Grafične kartice, ki to niso
Današnji superračunalniki imajo več milijonov jeder, že pisarniške delovne postaje pa več tisoč. Levji delež predstavljajo jedra v grafičnih čipih, ki že zdavnaj ne služijo več le izrisu slike, temveč so nujni sestavni del strojnega učenja. Izkazalo se je, da so ti čipi izjemno pripravni za izračune, ki ne potrebujejo visoke stopnje natančnosti, temveč predvsem ponavljanje in paralelizacijo. Najzmogljivejše grafične kartice ne le da nimajo več priklopa za monitor, temveč sploh niso več kartice, saj na plošče sedejo v podobna ležišča kot procesorji.

Nvidia H100 na novem modulu SXM5.
V nekih drugih časih so bile zmogljive grafične kartice rezervirane za zahtevne igralce iger, medtem ko so vsi ostali uporabniki računalnikov shajali s cenejšimi modeli, dostikrat celo integriranimi. Za brskanje po spletu, poganjanje urejevalnika besedil in tudi ogled kakšnega filma je pač zadostovala skoraj kakršnakoli. Današnji časi so drugačni v več pogledih.
Čeprav so čipi za grafični izris z nami že vsaj od 70. let, moramo nekje začeti. Primerna točka bodo legendarne kartice Voodoo podjetja 3dfx Interactive iz konca 90. let. Prvi izdelki so omogočali le pospeševanje izrisa 3D-grafike, zato so potrebovali še ločeno grafično kartico, že Voodoo Rush pa je leta 1997 prinesel kombinirano grafično kartico 2D/3D. Voodoo2 in Voodoo3 sta pisala zgodovino, kmalu zatem pa je podjetje klavrno končalo. Pretežni del intelektualne lastnine je odkupila Nvidia, preostanek 3dfx Interactive pa je šel v stečaj. A branža je bila rojena.
Redke matrike
Redka ali raztresena matrika (sparse matrix) ima za večino elementov ničle, neničelne vrednosti pa so predvsem na diagonali in v bližini. Redke matrike so zelo pomembne v znanosti in pri umetni inteligenci, saj nastopajo pri reševanju številnih pomembnih enačb ali treningih nevronskih mrež.
Novejše grafične kartice, pri Nvidii od modela A100 dalje, so prilagojene za hitrejše računanje z redkimi matrikami. Jedra v A100 redke matrike stisnejo v manjše, a gostejše, ki so bolj obvladljive, računi pa zato hitrejši in varčnejši. Nvidia v specifikacijah zato posebej navaja hitrost kartic pri normalnih izračunih in nad redkimi matrikami.
Prve grafične kartice so imele jasen namen – izrisovati grafiko, od koder izhaja tudi njihova kratica GPU (graphics processing unit). Moderna era GPU se je začela z GeForceom 256 leta 1999, ki ga je proizvajalka Nvidia rada označevala kot prvi GPU, saj je podpiral transformacije, osvetljevanje in izris trikotnikov, vse s hitrostjo najmanj 10 milijonov večkotnikov na sekundo. Za našo zgodbo pa je pomembnejši GeForce 3, ki je leta 2001 uvedel programljive osenčevalnike (pixel and vertex shaders) in računanje s plavajočo vejico.
GPGPU
Za neizgovorljivo kratico se skriva general purpose graphics processing unit, kakor imenujemo vsak grafični čip (GPU), ki zna početi še kaj drugega. Zamisel je v resnici že precej stara, vsaj okrnjena izvedba pa tudi. Že v 80. letih je primitivna igra Conway's Game of Life uporabljala tokovni procesor (stream processor) za izvajanje logičnih operacij nad vektorji.
Ko pa so GPU dobili programirljive dele, je področje začelo brsteti. Že leta 1999 je Hoff na Nvidijini RIVA TNT2 izračunaval Voronoijeve diagrame. Dve leti pozneje sta Larsen in McAllister izvedla prvo množenje matrik v osmih bitih, Rumpf in Strzodka pa reševala parcialne diferencialne enačbe. GeForce 3 je že znal simulirati vrenje tekočine, tok tekočin in difuzijo, a je bil zaradi nizke ločljivosti – podpiral je le plavajočo vejico enkratne natančnosti – precej nenatančen. Ironično so se ravno izračuni nizke stopnje natančnosti dve desetletji pozneje vrnili skozi velika vrata.
