Koda, ki poganja znanost
Moderni znanstveni dosežki nas lahko s svojo bleščavo tolikanj zaslepijo, da sploh ne opazimo ramen, na katerih stojijo. Danes vsi od študentov do Nobelovih nagrajencev pri svojem raziskovalnem delu uporabljajo dosežke informacijske tehnologije. Ne gre samo za urejevalnike besedil in elektronsko pošto, današnjo znanost podpirajo algoritmi, kode, zbirke in iskalniki, ki so sami po sebi genialne iznajdbe – in često po krivici prezrte.

Stari Grki so bili že pred 2.500 leti prepričani, da je Zemlja okrogla. Pitagora je med prvimi predlagal sferično obliko planeta, pri čemer se je bolj opiral na estetske razloge kakor na meritve. Za stare Grke je bila krogla najpopolnejše telo. Slabi dve stoletji pozneje je Aristotel že nanizal vrsto argumentov, ki so temeljili na opazovanjih. In ko je Eratosten še sto let pozneje izračunal polmer Zemlje, sta mu zadoščala kos pergamenta in svinčnik. Danes lahko ta izračun ponovi vsak osnovnošolec kot ogrevalno vajo iz matematike.
Za zapletenejše izračune, ki so vsebovali trigonometrične funkcije, so stari Grki kot prvi razvili trigonometrične tablice. Za množenje in deljenje pa so uporabne logaritmične tablice, ki sta jih v začetku 17. stoletja pripravila John Napier in v desetiški obliki Henry Briggs. Z njimi se množenje in deljenje prevedeta na seštevanje in odštevanje, kar je enostavnejši problem. A še vedno gre počasi.
Ko je Anders Johan Lexell leta 1781 izračunal orbito Urana in pokazal, da gre za planet in ne komet, je za svoj podvig potreboval več mesecev. Izračunana orbita se je dobro ujemala z meritvami, ne pa popolnoma. Da je krivec verjetno kakšen planet, ki gravitacijsko vpliva nanj, so hitro posumili, a treba ga je bilo najti. Ko je John Couch Adams leta 1843 začel iz znanih podatkov izračunavati parametre neznanega planeta, je potreboval poltretje leto, da je 1846 napovedal obstoj Neptuna, ki so ga septembra res opazili. Postopek, ki ga današnji računalniki izvedejo v nekaj minutah, je trajal leta – nekoliko zaradi počasnega pridobivanja podatkov, nekoliko pa zaradi več poskusov.
Za prvo fotografijo črne luknje je bilo treba prežvečiti 4,5 PB podatkov. To je tako velika številka, da podatkov na superračunalnike v ZDA in Nemčiji niso poslali po internetu, temveč so približno tisoč diske preprosto naložili na letala in jih prepeljali na cilj.
Angleška beseda computer je sprva pomenila poklic računarja. Preden so bili izumljeni elektronski računalniki, so »človeški računalniki« izvajali dolge in zamudne izračune. Še globoko v 20. stoletje je bil človeški računalnik dragocen poklic, ki je omogočal gradnjo mostov in jezov, izračune trajektorij, statističnih tabel in celo projekt Manhattan, ki je pripeljal do izuma atomske bombe. A ko so računalniki in programski jeziki postali dostopni širši znanstveni skupnosti, se je znanost popolnoma spremenila.

»Človeški računalniki« med drugo svetovno vojno. Slika: National Security Agency, ZDA
Brez računalnikov ne gre
A v današnji znanosti so računalniške zmogljivosti nepogrešljive. Ne gre le za namizne računalnike, ki poganjajo urejevalnike besedil in preglednice ter rišejo grafe. Številni veliki dosežki danes ne bi bili mogoči brez gigaflopov računske moči.
Ko smo predlani videli prvo fotografijo črne luknje, ki jo je pripravila skupina teleskopa Event Horizon, nismo gledali enega posnetka. Fascinantno fotografijo žareče materije, ki jo požira črna luknja, so izračunali iz podatkov, ki so jih posneli radioteleskopi v Čilu, Mehiki, Španiji, ZDA in na Antarktiki. Prežvečiti je bilo treba 4,5 PB podatkov. To je tako velika številka, da je bil svojevrsten izziv zagotoviti dovolj diskov in redundance – približno tisoč diskov so uporabili. Zbranih podatkov na superračunalnike v ZDA in Nemčiji niso poslali po internetu, temveč so diske preprosto naložili na letala in jih prepeljali na cilj.

