Računalniki se učijo
V zadnjih letih računalniki pospešeno osvajajo področja, ki smo jih imeli dolgo časa za neosvojljive trdnjave človeškega razuma. Šahiranje je že lanski sneg, danes računalniki vozijo avtomobile po mestih, prepoznavajo govor in prevajajo, igrajo kvize, zdravijo, analizirajo družabno omrežje in vaše nakupe. Dobrega pol stoletja smo potrebovali, da smo izdelali računalnike, ki se učijo in znajo stvari, ki jih njihovi tvorci ne obvladajo. Poglejmo, kako.
Možgane sestavlja 100 milijard nevronov.
Svet ima eno veliko pomanjkljivost, če nanj gledamo z očmi primitivnih računalnikov in drugih strojev. Nima enostavnih definicij in jasnih, odrezanih predalčkov, kamor bi lahko razvrstili različne sestavine. Edina izjema se zdijo strukture v matematiki, drugače pa imamo težave tako na najmanjših ravneh (poskusite enoznačno definirati kemijsko vez) kakor v makroskopskem svetu. Načeloma vsi vemo, kaj je ptica, a enoznačna definicija ptice je praktično nemogoča. Nihče na tem svetu se ni z definicijo naučil, kaj je ptica; videli smo dovolj letečih stvari, ki jim rečemo »ptica«. Videli smo tudi precej letečih stvari, ki niso »ptica«, in tako počasi zožili pojem na uporaben približek. In na koncu smo izvedeli še za noja, pingvina in podobne, ki so »ptica«, pa ne letijo. Sedaj pa poskusite to naučiti računalnik.
Dopusten je pomislek, da gre za pomanjkljivost človeškega jezika ali morda celo naših možganov. Res je, z veliko truda in dlakocepljenja je mogoče postaviti nekatere neovrgljive definicije. Toda tega ne počnemo, ker to v našem svetu ni v pomoč. Jezik in možgani so rezultat več milijard let trajajoče evolucije, ki je izdelala izvrstno prilagojen in optimiziran sistem. Za njegovo preživetje ni pomembno, ali je netopir ptica ali sesalec, dokler se mu znamo izogniti, ker vemo, da prenaša ebolo, SARS, steklino in še kaj.
Kako inteligenten je računalnik
Termin umetna inteligenca fascinira raziskovalce, filozofe, programerje in laike že vsaj od izuma računalnikov. V novembrski številki (Končni mejnik v računalništvu, Monitor 11/15) smo si ogledali, kako daleč so posamezni igralci na tem področju, zdaj pa se bomo poglobili v način, kako jim je to uspelo. Pri tem naj strokovnjake takoj opozorimo, da je bilo treba tematiko za poljudno predstavitev precej poenostaviti.
V zadnjem času večkrat slišimo, da je umetna inteligenca za vogalom in da bodo roboti po zgledu Matrice vsak čas zavzeli svet, a to z resnico nima dosti skupnega. Problematična je sama definicija inteligence.
Inženir bo inteligenco definiral glede na opravilo, ki ga pričakuje od stroja. Če ga stroj opravi brez težav in napak, je inteligenten. Pomivalni stroj se zdi precej primitiven kup železja in elektronike, ki pomiva tako, kot ne bi nihče pri zdravi pameti, a za svoj problem je inteligenten. Zna očistiti posodo.
Zdaj so v modi droni in ti so za svoj namen inteligentnejši od ljudi – na voljo imajo informacije (satelitska navigacija, internet, radar, lidar, kamere) in če jih z neba ne sklati kakšna kanja, bodo prispeli na cilj, pa četudi so prvič v nekem mestu in se pri tem izogibajo tisoč drugim oviram. Pri tem se ne sprašujemo, ali dron zavestno leti po zraku izpolnjujoč glavni ukaz ali pa pač sledi zapletenemu krmilnemu mehanizmu. Človek je po tej razvrstitvi sorazmerno inteligenten, ker mu bo ravno tako uspelo priti na cilj, bakterija pa ni.
