kliknemo Complete text in opazujemo, kako je algoritem dokončal besedilo. Rezultati so – zanimivi. Besedila so slovnično brezhibna, besedišče je sorazmerno bogato in v skladu z izvirnim besedilom, a vsebinsko je novo besedilo votlo. V okviru lahko preberete, kako stroji prevedejo in dopolnijo odlomek iz tega članka. Ni slabo, predvsem pa deluje bolj pismeno od številnih anonimnih komentarjev na internetu.
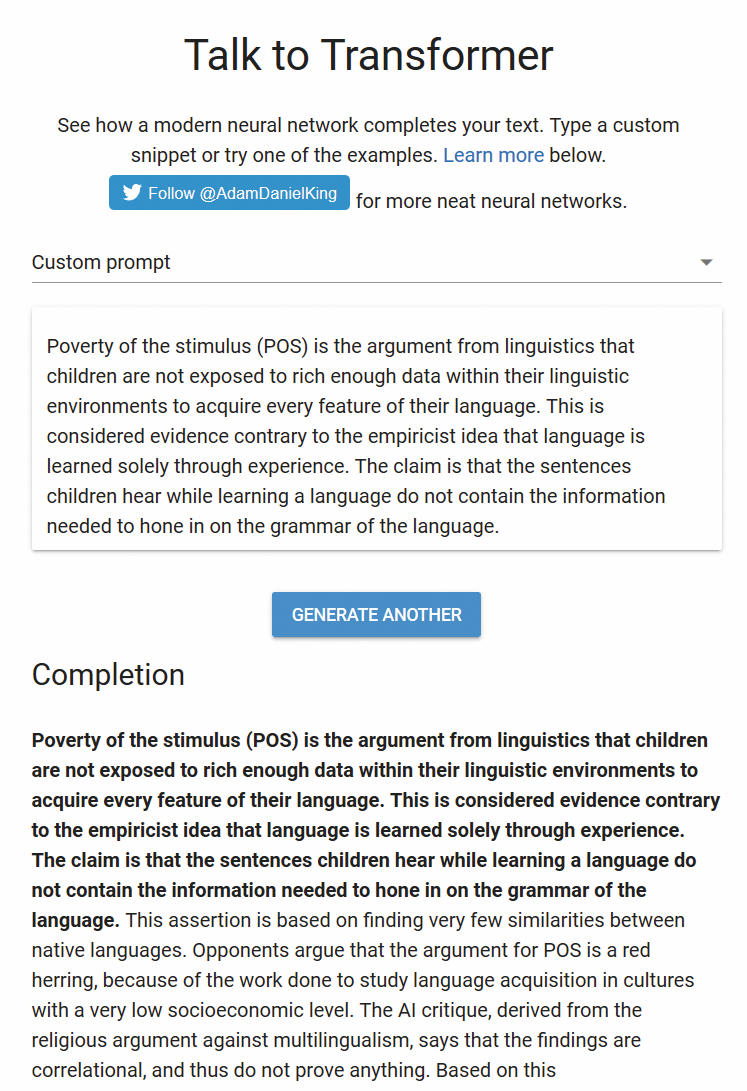
OpenAI Talk To Transformer (algoritem GPT2) dopolni vpisano besedil z bolj ali manj smiselnim nadaljevanjem.
Korelacije proti kompozicionalnosti
Vprašajte kogarkoli s solidnim znanjem angleščine, kaj pomeni »tender« in odgovor bo »nežen«. Vpišite to besedo brez konteksta v Google Translate in odgovor bo »razpis«. Tender seveda pomeni oboje (in še kaj več), Googlova prva izbira pa kaže, kako se računalniki učijo jezika.
Medtem ko ameriški lingvist Noah Chomsky trdi, da ostaja univerzalna slovnica, ki predstavlja podstat, nekakšno predpripravljeno v gene zapisano fizično sposobnost človeka za ustvarjanje in razumevanje jezika, računalniki te nimajo. Glavni argument za to teorijo je dejstvo, da smo v procesu učenja izpostavljeni zgolj majhnemu število mogočih konstrukcij, pa vseeno na koncu obvladamo jezik. Še več, otroci pri učenju maternega jezika v naravnem okolju večinoma niso izpostavljeni napačnim konstrukcijam, pa so vseeno na koncu sposobni za vsak stavek povedati, ali je pravilen ali ne. Teorija Chomskega ima precej nasprotnikov, a brez dvoma lahko rečemo, da računalniki nimajo nobenega čipa za dešifriranje jezika.