Izračunana fotografija črne luknje iz leta 2019. Slika: Kolaboracija Event Horizon Telescope
Fotografija črne luknje predstavlja ekstremen primer, a v manjšem merilu je veliko znanosti podobne. Na lokalnih računalnikih gručah po vsem svetu teče na milijone simulacij, od reševanja navier-stokesovih enačb prek kvantne kemije do izračunavanja posnetkov kriomikroskopov.
Danes imajo tudi namizni računalniki tisočkrat višje kapacitete, kot so jih imeli najzmogljivejši računalniki v 60. in 70. letih. Večina rezultatov, ki jih izpljunejo instrumenti, je že rutinsko tako obdelana, da večina študentov in znanstvenikov nikoli ne vidi surovih podatkov iz meritve. Ne le odštevanje baznih linij, temveč tudi dekonvolucije, fourierjeve transformacije in podobno so skriti našim očem. A nekdo je moral napisati kodo, ki to počne, še pred tem pa razviti strojno opremo, ki to zmore.
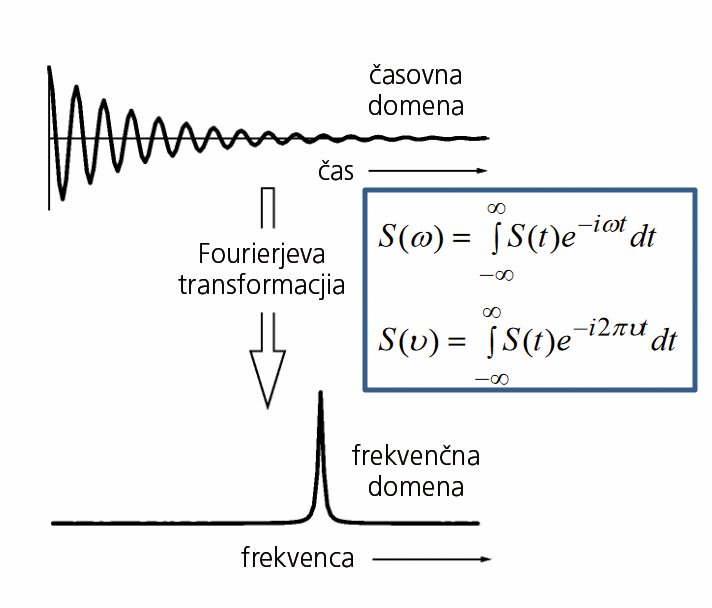
Surovi signal jedrske magnetne resonance programi samodejno obdelajo s fourierjevo transformacijo.
Strojna oprema je zmogljiva, a sama po sebi neuporabna železnina. Raziskovanje je danes neločljivo povezano s programsko opremo, čeprav se tega ne zavedamo. V novice se prebijejo največji znanstveni dosežki, kjer je v ekstremnih primerih kot zanimivost omenjeno tudi programersko ozadje (denimo pri posnetku črne luknje), sicer pa razvoj računalniških metod ostaja prezrt. Takšnega nizkega ugleda nima le v širši javnosti, temveč tudi v znanosti sami. Nobelove nagrade za matematiko ali računalništvo ni. Nobelovo nagrado za fiziko so dobili tudi izumitelji integriranega vezja pa, na primer, vrstičnega mikroskopa, ne pa za algoritemske ali programske dosežke. Vsaj na tem mestu zato poglejmo nekaj največjih dosežkov, ki so spremenili znanost.
Jeziki in algoritmi
Fortran. Prvi računalniki so bili namenjeni le posvečenim. Programiranje je bilo pretikanje povezav in vodnikov. Tudi razvoj strojnega jezika in zbirnika raziskovalcem drugih ved ni prinesel olajšanja, saj je bilo treba še vedno zelo dobro poznati ustroj posameznega modela. Prvi jezik, ki je resnično približal računalnike drugim uporabnikom, je bil Fortran (formula translation). V 50. letih je John Backus v IBM predlagal razvoj višjenivojskega jezika od zbirnika, ki bi omogočal lažje programiranje. Sestavil je ekipo desetih razvijalcev, ki je do leta 1957 pripravila programski jezik in dokumentacijo. S Fortranom je bilo prvikrat mogoče sešteti dve števili tako, da smo »napisali« 1 + 1.