V psihologiji oziroma kognitivni znanosti nasploh pa se ne ukvarjamo z nalogo, ki naj jo stroj opravi, temveč s poustvaritvijo zavesti in inteligence ter s čustvovanjem. Človek je tu najinteligentnejše bitje, šimpanzi so nekoliko manj, psi še manj, a tudi bakterije imajo košček inteligence, saj se odzivajo na dražljaje in hrano. Računalnik je tu neumen kot noč. Samo v premislek: ali je za inteligenco potreben samoohranitveni nagon? Če je odgovor da, lahko umetna inteligenca predstavlja tudi nevarnosti.
Znameniti test za preverjanje, ali stroj izkazuje inteligentno obnašanje, se imenuje Turingov test in gre takole: človek prek računalnika komunicira z dvema sogovornikoma, izmed katerih je eden človek, drugi pa stroj. Če mu ne uspe ugotoviti, kateri je kateri, je stroj opravil Turingov test. Vse odkar je Alan Turing leta 1950 predlagal ta test, ki so ga do danes že mnogokrat izvedli z različnimi programi, ostaja kontroverzen. Ne moremo reči, da dokazuje inteligenco, tega, mimogrede, niti Turing ni trdil. Test kaže le, da se tak stroj obnaša enako kot človek. Ali smemo inteligenco enačiti z inteligentnim obnašanjem, pa je filozofska dilema, o kateri so napisane knjige.
MOŽGANI
Kako zmogljivi so možgani
Raziskovalcem s Stanforda je že leta 2012 uspel osupljiv dosežek. Uspelo jim je simulirati bakterijo Mycoplasma genitalium, ki je s 525 geni eden najmanjših živih organizmov (slavna sestrica Escherichia coli jih ima skoraj desetkrat toliko). Za ta dosežek so potrebovali 128 računalnikov, ki so na primer preprosto delitev celice preračunavali 10 ur. Do simulacij možganov je še daleč.
Človeški možgani imajo 100 milijard nevronov, ti pa imajo okrog 10.000 povezav. Povezave se prožijo kvečjemu s frekvenco 100 Hz, to pa pomeni, da bi z 1017 primitivnimi operacijami na sekundo lahko simulirali možgane. To zgornjo mejo je znani futurist Nick Bostrom postavil v znamenitem članku (How long before superintelligence?) že leta 1997. Po Hansu Moravcu poimenovana spodnja meja je okrog 1014 operacij na sekundo. To bi po nekaterih predpostavkah že lahko zadoščalo za simulacijo možganov. Najhitrejši superračunalnik na svetu zmore 3,4 · 1016 operacij s plavajočo vejico na sekundo (34 petaflops). To pomeni, da z računsko močjo že trkamo na vrata človeške inteligence. Bistvena razlika pa je seveda v samem ustroju superračunalnikov, ki nimajo nevronske zgradbe.
Kaj je težko
Ob naivnem gledanju se zdi, da so računalnik le pomanjšani in v gigaherce naviti možgani, v resnici pa možgani in procesor delujejo bistveno drugače, zato (ali pa ker) so prilagojeni različnim nalogam. Poenostavljeno povedano, je procesor namenjen hitremu izvajanju zaporednih operacij, ki so v svojem bistvu seštevanje, logične operacije in premikanje bitov. Procesorji imajo že lep čas cevovod in v zadnjem času tudi več jeder, a osnovna zamisel ostaja nespremenjena: izvedejo zelo veliko zelo hitrih, preprostih in dobro definiranih operacij.
Možgani delujejo povsem drugače. Sestavljajo jih živčne celice ali nevroni, povezane v gosto mrežo sinaptičnih povezav. Nevroni signale sprejemajo po aksonih in oddajajo prek dendritov. Povprečni človeški možgani imajo 100 milijard nevronov, od katerih vsak v povprečju tvori 10.000 povezav. Biološke podrobnosti vzdraženja in prenosa signala nas tu ne zanimajo (čeprav so zelo zanimive), saj superinteligentnega računalnika ne bomo sestavljali iz celic, potopljenih v vodno raztopino, med katerimi prenašajo signale malo kemične spojine in malo elektrika. Pomemben pa je princip.