Kar so ljudje počeli tedaj, je bilo vsaj konceptualno sorodno današnji uporabi grafičnih procesorjev, a tega še niso opisovali z enotnim imenom. Mark Harris, tedaj še doktorski študent na Univerzi Severne Karoline v Chapel Hillu, zdaj pa že dve desetletji Nvidijin inženir, je leta 2002 skoval termin GPGPU in leto pozneje ustanovil spletno stran gpgpu.org. Kasneje je doktoriral iz realističnih simulacij oblakov na GPU, ki so vključevale dinamikov fluidov (Navier-Stokesove enačbe), termodinamiko, kondenzacijo in izhlapevanje ter sipanje svetlobe na oblakih.
Leta 2007 je Nvidia izdala znamenito knjižnico CUDA (Compute Unified Device Architecture), ki je GPGPU približala sleherniku. Grafični procesorji so še posebej primerni za operacije, ki niso preveč zahtevne, a se ponavljajo in ponavljajo, hkrati pa so medsebojno neodvisne, zato se lahko odlično paralelizirajo. Pisanje programov, ki to izkoriščajo, se je bistveno poenostavilo ravno s knjižnico CUDA, ki je sprva podpirala C, C++ in Fortran (neodvisni vmesniki pa še precej več jezikov) in omogočala enostavno uporabo grafičnega procesorja v paralelnih delih kode. Pri Monitorju smo že pred desetletjem preizkusili prav to (Čuda iz Nvidie, Monitor 02/14) in za pripravo preizkusne kode s povprečnim znanjem Fortrana potrebovali zgolj kakšno popoldne. CUDA seveda ni bila prva, ki je omogočila uporabo grafičnih kartic za raznovrstne izračune, je pa bistveno znižala letvico za vstop. A to so bili neki drugi časi, ko je bila umetna inteligenca še globoko v raziskovalnih laboratorijih in ne na pisalnih mizah ali v silicijevih možganih slehernika.
Nekoč in danes
Od skromnih začetkov, ko je bil GPGPU namenjen le igranju raziskovalcev, kasneje pa veščim programerjem in zanesenjakom, je do danes postal nepogrešljiv del računalniške industrije. Najzmogljivejši superračunalnik na svetu Frontier, ki ima 8,9 milijona jeder in zmore 1100 PFLOP/s, v resnici sestavlja 600.000 jeder v procesorjih AMD Epyc 7453 in 8,3 milijona grafičnih jeder v grafičnih čipih AMD Radeon Instinct MI250X. Podobno velja tudi za druge najzmogljivejše superračunalnike, vključno s slovensko Vego v Mariboru, ki ima 240 Nvidijinih »kartic« A100. Grafični čipi, ki se že zdavnaj ne uporabljajo več le za poganjanje igre Crysis, so neobhodni sestavni del modernih sistemov.
Podatkovni tipi
Števila v računalništvu zapisujemo v različnih tipih, ki zaradi različne velikosti v pomnilniku omogočajo različno natančnost. Enojna natančnost zapisa s plavajočo vejico ali float32 (tudi FP32) zahteva 32 bitov, kjer se en bit porabi za predznak, osem za eksponent in 23 za mantiso. To je veliko, ni pa neomejeno mnogo, zato lahko števila zapisujemo z omejeno natančnostjo, ki je odvisna od magnitude. V tem zapisu računalnik ne more shraniti vrednosti 0,1, temveč je to v binarni obliki 00111101110011001100110011001101, v človeški obliki pa 0,100000001490116119384765625. To se zdi neznatna razlika, a že pri milijonu se namesto 1.000.000,1 shrani 1.000.000,125.
Števila pa lahko zapisujemo tudi drugače. Cela števila so zapisana točno tako (integer), tenzorska jedra pa še hitreje delujejo s posebnimi manj natančnimi tipi. Tip tensorfloat32 ima bit za predznak, osem bitov za eksponent in le 10 bitov za mantiso. To pomeni, da bodo števila shranjena še bolj zaokroženo, a za treniranje umetne inteligence je to dovolj, delovanje pa je bistveno pohitreno. Vrednosti niso izbrane naključno, saj klasični float16 uporablja mantiso z 10 biti in pet bitov za eksponent. Včasih pa potrebujemo večjo natančnost, na primer dvojno (float64). Grafična jedra zmorejo tudi to, a počasneje.
