Hibernate
Pri razvoju informacijskih sistemov danes uporabljamo predmetne jezike. Med najbolj priljubljene sodita java in C#. Za shranjevanje podatkov uporabljamo skoraj izključno relacijske zbirke podatkov. Pri uporabi predmetnih jezikov in relacijskih zbirk podatkov pa prihaja do konceptualnih razlik pri pretvorbi podatkov iz ene oblike v drugo.
Pri predmetnih programskih jezikih so podatki predstavljeni v obliki predmetov. Predmeti poleg podatkov vsebujejo metode, ki predstavljajo možne operacije. Predmeti lahko vsebujejo druge predmete ali so povezani z njimi. Predstavitev problema na tak način je zelo naravna, saj predmeti zelo dobro predstavljajo resnični svet. Izkoriščamo lahko prednosti, kot so dedovanje, mnogoličnost, vmesniki...
V nasprotju s predmetnim modelom imamo v relacijski zbirki podatkov podatke v tabelah. Do podatkov pridemo s pomočjo poizvedbenih stavkov v jeziku SQL. Za vsak predmet, ki ga uporabljamo, moramo načeloma napisati štiri poizvedbe, in sicer za branje, spreminjanje, vstavljanje in brisanje. Pisanje takih enostavnih poizvedb, pretvorba podatkov v predmete in shranjevanje nazaj je sorazmerno rutinsko delo. Kljub temu zavzema razmeroma velik del časa razvoja informacijskega sistema.
Kljub razlikam med modeloma je možna avtomatska pretvorba iz ene oblike v drugo. Tako pretvorbo imenujemo predmetno-relacijska preslikava. Ta avtomatsko generira vse potrebne poizvedbe in predmete v času izvajanja. Programerju se ni več treba ukvarjati s tem, kako se podatki berejo in shranjujejo (načeloma).
Predmetno-relacijska preslikava je postala priljubljena, ko je Sun skupaj z J2EE predstavil tehnologijo Enterprise JavaBeans (EJB). Tehnologija je bila revolucionarna novost, zato so ji napovedovali svetlo prihodnost. Žal je bila za praktično uporabo veliko preveč zapletena in je razvoj, namesto da bi ga pospeševala, zavirala. Zaradi kompleksnosti tehnologije entitetnih zrn in njenih slabosti je nastalo veliko novih tehnologij, ki pa so obdržale osnovno zamisel - pretvorbo relacijske podatkovne sheme v predmetno. Tako je Sun predstavil JDO, Oracle TopLink ... Na voljo pa je tudi veliko število odprtokodnih rešitev. Med njimi ima glavno vlogo Hibernate. Tega vsak mesec posname iz interneta kar 13.000 uporabnikov. Tako je postal najresnejša alternativa dostopa do podatkov v okolju jave.
Hibernate je predmetno-relacijski preslikovalni mehanizem za javo, kar pomeni, da podatke, zapisane v relacijski zbirki podatkov, pretvori v javanske predmete. To so popolnoma običajni javanski predmeti (POJO - Plain Old Java Objects oz. Plain Ordinary Java Objects) in zato ne vsebujejo mehanizma, ki bi skrbel za shranjevanje. Ne zavedajo se, kako se preberejo iz zbirke ali se vanjo shranijo. Za to skrbi Hibernate, ki v času izvajanja generira vse potrebne poizvedbe. Cilj Hibernata je, da tako rešimo 95 % dela z zbirko podatkov. Za drugo lahko še vedno napišemo klasične poizvedbe SQL.
Hibernate je odprtokodni projekt, izdan pod licenco LGPL (Lesser General Public License), ki omogoča brezplačno uporabo tudi v komercialne namene.
Arhitektura
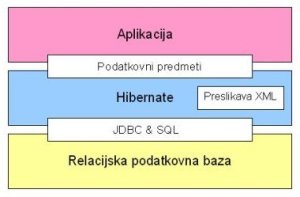
Arhitektura Hibernata
Predmetno-relacijska preslikava ustvarja poseben sloj, ki se programerju predstavlja kot predmetna zbirka podatkov. Ne dela več s tabelami, stolpci, vrsticami, povezavami - elementi, ki sestavljajo relacijsko zbirko. Podatki so predstavljeni kot predmeti s svojimi metodami, atributi in povezavami z drugimi predmeti. Do atributov predmeta lahko pridemo z metodama "set" in "get".