Prvi programi v Fortanu so bili zapisani še na luknjanih karticah. Slika: Arnold Reinhold
Prvi računalniki, na katerih je tekel Fortran, so še vedno uporabljali luknjane kartice. Obširnejša koda za zapletene probleme je bila zapisana na več tisoč karticah, a vseeno je kemik lahko prvikrat sam napisal in pognal ustrezen program. Fortran se je izkazal tudi kot neverjetno trdoživ programski jezik, ki je do danes doživel precej nadgradenj, v katerih je dobil strukturirano programiranje, modularno programiranje, objektno orientirano programiranje in vzporedno programiranje. Fortran, ki je predstavljal zgled za razvoj številnih mlajših jezikov, denimo Basica, se še danes poučuje na številnih naravoslovnih fakultetah. V njem je napisano tudi ogromno kode, ki se še danes uporablja v produkcijskem okolju, torej za realne raziskave. Znameniti paket za periodično kvantno kemijo VASP je še leta 2021 napisan v Fortranu in C. Fortran se še vedno izdatno uporablja pri modeliranju podnebja in pri simulacijah dinamike fluidov. Priljubljen je povsod, kjer gre za veliko premetavanja številk, torej linearne algebre, saj so programi hitri in prijazni do pomnilnika, če so napisani učinkovito. Za računsko manj zahtevne algoritme se pogosteje uporablja Python, ki je prijaznejši do programerjev, in drugi bolj specializirani jeziki, na primer R.

Računalnik CDC 6600 iz leta 1964, na katerem je tekel tudi Fortran.
Toda Python ima kljub vsem svojim prednosti pomembno pomanjkljivost. Ker je interpretni jezik, torej se izvaja vrstico po vrstico brez predhodnega prevajanja celotne kode, se lahko uporablja kot REPL (read-eval-print loop). To pomeni, da uporabnik piše kodo, interpreter pa jo sproti izvaja. Vseeno pa čisti Python ni najprimernejši za znanost, saj mu manjkata enostavno prednalaganje modulov (potrebnih za kompleksno obdelavo podatkov) in boljša vizualizacija podatkov (da se okna ne zapirajo) itd.
Fernando Pérez je zato leta 2001 napisal IPython (interaktivni Python), ki v vsega 259 vrsticah prinaša interaktivnost. Iz teh začetkov se je leta 2011 razvil IPython Notebook, ki je od leta 2014 znan kot Jupyter Notebook. Ta omogoča, da v en dokument združimo kodo, vizualizacijo in oblikovano spremljajoče besedilo, kakor da bi pisali v digitalni zvezek. IPython Notebook seveda ni bil prvi interaktivni zvezek, a ker je bil od vsega začetka odprtokoden, je postal priljubljen. Jupyter Notebook ne podpira več zgolj Pythona, temveč vse pomembnejše jezike (okrog sto). Danes je Jupyter (ime izvira iz prvih jezikov, ki jih je podpiral – Julia, Python in R) v podatkovni znanosti postal standard, kako se predstavljajo in tudi obdelujejo podatki. Na Githubu je več kot 10 milijonov teh zvezkov, vključno z največjimi odkritji, denimo gravitacijskih valov.
