Podvojevanje podatkov na 101 način
Za splošen uvod v podvajanje podatkov med bazami podatkov (replikacijo) bi najverjetneje moral razložiti na dolgo in široko, zakaj je potrebna in zakaj je prišlo do njene izvedbe v zbirkah podatkov. Predvidevam pa, da ste tisti, ki ste se odločili prebrati ta članek, že imeli kdaj potrebo po rezervni kopiji zbirke, katere vsebina je enaka izvirni zbirki v bolj ali manj realnem času ali pa je zaradi prevelikega števila zahtev zbirka na eni lokaciji postala ozko grlo.
Med ponudniki zbirk podatkov z izključno komercialnimi licencami je tako delovanje nepogrešljivo. V nasprotnem primeru bi bilo zbirke podatkov preveč tvegano vključevati v resna produkcijska okolja, kot so veliki informacijski sistemi. Prednosti uporabe zbirke za hranjenje podatkov ne odtehtajo hitre izgube ali prekinjen dostop do le-teh.
MySQL je dobil podporo podvojevanju podatkov nekje v različicah po 3.2.x. Z različico 4.0 je prišlo do spremembe načina podvojevanje podatkov, ki se pozna predvsem v zanesljivejšem delovanju. V osnovi MySQL podpira podvojevanje iz enega nadrejenega v en podrejeni strežnik (master-slave), to pa dela podvojevanje enosmerno. To se dogaja ob pomoči dvojiških dnevniških datotek (binary logs), ki se zapisujejo na strani nadrejenega strežnika MySQL. V datoteko se v zgoščeni obliki pod zaporednimi številkami zapisujejo poizvedbe, ki dejansko spreminjajo vsebino tabel, shranjenih v zbirki. Dnevniško datoteko odčitava podrejena zbirka podatkov, ki se kot neprivilegiran odjemalec prijavi v nadrejeni strežnik. Tako prva nit podrejene zbirke podatkov prenaša zapise v krajevni datotečni sistem, druga nit pa te poizvedbe izvaja. Osveževanje je nesinhrono, zato lahko prihaja do razlik v posodobljenosti podatkov v podrejenem strežniku. Odjemalci na podrejenem strežniku lahko izvajajo samo poizvedbe za čitanje.
Seveda je to vse skupaj osnovna teorija o delovanju podvojevanja podatkov v strežnikih MySQL tja od različice 4.0 naprej. Z različicami, novejšimi od 4.1, je mogoče narediti celo sinhrone distribuirane zbirke, a je za to treba uporabiti t. i. MySQL Cluster. To v bistvu ni nič drugega kot uporaba druge vrste tabel, ki "živijo" v netrajnem pomnilniku (to, kar nas večina pozna kot RAM) na več članih gruče. Tega dela članek ne obravnava. Ostajamo pri osnovnem načinu podvajanja podatkov, pri katerem je mogoče uporabiti skoraj vse vrste tabel oz. načinov shranjevanja le-teh - od MyISAM, InnoDB do bdb.
Na prvi pogled se morda zazdi, da je tako konservativen dostop do problematike podvojevanja podatkov skoraj nekoristen za resno uporabo. Z nekoliko spretnosti pa je mogoče narediti marsikaj, kar morda ni razvidno na prvi pogled.
Kje začeti?
Najbolje, da kar na začetku - pri sestavi osnovnega načina podvojevanja. V strežniku "gospodar" imamo zbirke, ki bi jih želeli podvojevati v strežniku "suženj". Postopek je opisan za podvojevanje samo določenih zbirk in vseh zbirk iz nadrejenega v podrejeni strežnik.