Poseben sloj Hibernatu omogoča poizvedovanje s posebnim poizvedovalnim jezikom HQL, ki spominja na SQL, a je popolnoma predmeten. Za to, da Hibernate lahko prebere podatke, generira klasične stavke SQL. Do zbirke podatkov pride s pomočjo javanske tehnologije JDBC. Prebrane predmete lahko shranjuje v predpomnilnik, kar zelo pospeši delovanje pri pogostem dostopu do istih podatkov.
Poseben nivo predmetov in jezik HQL Hibernatu omogočata, da je neodvisen od zbirke podatkov. Določimo mu različico SQL jezika, ki naj jo uporablja, ter poskrbimo za ustrezen gonilnik JDBC. Ob menjavi zbirke podatkov samo spremenimo nastavitve za vrsto zbirke podatkov in gonilnik JDBC. Tak način pa deloma omejuje zmogljivost Hibernata, saj lahko podpira samo skupno podmnožico zmogljivosti vseh zbirk podatkov. Do zbirke pa lahko pridemo tudi s klasičnimi SQL stavki, kar omogoča izkoriščanje večine zmogljivosti zbirke podatkov in optimizacijo poizvedb.
Kot druge tehnologije za predmetno-relacijsko preslikavo je tudi Hibernate nastal po vzoru poslovnih javanskih zrn (Enterprise JavaBeans - EJB). EJB sestavljajo tri vrste poslovnih predmetov (zrn):
Hibernate nadomešča le entitetna zrna (entity beans). Njegova pomembna prednost v primerjavi z entitetnimi zrni je, da ga lahko uporabljamo tudi zunaj programskega strežnika. Ko ga uporabljamo v programskem strežniku, sejna in sporočilna zrna še vedno uporabljajo svojo funkcijo.
Preslikava
Programer mora za predmetno-relacijsko preslikovanje izdelati datoteko XML, ki vsebuje podatke za preslikavo. Iz nje se lahko avtomatsko ali ročno izdela javanske razrede. Možna je tudi izdelava datoteke XML iz javanskih razredov, če vanje dopišemo potrebne parametre v zapisu javadoc. Razen generiranja razredov iz XMLja ali nasprotno Hibernate ne uporablja generiranja kode. To je njegova velika prednost v primerjavi z drugimi rešitvami.
Zgled zapisa predmetno-relacijske preslikave v zapisu XML:
<class name="Racun" table="RACUN">
<id name="id" column="ID">
<generator class="native"/>
</id>
<property name="stRacuna" column="st_racuna" type="string" length="30"/>
<property name="datum" type="date" />
<many-to-one name="partner" class="Partner" column="partnerID" not-null="true"/>
<set name="postavke" cascade="all" >
<key column="prej_racID"/>
<one-to-many class="Postavke"/>
</set>
</class>
Hibernate zna iz preslikave sam tvoriti tabele, stolpce in omejitve v zbirki podatkov. To lahko izvede celo sam ob zagonu programa.
Tipizacija atributov
Hibernate podatke preslika v predmete. Do podatkov pridemo prek metod "set" in "get". Tak način dostopa imenujemo močna tipizacija atributov. Zgled (v javi):
String nazivPartnerja = partner.getNaziv();
...
partner.setNaziv(nazivPartnerja);
To znatno olajša programiranje, saj sodobna razvojna orodja s pomočjo dokončevanja kode pomagajo programerju. Taka tipizacija tudi omogoča razvojnemu orodju, da opozarja na napake v kodi. Ne more se npr. zgoditi, da bi uporabili atribut, ki ga ni. V končnem pa se tak program tudi ne prevede, kar je bistveno bolje kot pri netipiziranih atributih, kjer do napak pride šele pri izvajanju programa.
Predpomnjenje
Vmesni nivo predmetov omogoča predpomnjenje podatkov. Do izraza pride pri pogostem dostopu do istih podatkov. Taki so spletni programi, ko veliko število uporabnikov uporablja iste podatke. Predstavljajmo si npr. spletno stran z novicami. Vsi uporabniki uporabljajo novice. Če te niso dostopne v pomnilniku, mora namenski program za vsakega uporabnika prebrati novice iz zbirke podatkov. Predpomnjenje je popolnoma transparentno s stališča programerja. Ni mu treba vedeti, od kod se bodo brali podatki. Uporablja dve vrsti predpomnilnika - sejnega ali transakcijskega in drugonivojskega.