Računalniki se učijo z globokim učenjem, kjer nevronske mreže iščejo korelacije. Googlov algoritem za prevajanje se je prevajanja naučil tako, da je prebral ogromne količine besedil v več jezikih. Največji aparat za proizvajanje prevodov na svetu je bruseljska birokracija, kjer je »tender« običajno v pravnih jezikih »razpis«, saj prav veliko nežnosti v uradnih besedilih ni.
Globoko učenje je zelo učinkovito pri učenju korelacij. To pomeni, da bomo takšne modele zlahka naučili opravila, ki ga bomo ljudje videli kakor prepoznavanje fotografij. Poiskati korelacijo med fotografijo ptiča in besedo ptič ni težko in takšna nevronska mreža bo resnično sposobna poiskati vse mogoče fotografije različnih ptičev in ob tem izpisati besedo ptič. Toda takšna nevronska mreža še vedno ne bo razumela, kaj je to ptič, in za njo vulkan ne bo ptiču nič bliže kakor zmaj ali helikopter.
Zaradi tega ima globoko učenje težave, ko se mora naučiti razumeti besedila, torej prepoznati relacije med besedami. To je početje, ki ga naši možgani večinoma opravljajo samodejno in tako učinkovito, da se njegove kompleksnosti sploh ne zavedamo. Šele ko naletimo na stavek, ki nas zmede, pomislimo na besedne vrste in relacije med njimi. Leta 1982 je The Guardian objavil članek z naslovom British Left Waffles on Falklands. Komur se zdi čudno, da bi Britanci (British) pustili (left) vaflje (waffles) na otočju, ima prav. V resnici je britanska (British) levica (left) neodločno premlevala (to waffle), kaj storiti z otočjem. Že brez nadaljnjega konteksta zgolj z informacijo, da gre za vodilni članek v velikem dnevniku, človek pomisli, da interpretacija z vaflji bržčas ne more držati, in poišče novo. Ob branju članka dodaten kontekst potrdi pravilno interpretacijo.
Računalniška pamet vsega dodatnega nakopičenega znanja in globljega razumevanja nima. Ker je waffle redek glagol, ki se je uporabljal predvsem v britanski politiki v 80. letih preteklega stoletja, bi ta pomen statistična analiza sodobnih besedil zgrešila. Podobno v stavku The complex houses married and single soldiers and their families ob prvem branju večina govorcev angleščine zgreši pomen in šele nato ugotovi, da je glagol houses, married pa pridevnik.

Nekatere stavke lahko razumemo na več načinov.
V naravnem jeziku je pomembna še kompozicionalnost (Fregejev princip), ki pravi, da je pomen celote mogoče izračunati iz pomenov njenih sestavnih delov. Stavek »Sonce je 150 milijonov kilometrov od Zemlje« vsebuje točno določeni nebesni telesi (Sonce in Zemljo), enoto za razdaljo (kilometre), število (150 milijonov) in kopulo (je). Iz teh sestavin lahko prepoznamo, da je pomen tega stavka izraziti informacijo o razdalji med dvema nebesnima telesoma. Strojno učenje še nima načina, kako to kompozicionalnost upoštevati.
Algoritem GPT2 za samodejno generiranje besedil je po mnenju OpenAI predober, da bi ga spustili v javnost, ker bi to izrabili troli in manipulatorji za širjenje dezinformacij. Vseeno ga najdemo na spletni strani Talk to Tranformer (talktotransformer.com).
Pozna le ogromno kompleksnih korelacij, nima pa strukture. Tako umetna inteligenca ve, da ima avtomobil kolesa in motor, ne pozna pa njihove funkcije. Modeli nevronskih mrež ne morejo zaobjeti informacije, da je avtomobil prevozno sredstvo. Lahko se naučijo, da se avtomobil in prevozno sredstvo v besedilih pogosto pojavljata blizu, nimajo pa razumevanja, da se ljudje radi premikamo naokoli, da so nekatere razdalje nepraktične za ročno premagovanje in da lahko z avtomobilom pridemo samo tja, kjer so ceste.