Ker strežnik "suženj" nima trenutnih vsebin iz strežnika gospodar, bomo morali te vsebine najprej nekako spraviti v podrejeni strežnik. Tu se moramo vprašati, ali si lahko dovolimo izpad strežnika ali bomo to naredili kar v času njegovega delovanja. Možno je oboje, vendar bomo morali, če ne želimo prekiniti delovanja nadrejenega strežnika, parametre za replikacijo dodati v kratkem restartu strežnika (parameter --log-bin ali parametre v konfiguracijski datoteki, ki so opisani spodaj), drugače pa bomo parametre nastavili sveže zagnanemu izvodu strežnika. Natančneje bo opisana druga različica, ki je tudi nekoliko elegantnejša.
Prvi korak bo torej ročni prenos podatkov v podrejeni strežnik. Med delovanjem strežnika bo to najlaže storiti tako, da zapišemo vse podatke iz pomnilnika v trajni pomnilnik, kjer so tabele shranjene, in zaklenemo vse tabele z ukazom v odjemalcu, prijavljenem na nadrejeni strežnik:
mysql> FLUSH TABLES WITH READ LOCK;
Zdaj pa urno prekopiramo izbrane tabele v drug strežnik po poljubni metodi. Po končanem kopiranju tabele hitro odklenemo, da se lahko operacije odjemalcev nadaljujejo:
mysql> UNLOCK TABLES;
Pri tej operaciji je zelo dobro vedeti, kaj delamo. Pri nepravilni sestavi strežnika ali odjemalcev lahko precej hitro zabredemo v težave. Če imajo odjemalci nastavljen premajhen čas za odgovor ali je v strežniku nastavljeno premajhno število dovoljenih povezav, se bo več poizvedb klavrno končalo in prineslo napako v programju, ki aktivno uporablja strežnik. Veliko bolj elegantno je kopiranje izvesti tako, da strežnik MySQL izklopimo, prekopiramo zbirke v podrejeni strežnik, ga prekonfiguriramo in potem zaženemo nazaj. Še to - če uporabljamo tabele Innodb na surovi particiji diska, bomo vsebine zbirke morali izvoziti s programom mysqldump.
Vzpostavitev podvojitve podatkov
V prejšnjem koraku smo poskrbeli za kopijo podatkov v podrejenem strežniku. Zanj moramo pripraviti pravo nastavitev za prenašanje sprememb iz nadrejenega strežnika. Če smo kopirali podatke pri delujoči zbirki (ki bi morala biti že nastavljena s katero od spodaj opisanih opcij), katere podatki se nenehno spreminjajo, moramo ukazu za odklep tabel še dodati ukaz, ki bo strežniku povedal, naj spremeni serijsko številko dvojiške dnevniške datoteke z ukazom:
mysql> RESET MASTER;
Če pa smo nadrejeni strežnik pred kopiranjem podatkov zaustavili, lahko mirno začnemo s konfiguracijo nadrejenega. V konfiguracijski datoteki my.cnf (v sistemih *nix je navadno v mapi /etc) bomo dodali naslednje vrstice:
...
# Zaporedna številka strežnika
server-id=1
# Zapisuj dnevniško datoteko
log-bin
# Zapisuj dnevniško datoteko samo za naslednje baze
# (opcijsko, če ne želimo podvojevati vsega)
binlog-do-db=monitor
binlog-do-db=revije
...
Zdaj lahko zaženemo nadrejeni strežnik. Prijavimo se nanj z odjemalcem s superuporabnikom oziroma računom za upravitelja zbirke podatkov ter ustvarimo uporabnika "podvajanje" z geslom "podatkov" z ustreznimi pravicami. Enostavno je to mogoče narediti s poizvedbo GRANT:
mysql> GRANT REPLICATION SLAVE ON *.* TO 'podvajanje'@'%' IDENTIFIED BY 'podatkov';
Če ste uporabnika ustvarili že pred tem, je potreben samo popravek v tabeli user v bazi mysql, kjer dopustite privilegije "Select Priv" in "File Priv". Drugi privilegiji niso potrebni.
mysql> USE mysql;
Database changed
mysql> UPDATE user SET Select_priv='Y',File_priv='Y' WHERE user='podvajanje';
Query OK, 0 rows affected (0.04 sec)
Rows matched: 1 Changed: 0 Warnings: 0
mysql>
In spremembe pravic oznanite s:
mysql> FLUSH PRIVILEGES;
Zdaj nam manjka še nastavitev podrejenega strežnika. Kopijo podatkov ima pri sebi, prav tako ima pripravljenega uporabnika v nadrejenem strežniku.