V nevron vodi več povezav, po katerih lahko vanj prispejo pozitivni ali negativni električni signali. Ti se na nevronu uteženo seštejejo in če vsota preseže vzdražni prag, nevron sporočilo pošlje naprej po svojih povezavah. Obdelava informacij poteka zaradi različnih povezav med nevroni in različnih vzdražnih pragov. Sorazmerno eleganten model nekoliko zaplete to, da v možganih redno nastajajo nove sinaptične povezave in prekinjajo stare, kar poznamo pod pojmoma učenje in pozabljanje.
Rezultat je zelo zanimiv. Možgani so prilagojeni iskanju vzorcev, prepoznavanju in približnemu računanju. Vsakokrat ko ujamemo podajo pri košarki, naši možgani v delcu sekunde rešijo zapleten sistem diferencialnih enačb, da koordinirajo usklajeno gibanje okončin, ki nas premaknejo v smer žoge in amortizirajo sunek sile, ob tem pa vse druge mišice poskrbijo, da obdržimo ravnotežje. Nesorazmerno velik del možganov je namenjen obdelavi vizualnih informacij, zato tudi v množici zlahka prepoznamo prijatelje. To zmore vsak otrok in to nam gre tako dobro, da se zdi trivialno in nič kaj inteligentno. A ne bodimo po nepotrebnem skromni – najpametnejši in najbolje financirani ljudje na svetu (pomislite na NSA) so se vrsto let ukvarjali z računalniškim prepoznavanjem obrazov, preden so prišli do pogojno uporabnih rezultatov. In to v času, ko je bilo računanje Eulerjeve konstante na milijardo decimalk trivialno početje za vsak domači računalnik.
Človeški možgani organizirajo ideje, koncepte in znanje hierarhično. Učijo se od enostavnih primerov proti težjim, osvojeno znanje pa uporabljajo pri nadaljnjem učenju. Sposobni so sklepati s konkretnega na splošno in abstraktnega mišljenja. Zgrajeni so izrazito vzporedno, njihovo zapleteno delovanje pa je v bistvu emergenca v pravem smislu besede – vznikne zaradi velikega števila preprostih samoorganiziranih enot.
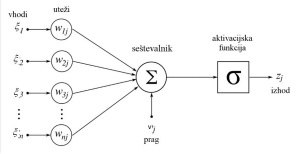
Shema umetnega nevrona, kot jih najdemo v nevronskih mrežah. Izhodov je lahko tudi več.
Obdobja v razvoju umetne inteligence
1947–1956: začetki umetne inteligence.
1957–1974: zlata doba raziskav umetne inteligence.
1974–1980: prva zima (odkrivanje temeljnih omejitev, zastoj napredka, osip financiranja).
1981–1987: hiter razvoj področja.
1988–1993: druga zima (neuspehi nevronskih mrež, osip financiranja).
1994–2006: obuditev zanimanja.
2007–: komercialna doba strojnega učenja (velika računska moč, velikanske zbirke podatkov za globoko učenje).
Računalnik sreča možgane
Iz napisanega postane razumljivo, zakaj samo z zviševanjem takta in vztrajanjem pri proceduralnih programih ne bomo prišli daleč. Verjetno bomo hitreje tam, kamor smo namenjeni, ne bomo pa presegli konceptualnih omejitev. Po svetu so problemi, ki so slabo definirani in jih ne moremo rešiti z vnaprej določenim algoritmom. Pravzaprav so vsi pomembni problemi taki. Ugotoviti moramo, kako računalnik naučiti učiti se.
Zgled smo našli kar v naravnih možganih. Problema so se lotili z umetnimi nevronskimi mrežami (ANN), ki so že kar stara iznajdba, saj segajo v 40. leta minulega stoletja. Prvo nevronsko mrežo sta že leta 1943 razvila Warren McCulloch in Walter Pitts.