CUDA ni več edini način za vstop v ta segment, saj se je področje zelo razvilo. Obstajajo številne knjižnice, denimo AmgX, cuDNN, OpenCV, Thrust in cuBLAS, ki izkoriščajo GPGPU. Z OpenACC se pišejo programi za heterogene arhitekture, ki izkoriščajo CPU in GPU, podprti jeziki pa so mnogoteri, denimo C in C++, Fortran, Python, Java, Matlab in tudi R. Orodja programerjem omogočajo bistveno lažje delo s strojno opremo, saj lahko uporabljajo koncept enotnega pomnilnika namesto ločenega sistemskega in grafičnega.
Povpraševanje po grafičnih čipih so spodbudile kriptovalute, ki jih je bilo mogoče bistveno učinkoviteje rudariti na GPU kakor na centralnih procesorjih. Nenadoma je prodaja najdražjih grafičnih čipov poskočila, pri čemer so imele klasične igričarske grafične kartice najugodnejše razmerje med ceno in zmogljivostjo. Situacija je v preteklih letih eskalirala do te mere, da so se kartice prodajale bistveno dražje od priporočene maloprodajne cene proizvajalca (MSRP), dobavni roki pa so poleteli v nebo. Za njihovo uporabo ni bilo treba znati ničesar, saj je vsa koda obstajala na internetu – potrebovali smo le poceni električno energijo, dobro hlajenje in internetni priključek. Položaj na trgu se je normaliziral šele lani, ko je ether prešel z rudarjenja na drugačno potrjevanje blokov, kasneje pa se je zlomil še kriptotrg. Grafične kartice so ponovno postale dostopne tistim, ki so jim resnično namenjene, torej igralcem. Seveda pa kriptorudarji nikoli niso kupovali kartic, o katerih pišemo v tokratnem prispevku, ker te stanejo več (deset) tisoč dolarjev in so namenjene podatkovnim centrom ter superračunalnikom.

Mark Harris, izumitelj termina GPGPU, je doktoriral iz simulacij oblakov.
A naivno bi bilo sklepati, da so ti dandanes glavni ali celo edini kupci. Še en močan pospešek je GPGPU doživel z razvojem strojnega učenja in umetne inteligence. Za njen trening potrebujemo ogromno računske moči, ki jo najlaže zagotavljajo poceni masivno paralelni sistemi, kar so prav grafični čipi. Nevronska mreža pri treningu vzpostavlja ponderje za posamezne povezave, kar je računsko najzahtevnejši del. Matematično gledano gre za množenje matrik, kar je kot nalašč za grafične procesorje, ki ne obupajo niti ob milijardah parametrov. Vsi izračuni namreč tečejo hkrati pa še dostop do hitrega pomnilnika ob GPU imajo. Danes, ko je umetna inteligenca dostopna na vsakem koraku, so grafični čipi še pomembnejši. Proizvajalci so povpraševanju radi sledili.
Namenske kartice
Lani jeseni je Nvidia predstavila novi čip H100 Tensor Core GPU, ki je zgrajen v 4-nanometrski tehnologiji TSMC in ima osupljivih 80 milijard tranzistorjev. Kratica H izvira iz imena arhitekture (Grace) Hopper, ki je že deveta Nvidijina inačica arhitekture za podatkovne centre. Po enaki logiki se je njena predhodnica imenovala A100, ker se je arhitekturi reklo Ampere. Nvidia sicer že od leta 1998 arhitekture poimenuje po znanstvenikih, začenši s Fahrenheitom.


Grafični čipi so na voljo v obliki kartic ali formatu za strežnike.