V strežniku "suženj" dodamo naslednje vrstice v konfiguracijsko datoteko:
...
# Zaporedna številka strežnika
# - mora se razlikovati od nadrejenega
server-id=2
# Podatki o nadrejenem strežniku
master-host=gospodar.monitor.si
master-port=3306
master-user=podvajanje
master-password=podatkov
...
Zdaj smo pripravljeni na zagon podrejenega strežnika. Če je vse tako, kot mora biti, bomo v dnevniški datoteki (klasična dnevniška datoteka, ne tista za podvojevanje) v podrejenem strežniku našli zapis o tem, da je replikacija stekla.
051129 22:32:47 [Note] Slave SQL thread initialized, starting replication in log 'FIRST' at position 0, relay log './suzenj-relay-bin.000001' position: 4
051129 22:32:47 [Note] Slave I/O thread: connected to master 'podvajanje@gospodar.monitor.si:3306', replication started in log 'FIRST' at position 4
Več informacij o tem dobimo tudi tako, da v podrejenem strežniku zaženemo ukaz prek odjemalca:
mysql> SHOW SLAVE STATUS;
Osnovni del je za nami in podvajanje podatkov je vzpostavljeno. Naredimo lahko enostaven preizkus delovanja, tako da spremenimo podatke v kakšni tabeli v nadrejenem strežniku in zadevo preverimo na podrejenem.
Ali je to vse?
Kot smo ugotovili že v prvem delu, nam tako podvajanje ne prinaša posebnega navdušenja. V naslednjem delu si bomo ogledali nekaj bolj zapletenih postavitev, ki jih je mogoče narediti po istem kopitu.
En nadrejen, dva vzporedna podrejena strežnika
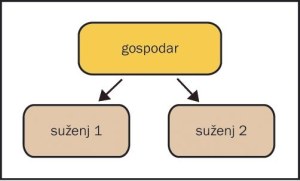
V tem primeru želimo podatke podvajati na dve lokaciji iz istega vira (skica 1). Zadeva je enaka kot prej, le da bomo morali skonfigurirati še en podrejeni strežnik, ki se lahko prek istega uporabnika za podvajanje prijavi na nadrejeni strežnik. Nikoli ne pozabimo spremeniti zaporedne številke strežnika (server-id). Tako podvajanje zna dodatno obremeniti nadrejeni strežnik, zato je smiselno zadevo spremeniti.
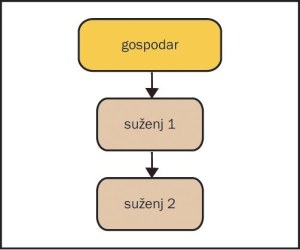
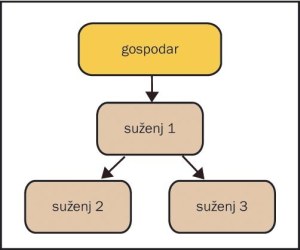
En nadrejen, dva zaporedna podrejena strežnika
V takem primeru se bo zadnji podrejeni strežnik, "suženj2", priklopil na vmesni strežnik "suženj1" (skica 2). S tem bo nadrejeni nekoliko razbremenjen, vsebina se bo pa prav tako prenašala v strežnik "suženj2". V takem primeru bomo morali v strežniku "suženj1" še dodati nekaj vrstic v konfiguracijsko datoteko, ki bodo povzročile zapisovanje sprememb iz nadrejenega strežnika v dvojiško dnevniško datoteko na datotečni sistem strežnika "suženj1".