Hibernate je namenjen skoraj samo uporabi v programskih in internetnih strežnikih. Tako le ena instanca Hibernata dostopa do podatkov. Le tako se lahko izkoristi možnost predpomnjenja. V nasprotnem primeru predpomnjenja ne smemo uporabljati, saj podatke lahko uporablja še kdo brez vednosti Hibernata in ima zato v predpomnilniku zastarele podatke.
Odklopljeni način dela s podatki
Podatki v Hibernatu so predstavljeni kot običajni predmeti, ki se ne zavedajo, kako se shranjujejo. Za to skrbi Hibernate, ki bere in shranjuje podatke s pomočjo preslikave, zapisane v XMLju. Hibernate povezavo vzpostavi le ob branju in shranjevanju in tako omogoča odklopljeni način dela. Stalna povezava ni potrebna, kar je bil problem pri starejših tehnologijah. S tem se bistveno povečuje zmogljivost in stopnjevanost (scalability), saj uporablja veliko manj strežniških virov v primerjavi z rešitvijo, ki uporablja trajno aktivno povezavo.
Ob pogostem vzpostavljanju povezave pride do drugega problema. Samo vzpostavljanje povezave zahteva nekaj časa. Če imamo veliko odjemalcev, ki se neprestano povezujejo, izvedejo kratko operacijo in prekinejo povezavo, predstavlja samo vzpostavljanje povezave velik del porabe virov. To rešuje mehanizem za izmenjavo povezave (connection pooling). Ta vzdržuje skupino odprtih povezav. Ko program potrebuje povezavo, mu jo začasno dodeli.
Pisanje poizvedb
Pri Hibernatu poizvedbe pišemo v poizvedovalnem jeziku HQL, ki je popolnoma predmeten in zato omogoča funkcionalnosti, ki jih pri klasičnem jeziku nismo vajeni. Poizvedbe vračajo predmete in ne tabel s podatki kot klasični SQL. Prek vrnjenega predmeta lahko uporabljamo tudi povezane predmete, čeprav nismo poizvedovali po njih. Ti se avtomatično naložijo iz zbirke podatkov, ko jih uporabljamo. Pisanje poizvedb je bistveno lažje in hitrejše. Pri združenju (join) niso več potrebni ključi, po katerih združujemo, saj Hibernate ve za ključe posameznih predmetov in povezave med njimi. Napisane poizvedbe so bistveno krajše in preglednejše.
Hibernate v času izvajanja pretvori HQL poizvedbo v eno ali več poizvedb SQL. Poizvedbe HQL so tako neodvisne od zbirke podatkov.
Preprosta poizvedba SQL:
Branje vseh partnerjev:
SELECT * FROM partner
Enakovredna poizvedba HQL:
from Partner
Zahtevnejša poizvedba SQL:
Seznam dobaviteljev, ki nam dobavljajo material granulat:
SELECT partner.naziv AS partner_naziv
FROM prejeti_racun INNER JOIN
postavka_prej_rac ON prejeti_racun.ID =
postavka_prej_rac.prej_racID
INNER JOIN material material
ON postavka_prej_rac.materialID = material.ID
INNER JOIN partner ON prejeti_racun.partnerID =
partner.ID
WHERE (material.naziv = 'granulat')
Enakovredna poizvedba HQL:
select dobavnica.partner.naziv
from PrejetiRacun dobavnica
inner join dobavnica.postavke postavka
where postavka.material.naziv = 'granulat'
Pozna večino operacij, ki smo jih vajeni iz SQLa, kot npr. sortiranje (order by), grupiranje (group by), združevanje (join), agregacijo (count, avg, sum, min, max) ... Nepodprta je unija, kar je sorazmerno velika slabost.
Podpira tudi matematične operacije, primerjavo, logične operatorje ipd., a le v where delu poizvedbe. To je velika ovira, saj pogosto potrebujemo, da nam poizvedba npr. zmnoži dva stolpca.
Možna je tudi uporaba ugnezdenih poizvedb, vendar le v where delu poizvedbe. Če podatkovni strežnik podpira ugnezdene poizvedbe, zna Hibernate to izkoristiti, drugače pa generira več klasičnih poizvedb. Pogrešamo uporabo ugnezdenih poizvedb v from delu poizvedbe, saj so te performančno ugodnejše.