Nvidia je v arhitekturo Volta, ki je izšla leta 2017, vgradila jedra Tensor Core. Gre za namenske pospeševalnike za umetno inteligenco, ki grafične čipe bolje prilagodijo za uporabo pri strojnem učenju in jih pospešijo pri učenju nevronskih mrež. Tipične različice, ki se uporabljajo za ta namen, vsebujejo več milijard tranzistorjev MOSFET, ki omogočajo hitro izvajanje vzporednih izračunov, pri katerih natančnost ni najpomembnejša odlika. Odtlej so v vseh nadaljnjih arhitekturah (Turing, Ampere, Hopper) tenzorska jedra pomemben sestavni del (več v nadaljevanju).
Intel je poskušal drugače
Trg GPGPU nesporno obvladujeta Nvidia in AMD, zato je moral Intel poskusiti drugače. Medtem ko so grafična jedra arhitekturo drugačna od centralnih procesorjev, z drugačnimi ukazi in zahtevajo prilagojeno kodo oziroma prevajalnike, se je Intel odločil vztrajati pri preizkušeni x86. Če bi na eno kartico stlačili dovolj teh procesorjev in jih pohitrili, bi na njih lahko paralelna koda tekla z minimalnimi spremembami.
Leta 2010 so predstavili koncept soprocesorjev na karticah Xeon Phi. Uporabljal je nekaj pristopov iz sveta grafičnih kartic, denimo veliko število čipov. Sprva je kazalo odlično, saj je že leta 2013 tedaj najhitrejši superračunalnik na svetu Tianhe-2 uporabljal 48.000 Intel Xeon Phi iz druge generacije (Knights Landing), modele 31S1P, ki so imeli po 57 jeder. Štiri leta pozneje je približno desetina superračunalnikov z lestvice Top500 uporabljala Xeon Phi.
Približno istočasno kot je Nvidia predstavila tenzorska jedra, torej leta 2017, je tudi Intel izdal novo generacijo Xeon Phi (Knights Mill), ki so bili specializirani za globoko učenje. V praksi je to pomenilo, da so pohitrili računanje v enojni natančnosti in spremenljivi natančnosti, sicer pa so bili arhitekturno enaki kot Knights Landing.
A Xeoni Phi so še vedno imeli precej manj jeder, česar niso mogli nadomestiti vsi ostali ukrepi (novi ukazi AVX512-VNNI, optimizacije in nove matematične knjižnice, uporaba podatkovnega tipa bf16, specializirani prevajalniki). Leta 2020 se je zato Intel odločil, da družino Xeon Phi upokoji. K temu so pripomogle težave z 10-nanometrsko tehnologijo proizvodnje, nedoseganje kartic AMD in Nvidie, pomanjkanje orodij za uporabo pri globokem učenju (tu Nvidia in AMD blestita) ter z vsem tem povezano slabo povpraševanje. V resnici je presenečenje, da se je to zgodilo šele leta 2020, saj so bile težave očitne že vsaj štiri leta prej.
To pa ne pomeni, da je Intel povsem zapustil trg grafičnih čipov. Nasprotno. Nova družina se imenuje Xe. Njen višji razred je serija Arc, ki je namenjena igralcem iger, medtem ko je vstopni model Xe Graphics. Glavni Intelov adut je cena, saj so jih tudi predstavili z motom, da so grafične kartice po nepotrebnem postale zelo drage. Tudi na Arcu je mogoče povsem spodobno poganjati globoko učenje in podobno, niso pa te kartice izključno za ta namen, dasiravno imajo tudi tenzorska jedra.
Intel je zato lani končno zakorakal na trg GPGPU z novim Ponte Vecchio Xe-HPC, ki so ga predstavili jeseni. Ob izidu so se pohvalili, da je hitrejši od A100, resda v zelo ozkem naboru testov, a se spodobno kosa tudi s H100, zlasti zaradi ogromnega predpomnilnika in še cenejši ter lažje dobavljiv je.
Zmogljivosti čipa H100 si bomo najbolje predstavljali, če pogledamo specifikacije. Na 814 kvadratnih milimetrih (preračunamo lahko, da je to ploščica površine okoli 3 × 3 cm) ima 80 milijard tranzistorjev, ki tvorijo najrazličnejše komponente. Preberemo lahko, da jo sestavlja osem GPC (graphics processing cluster), kakor imenujemo samostojne enote za izračunavanje, rasterizacijo, osenčevanje, teksturiranje. V vsaki je devet TPC (texture processing cluster), ki imajo po dve SM (streaming multiprocessor) – teh je torej 144.