Nevronska mreža kot vhodni podatek sprejme velika polja števil, torej več spremenljivk, nad njimi pa izvede serijo matematičnih funkcij in vrne eno ali več števil. Vhodni podatek je lahko, recimo, slika, kjer vsako število podaja barvo posameznega piksla, rezultat pa je ugotovitev, ali slika predstavlja mačko. Tako preprosto naj bi to bilo.
Da bi se izognili napakam pri tolmačenju, kar takoj povejmo, da se umetne nevronske mreže še vedno fizično izvajajo na klasičnih računalnikih s serijskimi procesorji. Le sprogramirani so tako, da simulirajo vzporedno delovanje pravih nevronskih mrež v možganih. Gradnja dejanske mreže milijard nevronov bi bila predraga in prezapletena. Obnašajo se torej enako, razlikujejo pa se podobno, kot se na primer reševanje Navier-Stokesovih enačb razlikuje od bazena. So skupek matematičnih funkcij.
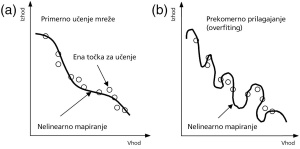
Pri učenju nevronskih mrež moramo biti pazljivi, da jih ne natreniramo preveč. Če vaje ponavljamo s preveč podobnimi podatki, se mreža pretirano prilagodi (overfiting), zato na svežih podatkih deluje slabše.
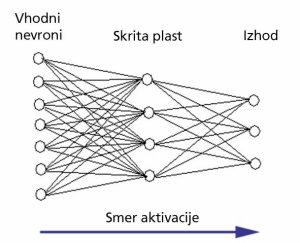
Preprosto nevronsko mrežo predstavljajo umetni nevroni, razvrščeni v sloje. Signali potujejo vzdolž slojev, nevroni na istem nivoju pa niso povezani. Možne so tudi druge sestave.
V ozadju je matematika
Matematični model nevrona je videti takole. Imamo različno utežene vhode (ξi), katerih signale (ωi) nevron sešteje. Če presežejo določen prag (θ), nevron odda signal glede na aktivacijsko (tudi prenosno) funkcijo in nek(i) drug(i) nevron(i) ga spet sprejme(jo). Nevroni so razvrščeni v sloje oziroma plasti – nevroni v isti plasti med seboj niso povezani, se pa povezujejo z nevroni naslednjih slojev (nekatere vrste nevronskih mrež imajo tudi drugačno hierarhijo). Aktivacijske funkcije so lahko linearne, binarne, bipolarne, sigmoidalne, hiperbolične ipd. Procesiranje je končano, ko se potovanje dražljajev ustavi; tedanje stabilno stanje na izhodu je rezultat.
Kaj bo nevronska mreža počela, pa je odvisno od tega, česa se je naučila. Pred uporabo je treba vsako nevronsko mrežo učiti, za to pa uporabimo velike množice vhodnih podatkov, za katere predložimo tudi želeni izhod. Mreža z učenjem išče optimalne vrednosti uteži za vhode in pragove posameznih nevronov, da bo iz vhodnih podatkov dobila pravilen rezultat. To imenujemo nadzorovano učenje.
Poznamo tudi nenadzorovano učenje, pri katerem mora nevronska mreža sama poiskati ustrezen izhod. To se sliši nenavadno, a je pogosto zelo uporabno. Tako lahko nevronska mreža poišče boljšo predstavitev vhodnih podatkov, s čimer išče vzorce. Zgled je na primer mreža, ki se nauči razvrščati dokumente ali fotografije glede na sorodnost vsebine. Bitna predstavitev fotografij mačk je lahko zelo različna, nevronska mreža pa lahko poišče funkcijo in ji priredi podobno vrednost, to pa omogoča avtomatizirano razvrščanje, iskanje in obdelavo. Glavni problem vseh nevronskih mrež je nezmožnost analize mehanizma, ki bi razložil dobljene rešitve. Četudi poznamo vse uteži, pragove in povezave, so nevronske mreže »črna škatla«, ki deluje. Glavna prednost je toleranca za šum, slabe in nepopolne podatke.