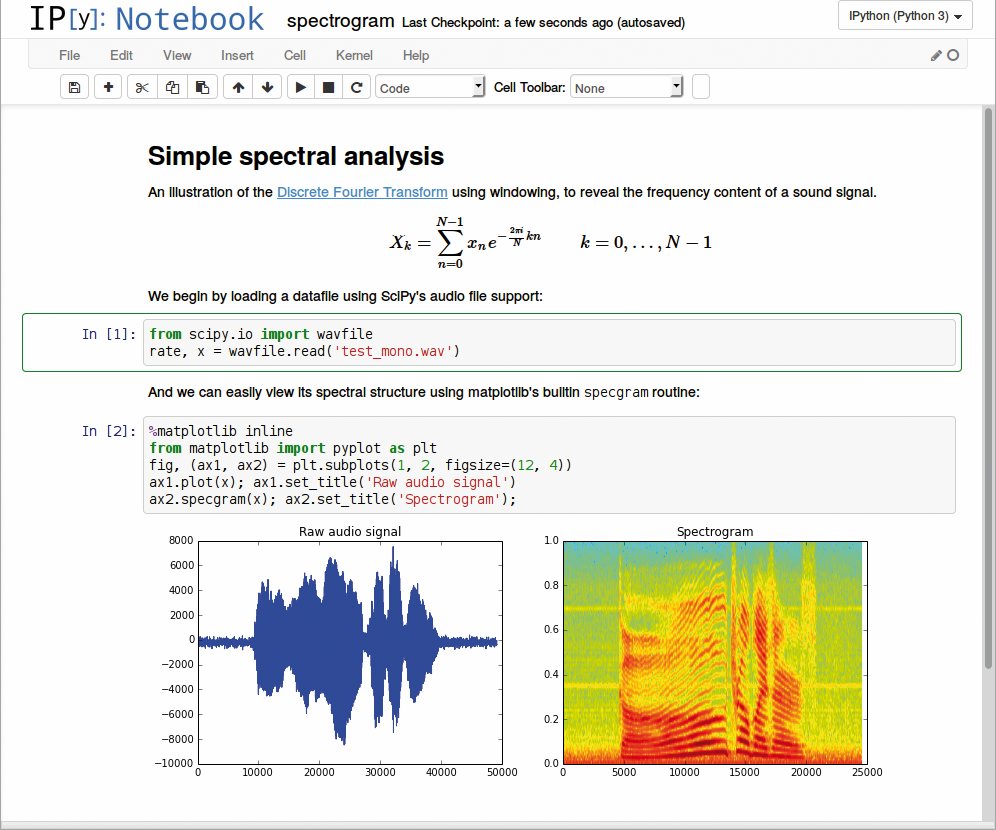
Jupyter omogoča pripravo interaktivnih zvezkov, ki vsebujejo oblikovano besedilo, podatke, kodo in vizualizacije. Slika: Alex Rogozhnikov
FFT je kratica, ki vsakemu računalnikarju ali naravoslovcu prikliče močna čustva – negativna ali pozitivna. Fourierjeva transformacija je matematična operacija, s kateri prehajamo med časovno (ali prostorsko) ter frekvenčno domeno. Fourierjeva transformacija je posnet zvok, ki ga funkcija spreminjanja zračnega tlaka v odvisnosti od časa pretvori v frekvenčni diagram. Fourierjeva transformacija sega v začetek 19. stoletja, a šele leta 1965 sta ameriška matematika James Cooley in John Turkey z njo spremenila svet (zanimivo je, da je enak algoritem že leta 1805 odkril Gauss, a ga ni objavil).
Odkrila sta namreč algoritem za hitro fourierjevo transformacijo (FFT), ki nima zahtevnosti O(n2), temveč O(n log2 n). Za tisoč podatkovnih točk je pospešitev 100-kratna, za milijon točk 50.000-kratna in za milijardo točk kar 33-milijonkratna. FFT je verjetno najpomembnejši algoritem, ki ga izkorišča moderni svet in je tako pogost, da ga pravzaprav nihče več ne piše sam. Knjižnic, ki so zoptimizirale FFT za različne arhitekture, je toliko kot arhitektur, saj je hitrost FFT ozko grlo številnih izračunov – ena najhitrejših odprtokodnih implementacij je FFTW. FFT je danes ključen pri obdelavi digitalnih signalov različnih vrst, kar sega od analize slik do interpretacije signala nuklearne magnetne resonance.
Večina znanstvenega računanja uporablja zelo omejen nabor matematičnih operacij, ki pa se ponavljajo in ponavljajo, zato je ključno, da jih standardiziramo in pohitrimo. Z linearno algebro, torej z vektorji, matrikami in s tenzorji, se rešuje večina problemov. To niso zelo zapletene operacije, so pa lahko računsko požrešne, če jih naivno implementiramo. Spočetka so morali raziskovalci pisati lastne rutine zanje, kar je bilo potratno na obeh konceh: z vidika človeškega in računskega časa. Nobenega smisla nima, da strokovnjak za jedrsko fiziko izgublja čas s pisanjem algoritma, ki v nobenem primeru ne bo tako hiter kot izpiljena koda profesionalnih programerjev. Svoj čas koristneje porabi z ukvarjanjem s svojo znanstveno specialnostjo, ne pa s pisanjem programske kode.