Do zbirke lahko imamo dostop tudi prek klasičnih SQL stavkov. V poizvedbi SQL navedemo, v katere atribute na predmetih naj se rezultati preslikajo, tako da je delo s podatki še vedno predmetno.
Generiranje enostavnih poizvedb
Hibernate skrbi za polnjenje predmetov s podatki iz zbirke podatkov in tudi zapisovanje spremenjenih podatkov nazaj vanjo. Zato avtomatsko generira poizvedbe za branje in shranjevanje v času izvajanja. Pri tem zna biti kar se da optimalen. Bere le podatke, ki jih nima v predpomnilniku. Shranjuje le podatke, ki so bili spremenjeni. Omogoča branje podatkov po potrebi, torej šele, ko in če jih potrebujemo. Generirati zna tudi poizvedbe za branje podatkov povezanih predmetov.
Napreden mehanizem generiranja poizvedb še ne pomeni, da je vedno optimalen. Po trditvah uradne dokumentacije pa naj bi povzročal manj kot 10 % dodatnih JDBC klicev. Pri tem mora programer dobro poznati delovanje Hibernata, da vedno uporabi najustreznejši mehanizem. V nasprotnem primeru lahko pride do zelo neoptimalnih poizvedb, kot je npr. generiranje poizvedb za branje vsakega zapisa tabele posebej namesto branja vseh zapisov z eno poizvedbo.
Branje podatkov po potrebi
Pri programiranju velikokrat preberemo več podatkov, kot bi jih potrebovali, ker ne vemo, katere bomo potrebovali. Hibernate ta problem rešuje z mehanizmom, imenovanim branje po potrebi (lazy loading), ki avtomatsko poskrbi za branje podatkov, ko jih potrebujemo.
Pri uporabi tega mehanizma nam kot rezultat poizvedbe vrne posredniške predmete (proxy). Ti delujejo kot običajni predmeti, a ne vsebujejo podatkov. Ko jih uporabljamo, sami poskrbijo za branje iz zbirke podatkov.
Možnost branja po potrebi pride še bolj prav pri branju povezanih predmetov. Ko že imamo na voljo predmet, želimo dostop do predmetov, s katerimi je ta povezan. Te se lahko nalagajo takoj ob branju izhodiščnega predmeta ali pa se naložijo po potrebi, ko predmete uporabljamo. Npr. če iz zbirke preberemo artikel in želimo prek njega dostop do vseh dobaviteljev, se ti avtomatsko preberejo iz zbirke, ko jih potrebujemo. To se zgodi brez posebne zahteve programerja. Ta dela s podatki, kot da bi imel vse na voljo v pomnilniku.
Podpora zbirk podatkov
Hibernate podpira vse bolj razširjene zbirke podatkov: Oracle, DB2, Sybase, MS SQL Server, PostgreSQL, MySQL, HypersonicSQL, Mckoi SQL, SAP DB, Interbase, Pointbase, Progress, FrontBase, Ingres, Informix, Firebird.
Podpora in dokumentacija
Uspešnost uvajanja nove tehnologije je precej pogojena z ustreznostjo dokumentacije in kakovostjo podpore. Hibernate je dobro dokumentiran. Poleg brezplačne literature je na voljo nekaj komercialnih knjig. Nekomercialna podpora Hibernatu je na voljo prek njihovega foruma. Komercialna podpora je možna prek podjetja JBoss, Inc.
Kaj prinaša Hibernate 3
Na Hibernatovi strani je na voljo že alfa različica Hibernata 3. Prinaša številne novosti, ki bodo prišle prav predvsem v primerih, ko smo s sedanjo različico naleteli na omejitve. Lahko bomo nadomestili vse generirane poizvedbe z ročno napisanimi. Tako bomo imeli možnost, da dostop do zbirke sami poljubno optimiziramo, kjer je treba. Prav tako bo mogoče realizirati funkcionalnosti, ki smo jih doslej zelo težko. Hibernate 3 bo prinesel tudi več možnosti pri izdelavi preslikave. Imel bo zmogljivejši poizvedovalni jezik HQL. Vključene bodo nove funkcionalnosti, ki jih prinaša Java 5.
Sklep
Strnimo poglavitne prednosti in slabosti Hibernata v primerjavi s klasičnim dostopom do zbirke podatkov.