Ko ljudje berejo besedilo, si v glavi gradijo kognitivni model zapisanega dogajanja, medtem ko računalniki ne. Tak kognitivni model nam omogoča, da po prebrani zgodbi odgovarjamo na različna vprašanja, napišemo različno dolge povzetke, prevedemo zgodbo ali jo predelamo.
Kam pes taco moli
To ne pomeni, da splošna umetna inteligenca ni zmožna biti tako sposobna kakor ljudje pri razumevanju besedil ali da računalniki nikoli ne bodo. Žal pa je res, da dandanes tega še niso sposobni. To je škoda, saj bi inteligenca, ki bi besedila tudi razumela, lahko prebrala vse medicinske revije, vse kartone in vse učbenike in bi bila najboljši pomočnik zdravnika na tem svetu.
Toda tega problema ne bomo rešili s še več informacijami, saj je umetna inteligenca že zdaj prebrala več besedil kot katerikoli človek. Potrebujemo kvalitativni preskok v razumevanju.
Ponekod pa to ni ovira. Za pisanje kratkih agencijskih vesti iz znanih informacij, denimo tečajnih list ali športnih tablic, je umetna inteligenca že danes nared in se tudi uporablja. Že za olimpijske igre v Riu de Janeiru leta 2016 je The Washington Post uporabljal programske robote za pisanje kratkih vesti z izidi. Ti se zdaj uporabljajo tudi pri poročanju o izidih volitev po okrožjih, pri pokrivanju drugih športnih dogodkov, za komentar poslovnih izkazov in borznih sprememb itd. Pričakovati je, da bodo preprosta poročanja, ki so že zdaj pogosto zgolj povzetki zapisov tiskovnih agencij, prevzeli algoritmi. Ljudem bodo ostale velike zgodbe preiskovalnega novinarstva, kjer bodo algoritmi služili za prebijanje skozi gore podatkov, a bo za sintezo in zapis zgodbe še vedno potrebna človeška roka.
Nassim Nicholas Taleb je v Črnem labodu zapisal, da se zgodovina in družba ne plazita, temveč skačeta od prelomnice do prelomnice. Morda se res zdi, da se vmes ne dogaja mnogo, a umetna inteligenca se plazi dovolj počasi, da se nam še vedno zdi nedosegljivo daleč. Toda popravljanje črkovanja med tipkanjem, Googlovo samodokončevanje iskalnih terminov, boti za pogovore, razumevanje naravnega jezika, pisanje vesti iz podatkov in zdaj GPT-2 so le nekateri od opomnikov s področja besedne umetnosti, ki kažejo, kam je umetna inteligenca že prilezla. Drugod, denimo v igranju šaha, goja in šogija pa smo ljudje že izgubili.
Primer
Vzeli smo odstavek iz pričujočega članka, ga strojno prevedli v angleščino, dopolnili z algoritmom GPT2 (Talk to Transformer) in strojno prevedli nazaj v slovenščino. Rezultat ni slab!
Izvirnik Strojni prevod v angleščino (Google Translate)
Sredi lanskega leta je bilo na Youtube vsako minuto naloženih za 500 ur novih vsebin, pravijo uradni podatki iz Googla. Niti teoretično ni mogoče, da bi kdo vse to pogledal, kar je sprožilo marsikateri monolog o kakovosti vsebin in smiselnosti tega početja. A to sploh ni nov argument.
In the middle of last year, 500 hours of new content were uploaded to YouTube every minute, official data from Google say. It is not theoretically possible for anyone to look at all of this, which has triggered many monologues about the quality of the content and the meaningfulness of it. But this is not a new argument at all.
Strojna dopolnitev besedila (Talk to Transformer) Strojni prevod dopolnitve v slovenščino
On some internet forums, videos of online debates quickly become repetitive and, paradoxically, idiotic. When it comes to entertainment, online debates can also get so overheated that they resemble a shouting match. And that's before you get to the point of simply disregarding everything in sight and deciding that the conversation has to be no longer took seriously. The internet is fertile ground for such hyperbole and most people react in the same way.
Na nekaterih internetnih forumih posnetki spletnih razprav hitro postanejo ponavljajoči in, paradoksalno, idiotični. Ko gre za zabavo, se lahko spletne razprave tudi tako pregrejejo, da spominjajo na kričeče tekme. In še preden pridete do tega, da preprosto ne upoštevate vsega na vidiku in se odločite, da pogovora ne smete več jemati resno. Internet je rodovitna podlaga za take hiperbole in večina ljudi reagira na enak način.