...
# Zapisuj dnevniško datoteko
log-bin
# Zapisuj spremembe na podrejenem strežniku
log-slave-updates
...
Zadeva je še bolj uporabna, če potrebujemo veliko strežnikov za odčitavanje iz tabel. Tako se lahko tudi morebitni strežnik "suzenj3" poveže na prvega podrejenega (skica 3).
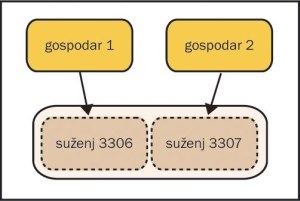
Dva ali več nadrejenih, en podrejen
Če želimo zapisovati vsebine zbirk podatkov iz več strežnikov na eno lokacijo, ki je morda rezervirana za hrambo podatkov, bomo morali uporabiti zvijačo. Ker ima lahko že po teoriji en podrejen samo en nadrejen strežnik, moramo na izbrani lokaciji zagnati več strežniških procesov zbirke podatkov MySQL, in to vsako na svojih vratih tcp in z različnimi nastavitvami glede na vsebujoči nadrejeni strežnik. Pripravimo dve ali več konfiguracijskih datotek in jih podamo v več zagonskih skriptah. Zadeva je popolnoma izvedljiva, vendar moramo kljub temu računati, da bo strojna oprema, kjer bodo zagnani podrejeni strežniki, pač toliko obremenjena kot strojna oprema vseh nadrejenih podatkovnih strežnikov skupaj. Morda se bomo morali sprijazniti s tem, da podvajanje ne bo ažurno (to preverimo z že prej omenjenim ukazom SHOW SLAVE STATUS; na vsaki podrejeni instanci) ali pa se bo neažurnost vseskozi povečevala. Ko bodo podvojitve zamujale po nekaj tednov, boste zamisel verjetno opustili. (skica 4)
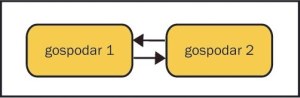
Dva nadrejena
Ne, to ni šala - tudi to gre narediti precej enostavno s prejšnjo funkcionalnostjo. Zadeva žal ne funkcionira, kadar želimo v oba strežnika isti trenutek zapisati vnos, ki uporablja glavni ključ s samodejno naraščajočo vrednostjo. V vseh drugih primerih je možna uporaba. Oba strežnika delujeta kot podrejeni in nadrejeni strežnik hkrati. V obeh strežnikih ustvarimo uporabnika za podvajanje. Na strani strežnika "gospodar1" dodamo v konfiguracijo te vrstice:
...
# Zaporedna številka strežnika
server-id=1
# Zapisuj dnevniško datoteko
log-bin
# Podatki o nadrejenem strežniku
master-host=gospodar2.monitor.si
master-port=3306
master-user=podvajanje
master-password=podatkov
...
in na strežniku "gospodar2" :
...
# Zaporedna številka strežnika
server-id=2
# Zapisuj dnevniško datoteko
log-bin
# Podatki o nadrejenem strežniku
master-host=gospodar1.monitor.si
master-port=3306
master-user=podvajanje
master-password=podatkov
...
Taka postavitev je primerna predvsem za tako imenovano "fail-over" gručo, kjer je pogoj, da je aplikacija, ki rabi kot odjemalec, napisana tako, da ima dostop do dveh različnih strežnikov in v primeru izpada izbere tistega, ki je dosegljiv. To možnost navadno omogočajo že razni vmesniki do zbirke podatkov znotraj razvojnih orodij in programskih jezikov. Pri izpadu enega strežnika iz gruče se operacije tako nemoteno nadaljujejo. Ko se izpadli strežnik vrne, samodejno doda manjkajoče vrednosti, ki so se v vmesnem času zapisale v delujočem strežniku.