Že zelo kmalu v 70. letih, ko se je uporabljal večinoma Fortran, je nastalo kup knjižnic za višje operacije, kot sta iskanje inverza matrike, reševanje sistemov enačb ipd. Te knjižnice so bile učinkovite, a še vedno okorne. Pri množenju matrik je bilo, na primer, treba uporabiti tri gnezdene zanke. Z naraščanjem kompleksnosti se je pokazala potreba po standardizaciji, zato je leta 1979 Fortran dobil knjižnico BLAS (Basic Linear Algebra Subprograms). Ta se je nadgrajevala še vrsto let in je uporabna še danes za operacije linearne algebre na vektorjih in matrikah. BLAS je prerasel v standard, ki ga lahko izvaja več knjižnic (ACML, MKL, OpenBLAS), te pa potem izkorišča cel kup programske opreme (LAPACK, LINPACK, Mathematica, Matlab, NumPy, R itd.). Večina knjižnic uporablja standardni vmesnik, zato pri razvoju programske opreme ni treba vedeti, katero implementacijo BLAS bomo imeli nameščeno. Velja tudi obratno – na različne arhitekture superračunalnikov se namesti specialno optimizirane BLAS, s čimer iz strojne opreme iztisnemo več. Še danes večina znanstvene programske opreme, ki intenzivno dela z operacijami iz linearne algebre, uporablja BLAS.

Tudi na najhitrejšem superračunalniku na svetu Fugaku so hitrost izmerili z LINPACK, ki uporablja tudi knjižnice BLAS.
Podatkovne zbirke in repozitoriji
Moderno znanost podpira še en kos programske opreme, ki ga celo računalniško bolj zavedni raziskovalci često spregledajo, ker pač ne teče na njihovih prenosnikih ali superračunalnikih. Ogromne podatkovne zbirke tiho podpirajo znanost, ko kot digitalne knjižnice strežejo podatke. Zlasti na področju bioznanosti so podatkovne zbirke nujne za kakršnokoli delo, saj vsebujejo podatke o genskih zaporedjih, zgradbi proteinov itd. Ključna značilnost teh zbirk je, da so univerzalne, ne pa povezane s konkretnim raziskovalnim problemom.
Začetki segajo v 60. leta, ko je Margaret Dayhoff pripravila Atlas of Protein Sequence and Structure s podatki o zaporedju, strukturi in zgradbi 65 znanih proteinov – tedaj so bili ti podatki še na luknjanih karticah. V 70. letih so metode za eksperimentalno določanje zgradbe makromolekul postale rutinske, denimo rentgenska kristalografija in jedrska magnetna resonanca, hkrati pa so računalniki postali zmožni vizualizacije teh struktur. To je dalo zagon postavljanju zbirk, med katerimi je danes najpomembnejša Protein Data Bank, v kateri so vse znane strukture bioloških makromolekul, denimo proteinov in nukleinskih kislin (DNK, RNK). Postavili so jo davnega leta 1971, do danes pa je nabrala že okrog 170.000 struktur.