Vsak SM ima 128 jeder CUDA za računanje v enojni natančnosti (float32), torej jih je na kartici 18.432. Poleg tega ima vsak SM še štiri tenzorska jedra četrte generacije (skupno 576). S pomnilnikom komunicira dvanajst 512-bitnih krmilnikov, drugonivojskega predpomnilnika pa je 60 MB. Te številke so nekoliko drugačne pri različici za ležišče SXM5 (več v nadaljevanju). Komunikacija s svetom poteka prek NVLinka ali vodila PCIe pete generacije.
V primerjavi s predhodniki prinaša H100 precej novosti. Tenzorska jedra so do šestkrat hitrejša kot na A100, novi ukazi DPX pohitrijo nekatere operacije dinamičnega programiranja, operacije v enojni in dvojni natančnosti (float32 in float64) so dvakrat hitrejše, distribuirani deljeni pomnilnik omogočajo direktno komunikacijo med SM, pomnilniški podsistem HBM3 je hitrejši, več je predpomnilnika, podprta sta PCIe in NVlink nove generacije in tako naprej. Skratka, kartica nima le več hitrejših jeder, temveč je konceptualno posodobljena. A kaj sploh so vsa ta jedra?
Jedra
Kartica Nvidia Tesla V100 je leta 2017 prinesla novost z imenom tenzorska jedra (tensor cores), ki so do danes postala stalnica vseh zmogljivih kartic. Do vključno generacije Pascal so imele Nvidijine kartice jedra CUDA (Compute Unified Device Architecture), ki so bila sorodna centralnim procesorjem. Delovala so s taktom kartice in opravljala eno operacijo na cikel, kar je bilo ozko grlo pri računski uporabi kartic, denimo za urjenje nevronskih mrež.
Za to početje ni nujno potrebno, da izračuni tečejo z visoko stopnjo natančnosti, temveč je pomembneje, da so hitri. Seveda ne moremo računalniku reči, naj približno zmnoži dve matriki, lahko pa uporabljamo podatkovne tipe, ki zasedejo manj prostora (več v okvirju). Pri učenju z mešano natančnostjo (mixed precision training) se uporabljajo manj natančni podatkovni tipi (na primer float16), ker so operacije z njimi manj zahtevne.
Tenzorska jedra so namenjena točno temu, torej množenju in seštevanju matrik z manj natančnimi podatkovnimi tipi. V100 je podpiral le float16, kasnejše arhitekture pa še dodatne tipe. V H100 tenzorska jedra razumejo še float8, float64, int8, tensorfloat32 in bfloat16. V specifikacijah bomo našli deklarirano hitrost operacij nad vsakim tipom spremenljivk. Za float64 je to lahko 26 TFLOP/s, za float8 pa kar 3026 TFLOP/s. Z manjšimi podatkovnimi tipi lahko tenzorska jedra v enem ciklu opravijo več operacij. Pohitritve zaradi uporabe tenzorskih jeder so izjemne. Tesla V100 je bila pri urjenju nevronskih mrež skoraj 10-krat hitrejša od P100, če so programerji pravilno uporabljali tenzorska jedra.
Pozoren bralec bo opazil, da nismo omenili jeder RT (ray tracing). Razlog je preprost: H100 in A100 teh jeder nimata, ker nista namenjena izrisovanju slike, temveč opravljanju računskih operacij. Jedra RT so specializirana vezja za pospeševanje sledenja žarkov. To je drugačen način izrisovanja 3D-kadrov od običajne rasterizacije, ki ga uporabljajo Nvdijine kartice RTX (Ray Tracing Texel eXtreme). Svojčas je bilo sledenje žarkov uporabno le, kjer čas ni bil ovira, recimo pri pripravi risank, od leta 2018 pa so komercialne kartice dovolj zmogljive, da to izvajajo v realnem času. H100 in A100 iz istih razlogov nimata priključkov za monitorje, strojne podpore za enkodiranje videa (NVENC) in podobno.