Obdelava v nevronskih mrežah poteka drugače kot pri klasičnih von Neumannovih računalnikih, kjer je algoritem natančno definiran in daje za isti vhod vedno enak rezultat. Pri nevronskih mrežah je rezultat odvisen od predhodnih izkušenj in je lahko vsakokrat drugačen. Pomembno je tudi, da jih učimo na podobnih problemih, kot jih bodo reševale kasneje, a ne čisto enakih. Ker so realni podatki vedno obremenjeni z določeno naključno napako, moramo šum v manjši meri vnašati tudi pri učenju.
Enega prvih algoritmov je konec 50. let izumil Frank Rosenblatt in se imenuje perceptron. Namenjen je nadzorovanemu učenju binarnega razvrščanja – takšna nevronska mreža lahko za vhodni niz podatkov določi, v katero izmed dveh množic sodi. Večslojni perceptron sestavljajo trije sloji. Na prvem najdemo nevrone, v katere pripeljemo vhodne podatke (vhodni sloj). Vsak izmed teh nevronov je povezan z vsemi nevroni na drugem sloju, ki ga imenujemo skriti sloj. Končni rezultat dobimo na tretjem (izhodnem) sloju, kamor signale pošljejo nevroni drugega sloja.
Razvoj umetnih nevronskih mrež je v 70. letih nekoliko zastal, ko sta leta 1969 Marvin Minsky in Seymour Papert v znamenitem članku pokazala, da nekatere primitivne nevronske mreže (npr. enonivojski perceptron) niso sposobne izvesti niti preproste funkcije XOR. Čeprav so kmalu odkrili večplastne nevronske mreže, ki to zmorejo, se je razvoj znova pospešil šele sredi 80. let, ko smo dobili nelinearne nevronske funkcije in vzvratno učenje.
Nekatere nevronske mreže podatke posredujejo le naprej po nivojih (feed-forward), zato ne morejo simulirati časovnih razmerij, druge pa vsebujejo povratne zanke (feed-back) in to zmorejo. Pozoren bralec bo vprašal, kako neki se nevronska mreža dejansko uči. Na začetku imajo nevroni majhne naključne vrednosti za uteži in pragove, potem pa jih je treba pametno piliti. Ena bolj priljubljenih metod za nadzorovano učenje se imenuje vzvratno razširjanje (backpropagation). Izračunani izhod na mreži se primerja z želeno vrednostjo, to pa se uporabi za določitev novih uteži zadnjega sloja, ki jih izračunamo iz odvodov. Napaka se potem prenese en sloj bolj nazaj in to omogoči prilagoditev uteži prejšnjega sloja itn.
Zadnje vprašanje, ki ga bo postavil zvedav bralec, je, kako izberemo število nevronov in slojev. Odgovor je preprost – po občutku. Nekoliko resneje povejmo, da je število nevronov v prvem sloju seveda enako številu vhodnih parametrov, število nevronov v zadnjem sloju pa želenim izhodnim podatkom. Kaj damo vmes, je odvisno od konkretnih primerov, in tu ni enoznačnega odgovora. Treba je poskusiti najti optimalno število slojev in nevronov v posameznem sloju. Kot vedno, pretiravanje ne izboljšuje več sposobnosti mreže, a znatno podaljšuje čas učenja.

IBMov računalnik Watson je leta 2011 zmagal na kvizu Jeopardy, kjer se je pomeril s preteklima zmagovalcema. Vsi so prejemali vprašanja v naravni angleščini. Danes počne Watson še marsikaj drugega, med drugim analizira medicinske raziskave in priporoča vrsto zdravljenja.
GO
Poslednja človeška trdnjava

Go ostaja ena zadnjih iger, ki jih računalniki še ne obvladajo bolje od ljudi.
V šahu, dami, scrabblu, pokru, backgammonu, othellu in podobnih igrah računalniki pometejo z ljudmi. Tradicionalna japonska igra go pa ostaja velika uganka. Lani je računalnik premagal velemojstra Norimota Yodo, a je za to potreboval začetno prednost štirih kamnov.