Prednosti Hibernata:
Slabosti Hibernata:
Hibernate je najprimernejši za spletne programe in spletne storitve. Spletni programi imajo zelo pomembno značilnost - strežnik ne ve zanesljivo, kdaj je odjemalec z njim povezan. Povezava se praviloma konča s časovnim pretekom seje. Strežnik mora zato vzdrževati podatke, specifične za tega uporabnika, še dolgo po tem, ko jih ne potrebujemo več. Pri velikem številu uporabnikov pride to zelo do izraza, zato v pomnilniku ne smemo zadrževati večje količine podatkov, vezanih na enega uporabnika. Posledica je pogost dostop do zbirke podatkov. Sistem predpomnenja pride tu zelo do izraza in je skoraj nujno potreben.
Predmetno-relacijska preslikava je razmeroma kompleksen problem, ki so ga predhodne tehnologije podcenjevale. Mednje sodi tudi EJB. Hibernate problem rešuje zelo dobro. Močno se je približal idealu - predmetnemu delu s podatki ter avtomatizaciji branja in shranjevanja podatkov. Od programerja pa zahteva polno poznavanje njegovega delovanja in preverjanje poizvedb, ki jih generira. V nasprotnem primeru lahko dobimo performančno zelo neugodne rešitve. Pomembna slabost Hibernata je omejenost njegovega poizvedovalnega jezika HQL, kar pomeni, da moramo večino zahtevnejših poizvedb še vedno napisati v SQL.
Hibernate ponuja funkcionalnosti, ki naj bi jih ponudile predmetne zbirke podatkov. Predmetne zbirke podatkov se napovedujejo že vrsto let, vendar nič ne kaže, da bi se kmalu uveljavile v praksi. Večina relacijskih zbirk podatkov ponuja osnovno delo s predmeti. Ponuditi bi morale to, kar ponuja Hibernate - delo s predmeti in predmetni poizvedovalni jezik, ki vrača prave predmete v jeziku, ki ga uporabljamo. Poizvedovalni jezik bi moral biti zmogljivejši od Hibernatovega HQL, torej na ravni zmogljivosti SQL, a seveda predmeten: Hibernate in njemu sorodne rešitve so morda korak na prehodu v predmetne zbirke podatkov.
Predmetno-relacijska prinaša precej korenito spremembo pri dostopu do podatkov. Uporaba predmetnega modela podatkov programiranje zelo poenostavi in pohitri. Dodaten nivo preslikave pa tudi povečuje kompleksnost. Poleg tega Hibernate zahteva tudi veliko vloženega znanja. Hibernatove prednosti tako pridejo do izraza predvsem pri večjih projektih. Pri odločitvi za najustreznejšo rešitev moramo poudariti, da odločitev ni samostojna, temveč je odvisna od drugih arhitekturnih rešitev. Če delamo v okolju Jave, je Hibernate ena najresnejših alternativ.
Več o Hibernatu si lahko preberete na njihovi domači strani:
Imajo tudi zelo dobro obiskan forum:
Zelo koristno je obiskovati tudi njihov spletni dnevnik (blog), v katerem objavljajo sveže novice, članke in zvijače:
Primerjava Hibernata in ADO.NET
V taboru .NETa se predmetno-relacijska preslikava ni prijela tako dobro kakor v javi, kjer je na tem področju nešteto alternativ. Najbolj razširjen način dostopa do podatkov je tehnologija ADO.NET, ki je bila predstavljena skupaj z .NET-om. ADO.NET ne uporablja predmetno-relacijske preslikave, zato je podatkovni model še vedno relacijski. Njegova pomembna lastnost je tesna integracija z XML zapisom podatkov.
Razrede ADO.NET lahko v grobem razdelimo v dve skupini. Prva skupina so tako imenovani povezani razredi (Connected), ki skrbijo za dostop do zbirke podatkov. Drugo skupino sestavljajo odklopljeni razredi (Disconnected), ki jih uporabljamo za delo s podatki. Vmesnik med njima je DataAdapter, ki napolni predmete odklopljenih razredov s pomočjo predmetov povezanih razredov. DataAdapter v ta namen vsebuje poizvedbe za branje, spominjanje, vstavljanje in brisanje. S tako arhitekturo sta doseženi dve podobnosti s Hibernatom. Logika branja in shranjevanja je ločena od samih podatkov. Poleg tega taka arhitektura ne zahteva stalno aktivne povezave z zbirko podatkov. Omogočen je odklopljen način dela - povezava z zbirko se vzpostavi le v času branja in shranjevanja.