Atlas of Protein Sequence and Structure iz leta 1965 je papirni prednik modernih podatkovnih zbirk v vedah o življenju.
Za genska zaporedja pa obstajajo tri primarne zbirke. GenBank ima korenine v letu 1982 in vsebuje podatke o več kot 300.000 organizmih. Evropsko zbirko ureja EMBL (European Molecular Biology Laboratory), japonsko DDBJ pa tamkajšnji inštitut za genetiko.
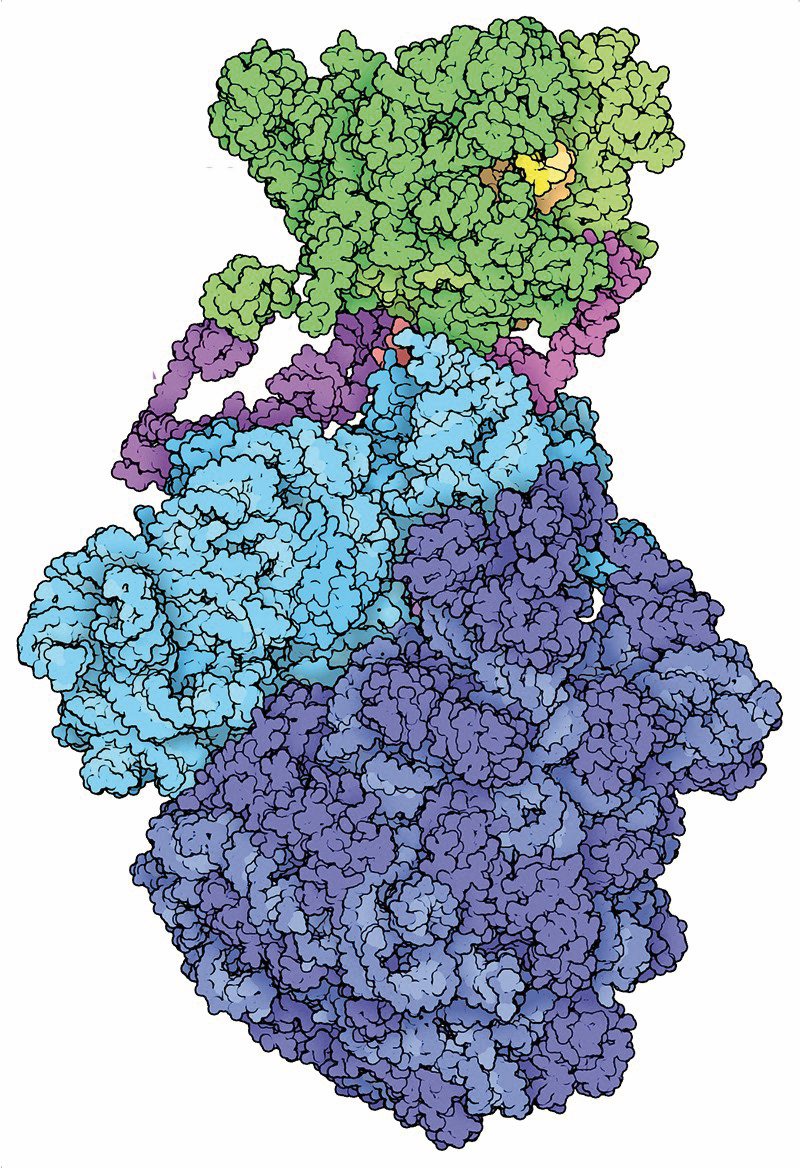
V Protein Data Bank so podatki o strukturi skoraj vseh znanih proteinov. Slika: David S. Goodsell and RCSB PDB
Obstaja še več deset drugih, specializiranih zbirk za najrazličnejše namene: o izražanju proteinov, interakcijah med njimi, metabolnih poteh, proteinskih zaporedjih itd.
Tovrstne zbirke so v znanost prinesle povsem nov model raziskav. Namesto eksperimentov ali teoretičnih izračunov je mogoče kopáti po ogromnih količinah podatkov in iskati korelacije. Znamenit primer je iz leta 1983, ko sta dve neodvisni skupini odkrili sorodnost v genskem zapisu enega človeškega rastnega faktorja in virusa, ki v opicah povzroča raka. Odtlej je analiziranje genskih zapisov in iskanje podobnosti nepogrešljiv del ved o življenju.
Če imamo podatkovne zbirke, potrebujemo tudi dobre iskalnike. Kakor se na spletu orientiramo z Googlom, se po zaporedjih bioloških legokock z orodjem BLAST. Običajno je eden prvih korakov po določitvi novega zaporedja, denimo sekvenciranju nekega virusa, iskanju po BLAST, kaj mu je najbolj podobno. To pa ni zgolj enostavno iskanje, saj se ne išče zgolj ujemanj, temveč podobnost. BLAST to zmore dobro, učinkovito in hitro, zato je eden najširše uporabljenih programov v bioinformatiki.
Njegovi začetki segajo v leto 1985, zamisel pa je še starejša. Leta 1978 je Margaret Dayhoff postavila prva merila (Dayhoff matrix), kako bomo kvantitativno ocenjevali podobnost med dvema proteinoma. Ne zadostuje pogledati zgolj, kako podobna sta si trenutno po strukturi, temveč govorimo tudi o evolucijski oddaljenosti. Sedem let pozneje smo torej dobili algoritem FASTA, ki je omogočal iskanje glede na to matriko. Ta se je do leta 1990 razvil v BLAST (Basic Local Alignment Search Tool). To je zmogljivo orodje, ki ne omogoča le iskanja, temveč tudi ocenjuje evolucijsko oddaljenost, verjetnost, da je podobnost zgolj slučajna, in še kup drugih metrik. BLAST ni edini algoritem, ki omogoča tovrstno iskanje in vzporejanje, je pa najhitrejši in najbolj razširjen. BLAST raziskovalcem ved o življenju pomeni toliko, da je postal glagol – kakor na spletu guglamo, zaporedja blastamo. In tako dobimo informacije o bioloških vrstah in filogenetiki, domenah na proteinih, genih, DNK itd.