Razlika je v načinu, kako se go igra. V povprečnem položaju pri šahu ima vsak igralec na voljo 35 potez. Pri goju je ta številka okrog 250. Število možnih iger se prehitro veča, da bi računalnik lahko analiziral celo najverjetnejše razplete. Algoritmi tu odpovedo.
Rešitev so nevronske mreže in globoko učenje. Ker niti ljudje ne igrajo s preigravanjem vseh možnih variacij, nima smisla v to siliti računalnikov, pa čeprav je tako šlo pri šahu. Pomembnejši je občutek, kako je videti plošča za go. Velemojstri pogosto pravijo, da igrajo intuitivno.
Facebook in Google sta razkrila, da intenzivno razvijata umetne nevronske mreže, ki jim kažeta različne položaje pri goju in poteze, ki bi jih odigrali ljudje. Tako želita mrežo naučiti prepoznavanja in odzivanja na različne postavitve.
Obvladati go je resda prestižen rezultat, a cilj je napredek umetne inteligence. Prepoznavanje vzorcev je ključno zanjo, in kdor bo znal igrati go, bo blestel tudi pri prepoznavanju oseb in govora. Za zdaj se zdi, da bo zmagovalna strategija kombinirana uporaba globokega učenja in algoritemskega preiskovanja obetavnih variant. Google za prihodnje mesece obljublja velik napredek, a ne pove česa. Bomo videli.
Globoko učenje
Po doslej zapisanem bi sodili, da so nevronske mreže tisto pravo, iz česar bomo sčasoma dobili resnično simulacijo možganov. Žal so rezultati kazali, da čudežev ni pričakovati, in raba nevronskih mrež je počasi zamirala. Nevronske mreže so bile v glavnem uporabne za akademsko igračkanje, kar bomo slišali iz ust redkih strokovnjakov, pa še ti bodo to zamrmrali skozi stisnjene zobe.
Eden izmed glavnih problemov je bila neuporabnost dodajanja skritih slojev. Pričakovali bi, da več skritih slojev izboljša sposobnosti mreže, a se to ni zgodilo. Učenje take mreže je postajalo čedalje težje in z več kot tremi skritimi plastmi nismo pridobili ničesar. Še tako zapletena in zmogljiva mreža je neuporabna, če je ne znamo učinkovito učiti. Tako obetavni tehnologiji je zato grozilo, da bo ostala le dobra zamisel brez realnega potenciala.
Kot začetek pravega globokega učenja (deep learning) se omenja leto 2006, ko so Yann LeCun, Yoshua Bengio in Geoffrey Hinton (LBH) objavili znamenit članek, v katerem so pokazali nov algoritem učenja večslojnih nevronskih mrež. Kot je v znanosti navada, se na področju lomijo kopja. LBH se predstavlja kot vrhovna avtoriteta in pionir na področju globokega učenja, kar je do neke mere res, ni pa vsa resnica. Podobno zamisel so ljudje imeli in objavljali že pred tem, prav tako pa tudi zdaj potekajo zanimive raziskave tudi v drugih laboratorijih. Neizpodbitno pa drži, da se je po letu 2006 zanimanje za globoko učenje močno povečalo. Nezanemarljiv dejavnik je gotovo tudi spoznanje velikanov, kot so Google, Facebook, Microsoft, Yahoo in drugi, da je tu prihodnost. Prav tako drži tudi, da današnje globoko učenje nima več dosti skupnega z nevronskimi mrežami iz 90. let.
Zelo poenostavljeno povedano, so LBH pokazali, da lahko nižje sloje nevronskih mrež učimo požrešno (greedy). Požrešne metode so znan način reševanja problemov, ko iščemo krajevno najustreznejše rešitve in jih potem zlepimo. Pri nevronskih mrežah to pomeni učenje nižjih plasti brez upoštevanja višjih nivojev. To najlepše ponazorimo pri mrežah, ki so namenjene analizi fotografij. Nižji sloji zaznavajo osnovne značilnosti, npr. robove, linije, sivine, in jih ne zanima, kaj predstavljajo. Višji sloji prejmejo te informacije in zaznavajo čedalje abstraktnejše lastnosti.