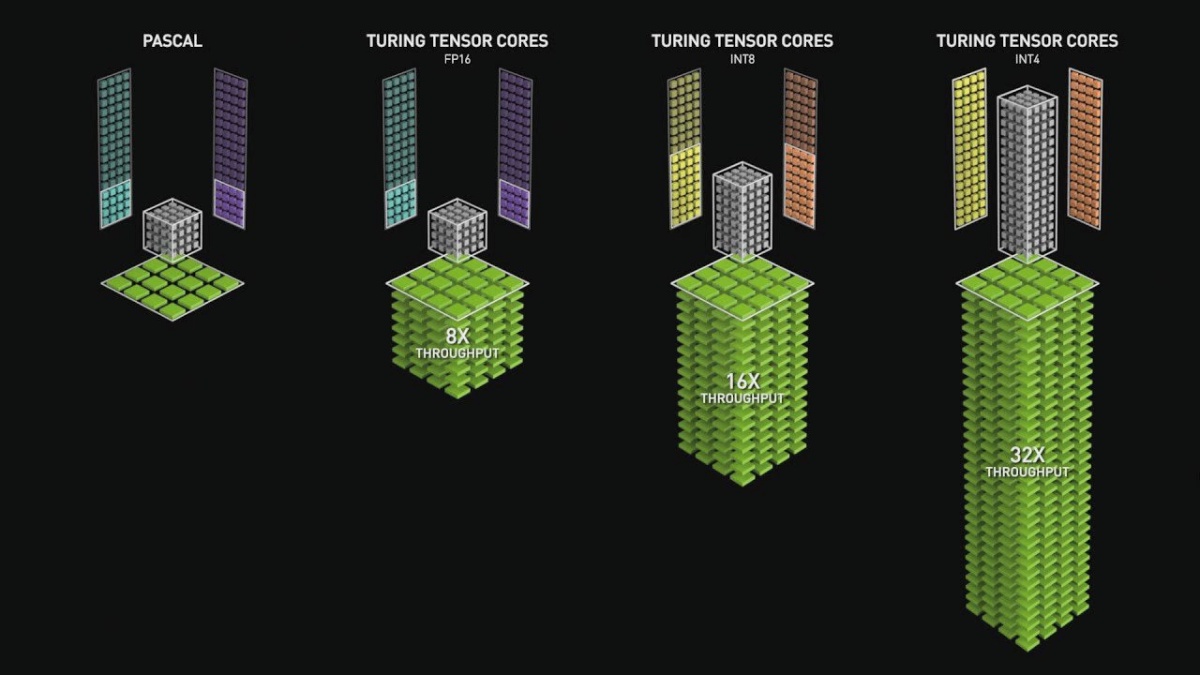
Tenzorska jedra omogočajo pohitritev operacij z matrikami v manjši natančnosti.
Ko PCIe ni več dovolj
Nvidia je tudi že precej kmalu ugotovila, da so klasični priključki PCIe ozko grlo pri komunikaciji z najhitrejšimi grafičnimi karticami, zato je ustvarila svojega. To se najlepše pokaže pri deklariranih zmogljivostih nove H100, ki ima prek PCIe kapaciteto za dostop do pomnilnika 2 TB/s, prek SXM pa 3,35 TB/s. Podobno pri izračunih s plavajočo vejico dvojne natančnosti (FP64) prek PCIe zmore 26 TFLOP/s, prek SXM pa 34 TFLOP/s.
Ležišče SXM so uvedli že v generaciji Pascal (P100) leta 2016 in je do danes napredovalo do različice SXM5. V primerjavi s klasičnimi PCIe omogoča večjo prepustnost pri prenosu podatkov, zagotavlja večje moči pri napajanju in enostavnejši priklop več modulov. Videti so podobno kot ležišča za procesorje in ne za grafične kartice. Plošče s podporo SXM imajo običajno štiri ali osem ležišč in podporo za NVLink za hitro komunikacijo med GPU. S tem se izognejo ozkim grlom, kot je PCIe ali centralni procesor. Za primerjavo: PCIe 5.0 lahko doseže 64 GB/s v različici x16, medtem ko H100 z 18 štirikanalnimi vodili NVlink brez težave prenese 900 GB/s.