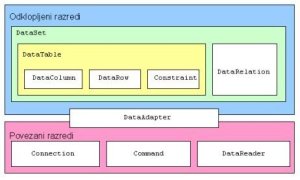
Arhitektura ADO.NET
ADO.NET ne ponuja predmetno-relacijske preslikave, zato smo prikrajšani za veliko prednosti, ki jih ta lahko ponudi. Najbolj pogrešamo predmetni model podatkov. Prikrajšani smo tudi za predpomnjenje, predmetni poizvedovalni jezik, branja podatkov po potrebi in neodvisnost od zbirke podatkov. To so bistvene pomanjkljivosti v primerjavi s Hibernatom.
Kot pomanjkljivost lahko navedemo še pomanjkanje močne tipizacije atributov. V ADO.NETu so atributi predstavljeni kot seznam stolpcev in do posameznega atributa pridemo s pomočjo številčnega ali tekstovnega ključa.
string nazivPartnerja = row[0];
string nazivPartnerja = row["Naziv"];
...
row[0] = nazivPartnerja;
row["Naziv"] = nazivPartnerja;
Kljub temu orodje Visual Studio omogoča generiranje razredov, ki imajo atribute močno tipizirane. Taka rešitev je sicer dobra, a slabša kot pri Hibernatu, ki že v osnovi ponuja take razrede brez generiranja kode.
Pomembna lastnost Hibernata je, da v času izvajanja generira vse potrebne poizvedbe SQL. ADO.NET ne pozna tako naprednega mehanizma generiranja poizvedb, kot ga omogoča Hibernate. Poizvedbe moramo v glavnem napisati sami. Kadar za branje uporabljamo zelo enostavno poizvedbo, lahko s pomočjo predmeta razreda CommandBuilder generiramo poizvedbe za vstavljanje, spreminjanje in brisanje. Generirane poizvedbe so neoptimizirane. Njegova uporaba se zato ne priporoča. Več kot generiranja preprostih poizvedb za shranjevanje CommandBuilder ne omogoča.
ADO.NET za branje in shranjevanje podatkov vedno uporablja poizvedbe iz predmeta DataAdapter. Torej poizvedbe ne optimizira za vsako branje ali shranjevanje. Nasprotno pa Hibernate optimizira svoje poizvedbe, tako da bere in zapisuje le nujno potrebne podatke.
ADO.NET je kljub vsemu bistveno naprednejši od tehnologij prejšnjega rodu, kot so ADO, JDBC, BDE. Ponuja prej omenjeno ločenost logike branja in shranjevanja od podatkov ter odklopljeni način dela. Omogočena je tudi povezava med tabelami (predmet DataReation). S tem lahko povezani tabeli obravnavamo kot celoto. Če je tabela A povezana s tabelo B, lahko iz zapisa tabele A uporabljamo povezane zapise v tabeli B in nasprotno.
ADO.NET prinaša tudi zelo pomembne prednosti v primerjavi s Hibernatom. To je poizvedovanje po podatkih v pomnilniku. Torej poizvedbe niso omejene le na podatke v zbirki podatkov. Omogočeno je, sicer zelo enostavno, a vseeno uporabno poizvedovanje po podatkih v pomnilniku. Podpira seštevanje in preštevanje stolpcev tabele ter filtriranje in sortiranje podatkov. Prednost v primerjavi s Hibernatom je tudi tesna integriranost z XML zapisom podatkom.
ADO.NET je v primerjavi s Hibernatom tudi zelo enostaven. Programer, ki mu delo z relacijsko zbirko podatkov ni tuje, ga hitro osvoji. Zato je ADO.NET bistveno bolj primeren za manjše projekte, kjer bi vpeljava posebnega nivoja predmetno-relacijske preslikave ter učenje tehnologije, kot je Hibernate, vzela preveč časa.
Microsoft se zaveda prednosti, ki jih prinaša predmetno-relacijska preslikava. Zato namerava skupaj z Longhornom predstaviti svojo rešitev, imenovano ObjectSpaces. Po prvotnih načrtih naj bi ObjectSpaces izšel že naslednjo leto skupaj z novim Visual Studiem 2005.