Glavni izziv pri nevronskih mrežah je ugotoviti, kaj počne posamezni nivo nevronov v naučeni mreži. Google je med drugim pokazal, kako lahko v sliki ojači značilnosti, ki jih zaznava posamezen nivo nevronov. Če rezultate znova vodi v nevronsko mrežo, po nekaj iteracijah nastanejo zanimive podobe, ki so jih poimenovali računalniške sanje
Uporaba globokega učenja
• Prepoznavanje slik (prepoznava obrazov, iskanje po fotografijah, razvrščanje …)
• Prepoznavanje zvoka (tolmačenje, Siri, Cortana …)
• Zaznavanje vzorcev (OCR, prepoznavanje rokopisov …)
Strojno učenje
Najširši pojem, s katerim se ukvarjajo snovalci umetne inteligence, je strojno učenje. Globoko učenje oziroma različne nevronske mreže so le en način, so pa še drugi (glej tabelo). Cilj je izdelati algoritme, ki so sposobni prilagoditve na nove vhodne podatke in nenehno izboljševanje, in se učijo struktur, konceptov in parametrov. V teoriji bi moral vsak tak algoritem v življenjski dobi postajati čedalje pametnejši, saj dobiva čedalje več podatkov oziroma izkušenj.
Odkrito je treba tudi povedati, da je povečanje zanimanja korporacij in posameznikov prinesel na to področje tudi nekaj zmede in netočne terminologije. Danes je modno vse bolj ali manj sorodne načine strojnega učenja označevati kot globoko učenje, pa četudi ne sodijo strogo v to kategorijo. A tu nas zanimajo rezultati, teh pa ne manjka.
Podjetja pobirajo intelektualno smetano
To, da je neko področje vroče, hitro vidimo tudi po zaposlovanju v velikanih. Google je že decembra 2012 zaposlil znanega futurista Raya Kurzweila, četrt leta pozneje pa še Geoffreyja Hintona, če omenimo le največja imena, ki so del projekta Google Brain. Hkrati so kupili še podjetji DNNResearch in DeepMind Technologies.
Facebook je zaposlil Hintonovega študenta in profesorja na newyorški univerzi Yanna LeCuna in ustanovil nov raziskovalni laboratorij za umetno inteligenco, ki ga vodi LeCun. Kitajski Baidu je zaposlil Andrewa Nga, ki ga je pravzaprav izmaknil Googlu in ki prav tako sodi med največje strokovnjake na tem področju.
Ko se začnejo najpametnejši umi kopičiti v podjetjih, je to znak, da je tehnologija že tik pred komercializacijo.
Kaj si lahko obetamo
Umetne inteligence, podobne človeški, bržkone še ne bomo dobili tako kmalu, smo pa na obetavni poti. IBMov računalnik Deep Blue je že leta 1997 premagal aktualnega šahovskega prvaka Garija Kasparova, pa ni šlo ne za globoko učenje ne za naivno preizkušanje vseh mogočih potez (ker jih je preveč). Deep Blue je imel sprogramirana pravila in strategije, hkrati pa je preiskoval 200 milijonov potez na sekundo. Današnji superračunalniki se lahko igranja šaha naučijo z globokim učenjem v nekaj dneh. Sami.
Glavno področje raziskav globokega učenja je razvrščanje in analiza podatkov, kar je za ljudi enostavno, računalnikom pa bo omogočilo enakopravnejšo vključevanje v svet ljudi. Primer je promet. Samovozeči avtomobili se šele zdaj iz laboratorijev prebijajo na ceste, a ne zato, ker ne bi znali narediti avtomobila, ki se pelje sam. Letala znajo leteti sama že desetletja. Niti ni težko opremiti avtomobila s kamerami, mikrofoni in satelitsko navigacijo. Problem pa je spisati logiko, ki bo ločila človeka na pločniku od fotografije na reklami, razumela rdečo luč, se izogibala drugim vozilom in prepoznavala nove in obrabljene, vidne in zaraščene prometne znake različnih oblik in velikosti. Algoritma, ki bo vse to znal, ne moremo napisati sami. Ne znamo. Tudi v avtošoli nas niso naučili vseh možnih situacij, temveč koncepte in splošna pravila, za preostanek pa so poskrbeli s predznanjem opremljeni možgani.