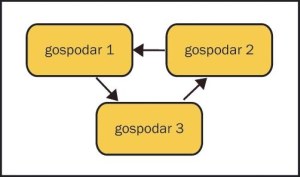
Krožno podvojevanje podatkov
Gre za nekoliko bolj eksotičen primer zgoraj navedenega podvojevanja. Tudi tu imajo vsi vlogo nadrejenega in podrejenega strežnika. Strežnik "gospodar1" spremeni vsebino, ta se zapiše v dnevniško datoteko, spremembo pri sebi zazna "gospodar2" in jo vpiše v svojo dnevniško datoteko. Isto stori "gospodar3", vendar "gospodar1" te spremembe več ne bo upošteval pri sebi, saj je zaporedna številka (server-id) enaka njegovi. Zgodba se ponovi, če pride do spremembe na katerem od drugih dveh strežnikov. Primer je tu ponazorjen s tremi strežniki, vendar jih je mogoče dodati več. Za konfiguracijo lahko porabimo zgornjo datoteko, s tem da dodamo še parameter:
...
# Zapisuj spremembe na podrejenem strežniku
log-slave-updates
...
Mogoča pa je velika neažurnost, če izpade "gospodar2". Poizvedbe, ki jih bodo odjemalci pošiljali na "gospodar3", se bodo izvedle tudi v strežniku "gospodar1", vendar spremembe, zapisane na "gospodar1", ne bodo prišle v veljavo na "gospodar3", dokler se strežnik "gospodar2" ne vrne v gručo.
Za konec naj še opozorim, da se pri vseh vrstah podvojevanja podatkov v zbirki podatkov MySQL velja izogibati uporabi funkcij za generiranje naključnih vrednosti, saj se poizvedbe izvajajo v vsakem strežniku posebej. Tako bodo v vsaki tabeli zapisane drugačne vrednosti.
Napake med podvajanjem
Kot pri vsakem bolj ali manj dobrem programju, se tudi pri uporabi zbirke podatkov MySQL dogajajo napake v delovanju, ki niso nujno povezane z delovanjem tega programa. Napake lahko zagreši strojna oprema, operacijski sistem in še kaj. Manjša okvara v dnevniški datoteki, namenjeni podvajanju, prinese okvaro podatkov na vseh podrejenih strežnikih in prekinitev podvajanja. V takem primeru nas navadno ne reši prav nič drugega kot vnovična vzpostavitev replikacije, tako kot je opisano v začetnem delu. Ker bomo morali ponastaviti vrednost zaporednega števila za podvajanje v nadrejenem strežniku, bo treba storiti enako tudi v podrejenem. Zadnji ne bo zadovoljen, če mu nadrejeni strežnik ponuja zapis z zaporednim številom 4, on pa je ravnokar izvedel poizvedbo s številom 6738828. Rešitev je v nekaj ukazih na podrejeni strežnik, kjer izklopimo podrejeni način, ponastavimo število in zaženemo nazaj podrejeni način.
mysql> SLAVE STOP;
mysql> RESET SLAVE;
mysql> SLAVE START;
Za konec
Zbira podatkov MySQL nam ponuja veliko načinov, kako podvojevati podatke med strežniki. Morda vse rešitve niso za splošno rabo, je pa mogoče marsikaj prilagoditi na strani odjemalca. Strežnik MySQL še vedno prekaša marsikaterega komercialnega tekmeca po dostopnosti, hitrosti, enostavni namestitvi in razmeroma nizkih začetnih strojnih zahtevah. Nekatere dodatne funkcionalnosti zbirke podatkov je bilo mogoče že zdaj zadovoljiti, zadnja produkcijska različica 5.0 pa prinaša veliko dobrot, ki so jih imeli do zdaj samo veliki. Morda bo tudi ta članek o možnostih uporabe koga prepričal in se bo pri naslednjem koraku odločil drugače. Za prosto izbiro seveda.