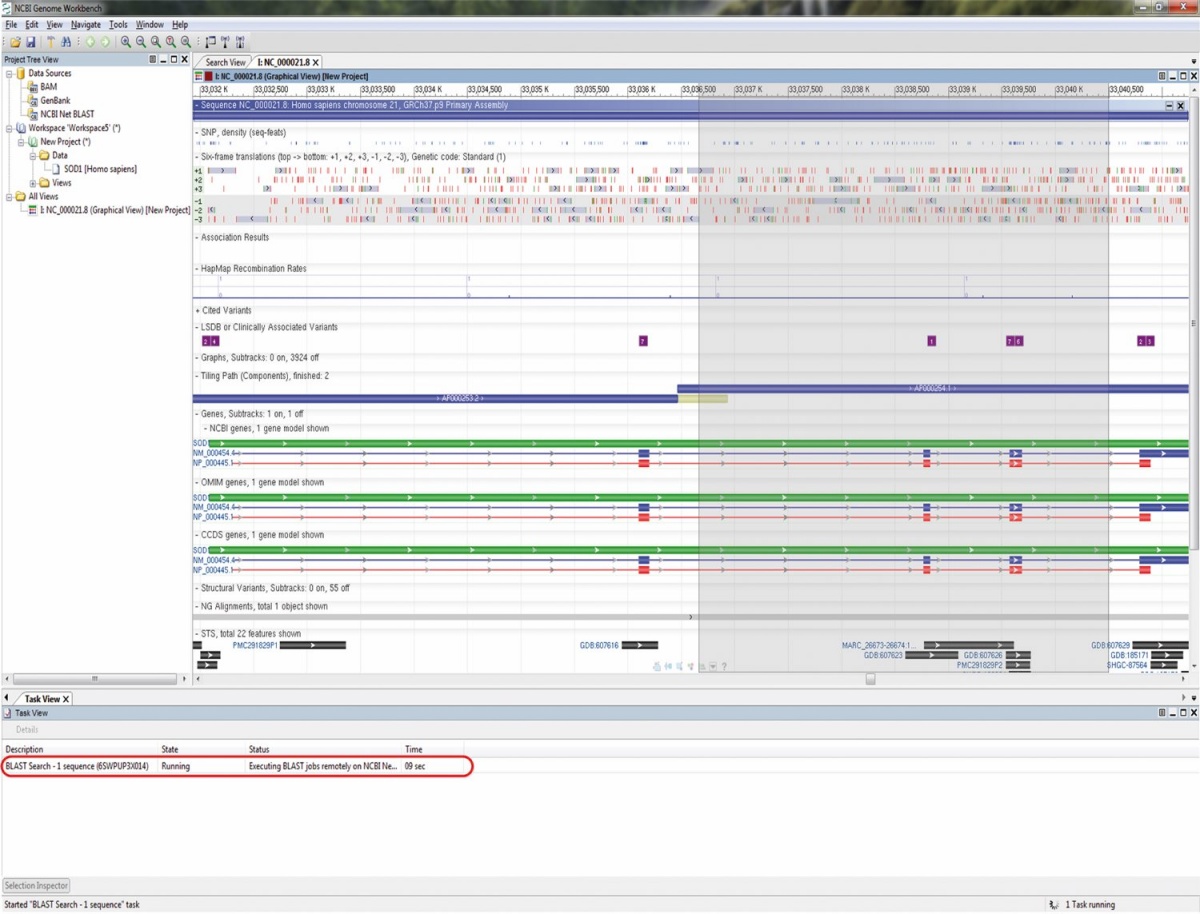
BLAST je algoritem in orodje za iskanje po zbirkah genskih zaporedij. Slika: NCBI Genome Workbench
Kam gre znanje
Na koncu omenimo še repozitorije. Vso nabrano védenje nič ne koristi, če do njega ne moremo. Valuta znanosti so članki, saj v knjige z zamudo pride manj podrobnosti. Pred razmahom interneta so si raziskovalci pošiljali rokopise oddanih člankov po pošti, kar je bilo zamudno in ekskluzivno, saj so bili med prejemniki prijatelji in najuglednejši znanstveniki. Leta 1991 so v Los Alamos National Laboratoryju napisali robota za elektronsko pošto, ki je vsem članom na dopisnem seznamu dnevno razposlal seznam novih rokopisov, da so lahko potem zahtevali članke.