Pomembno področje je tudi prepoznavanje zvoka. Kdor se je kdaj učil tujega jezika, dobro ve, da je razumevanje naravnega človeškega govora zapleteno opravilo, ki se ga moramo naučiti. Računalniki se z globokim učenjem lahko sami naučijo, kako prepoznavati govor. Nevroni na nižjih nivojih prepoznavajo posamezne glasove, naslednji nivo jih sestavlja v zloge, potem se ti zlagajo v besedo in tako hierarhično navzgor do koherentnih stavkov.
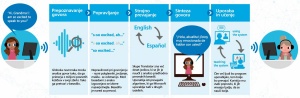
To je težji del pri tolmačenju, prevajanje je že zadovoljivo (resda še vedno daleč od popolnega!) rešeno, sintetizatorji glasov pa so najlažji del v verigi, ki jo ima Microsoft v novem Skypu. Ta že nekaj mesecev razume govorjeno angleščino in španščino ter simultano prevaja med jezikoma, pred kratkim pa se je naučil tudi kitajsko, francosko, nemško in italijansko.
Dostikrat slišimo, da so nekateri jeziki težji od drugih. Več dokazov imamo, da to ne drži. Povsem možno je, da je formalno slovnico kakšnega jezika teže sprogramirati, a to je manjši del jezika. To, da so vsi jeziki enako težki, dokazujejo otroci, ki se povsod po svetu naučijo govoriti pri približno isti starosti. To ima pomembne implikacije za strojno učenje; če bomo ustvarili digitalne možgane, bodo ti načeloma znali prevajati med katerimikoli jeziki, ki se jih bodo naučili. Evropski jeziki imajo dovolj bogat korpus, v zakonodaji EU pa še odlično zbirko istih besedil v različnih jezikih, zato se za slovenščino ni bati.
Strojno učenje najdemo na vsakem koraku, pa čeprav se tega sploh ne zavedamo. Prepoznavanje besedila (OCR), obdelava velikih količin podatkov (recimo v CERNu), prikaz relevantnih objav na Facebooku, iskanje po slikah na Googlu, podatkovno rudarjenje in interpretacija večpomenskih kitajskih pismenk vsi tako ali drugače uporabljajo strojno učenje.
Se moramo bati sveta, v katerem igrajo pomembno vlogo s strojnim učenjem nastali algoritmi? So taki sistemi inteligentni v kognitivnem ali zgolj inženirskem smislu? Na ta vprašanja morate odgovore poiskati sami.
Skype Translator združuje več prvin strojnega učenja v simultanega prevajalca govora.
IGRE
Rešene in nerešene igre
Z računalnikom nima smisla igrati križcev krožcev ali štirih v vrsto, ker sta ti igri močno rešeni (strongly solved). To pomeni, da lahko za vsak položaj izračunamo optimalno potezo. Take igre ne moremo izgubiti, če od začetka igramo optimalno.
Računalnik Chinook je leta 1992 v dami izgubil proti svetovnemu prvaku Marionu Tinsleyju, leta 1994 pa je zaradi Tinsleyjeve predaje iz zdravstvenih razlogov postal svetovni prvak. Leta 1995 je naslov ubranil. Dama je danes šibko rešena (weakly solved) igra. Raziskovalci so leta 2007 po 18 letih računanja na 50 – 200 računalnikih pokazali, da se igra vedno konča neodločeno, če igralca igrata optimalno.
Mednarodni šahovski mojster David Levy je leta 1968 stavil, da ga v naslednjih desetih letih ne bo premagal noben računalniški program. Deset let pozneje je v žep pospravil 1250 funtov. Toda leta 1997 je IBMov Deep Blue premagal tedanjega svetovnega prvaka Garija Kasparova. Danes komercialni šahovski programi na osebnih računalnikih premagujejo velemojstre, čeprav je igra nerešena (optimalne poteze ne poznamo).