Projekt je začel Paul Ginsparg, ki sprva ni imel velikopoteznih načrtov. Članki so bili omejeni na področje fizike visokih energij, rokopise pa je nameraval hraniti tri mesece, saj so potem tako in tako v fizični obliki v neki reviji. Sčasoma je iz oglasne deske nastal arhiv, ki ga je Ginsparg leta 1993 postavil na splet. Še pet let pozneje, torej leta 1998, je dobil ime, po katerem ga poznamo še danes arXiv.org. To je še danes največji repozitorij rokopisov. (To so običajno v LaTeX napisani članki, ki jih avtorji potem običajno pošljejo še v kakšno revijo, kjer se po recenzentskem postopku objavijo). Dasi ostaja arXiv največji – dandanes ima dva milijona rokopisov in vsak mesec dobi 15.000 novih –, pa ni edini tovrstni repozitorij. V zadnjih letih, ko je postala dostopnost znanstvenih člankov, ki jih revije skrivajo za plačljive zidove in drage naročnine, evropska prioriteta, so vzniknili še številni drugi: bioRxiv, medRxiv, ChemRxiv, HAL …
Prihajata kvantna doba in umetna inteligenca
V zadnjem desetletju je najbolj vroča tematika umetna inteligenca, ki je do neke mere že tu, tik za njo pa kvantno računalništvo. Za uporabo umetne inteligence oziroma strojnega učenja že obstajajo številne knjižnice in SDK, denimo Googlov TensorFlow, ki je brezplačen. A še pred tem je bil AlexNet.
Umetna inteligenca, ki nima vnaprej definiranih rigidnih pravil, posnema naravno učenje v možganih. Eden najpomembnejših prispevkov je konvolucijska nevronska mreža AlexNet, ki so jo leta 2012 objavili Alex Krizhevsky, Ilya Sutskever in Geoffrey Hinton. Pripravili so jo za sodelovanje na tekmovanju ImageNet. To je velika zbirka več kot 14 milijonov fotografij, ki imajo ročno dopisano, kaj je na njih. To zbirko uporabljajo za učenje umetne inteligence pri prepoznavanju slik, vsako leto pa organizirajo tudi tekmovanje (na drugi zbirki fotografij), kjer lahko razvijalci preizkusijo svoje algoritme za prepoznavanje slik. Leta 2012 je AlexNet na tekmovanju pometel s konkurenco, ko je pravilno prepoznal 84 odstotkov fotografij – drugouvrščeni je imel dvakrat več napačno določenih.
AlexNet je morda posebej znan tudi po srečnem spletu okoliščin, saj je k njegovemu uspehu poleg brez dvoma briljantnega programiranja in dovolj velike zbirke fotografij za trening pomembno prispevala tudi zmogljiva strojna oprema. Ravno tedaj so namreč grafične kartice postale dovolj zmogljive in vsestranske, da so se lahko uporabljale še za kaj drugega kot izris grafike. Konvolucijske nevronske mreže so sicer starejše, avtorji AlexNeta pa pravijo, da je ključni preboj uspel že leta 2009, ko so eno mrežo natrenirali, da je prepoznavala govor.
Danes so nevronske mreže že dovolj razvite, da rutinsko prepoznavanje govora in prepoznavanje fotografij uporabljajo vsakdanji izdelki. Mobilnim telefonom lahko narekujemo, po internetu lahko iščemo dani fotografiji podobne (reverzno iskanje) ipd. A vse se je začelo z nevronskimi mrežami, ki so sicer stara zamisel iz 50. let preteklega stoletja, a so šele v tem stoletju postale praktično uporabne.
Pričujoča zgodba se končuje, kjer se – upajmo – šele začenja prihodnost. Kvantno računalništvo je še v povojih, saj različni igralci gradijo svoje računalnike in pristope. Spomnimo se, D-Wave, ki ponuja nekaj tisoč kubitne kvantne računalnike, na drugi strani pa je Google predlani z 72 kubiti oznanil kvantno premoč (torej rešitev problema, ki s klasičnimi računalniki v realnem času ni mogoča). Za zdaj ne vemo niti, katera implementacija bo na koncu prevladala, kaj šele, kako bo videti kakšna standardizirana knjižnica za uporabo kvantnih algoritmov. Prvi poskusi pa so že tu, denimo IBM Quantum Researchers Program, ki je brezplačno na voljo raziskovalcem. Prihodnosti bo še zelo zanimiva.
Nadaljnje branje
• Jeffrey M. Perkel, Ten computer codes that transformed science, Nature, januar 2021
• Jeffrey M. Perkel, Why Jupyter is data scientists’ computational notebook of choice, Nature, oktober 2018
• Helen Shen, Interactive notebooks: Sharing the code, Nature, november 2014
• Paul Ginsparg, ArXiv at 20, Nature, avgust 2011