Poleg čisto praktičnih prednosti pri nameščanju GPU v tej obliki lahko ležišče zagotavlja več električne energije. H100 v tej obliki posrka 700 W energije, hkrati pa je v takšnem formatu namestitev hladilnih sistemov lažja. Zaradi naštetega imajo SXM zlasti namenske strežniške plošče, ki se uporabljajo v superračunalnikih.
Odgovor AMD
AMD je serijo FirePro S upokojil leta 2016 in leto pozneje zagnal družino Radeon Instinct, ki se zadnji dve leti imenuje le še Instinct. Prvi modeli MI6 (Polaris 10), MI8 (Fiji) in MI25 (Vega 10) so izšli slabo leto po Nvidijinem P100. Tedaj so močno pretresli trg, na katerem se je zdelo, da bo Nvidia skoraj monopolna, Intel pa ji bo s pristopom jeder CPU (Xeon Phi) poskušal odškrniti kakšen kos kolača. AMD je z Radeon Instinctom pokazal, da je dostojen nasprotnik. Tudi zato je bil Nvidijin odgovor konec leta 2017 v obliki serije Volta silovit – med drugim tudi z vključitvijo omenjenih tenzorskih jeder. AMD je leto pozneje izdal MI50 in MI60 (oba na arhitekturi Vega 20), leta 2020 MI100 (Arcturus) in nato še MI210, MI250 ter MI250X (Aldebaran).

Grafični čip MI250X
Pred petimi leti se je zdelo, da bo prihodnost monolitna. Nvidia je s tenzorskimi jedri v generaciji Volta zavladala na trgu, Intelovi Xeoni Phi so bili nekonkurenčni, AMD pa je dober odgovor še iskal. Leta 2018 je imel na lestvici najhitrejših superračunalnikov Top500 šest predstavnikov, izmed katerih grafičnih čipov AMD ni imel nobeden. A AMD je uspelo najti odgovor. Na aktualni lestvici najhitrejših superračunalnikov Top500 jih ima že petina njegove čipe (ne le grafičnih, ampak večinoma CPU), kar je 38 odstotkov več leto pred tem. Tudi najzmogljivejši Frontier jih uporablja, in to oboje (CPU in GPU). Na seznamu Green500, kjer so razvrščeni po potratnosti, jih ima med najboljšimi 20 kar tri četrtine čipe AMD.
Poglejmo AMD Instinct MI250X, ki je ta hip najzmogljivejši čip tega proizvajalca. Zgrajen je v 6-nanometrski litografiji FinFET podjetja TSMC, ima 220 računskih enot, ki imajo po štiri TMU (texture mapping units), vsak pa potem po 16 osenčevalnih enot oziroma tokovnih procesorjev (skupaj torej 14.080). Tiktaka s 1.700 MHz, s pomnilnikom pa komunicira po 8.192-bitnem vodilu (prepustnost 3,2 GB/s). To je že na papirju (95,7 TFLOP/s za fp32) več od Nvidijinega paradnega konja H100 in tudi praksa to potrjuje. MI250X je trenutno najhitrejša beštija, ki je na voljo.
Prihodnost bo združena
Čeprav je MI250X najhitrejši čip, je star že dobro leto. AMD je na letošnjem sejmu CES že pokazal, kaj bo prinesel naslednik MI300, ki bo imel neverjetnih 146 milijard tranzistorjev, 24 procesorskih jeder, 128 GB pomnilnika in grafična jedra. To bo njihov prvi poskus zgraditi pravi APU (accelerated processing unit) za uporabo v podatkovnih centrih. APU imajo v istem modulu integrirana procesna (CPU) in grafična jedra (GPU). MI300 naj bi imel več čipletov, ki bodo zgrajeni v TSMC-jevem 5-nanometrskem postopku v treh dimenzijah. V istem kosu silicija bo tudi pomnilnik HBM. S tem bo odpadlo ločeno sestavljanje, kot so Epyci in Instincti v Frontierju. O podrobnostih se lahko za zdaj le sprašujemo, obljubljajo pa osemkratno pohitritev (TFLOP/s glede na porabo v vatih) v primerjavi z MI250X in petkrat večjo hitrost pri treningu nevronskih mrež.

Najzmogljivejši superračunalnik na svetu Frontier uporablja procesorske čipe AMD Epyc in grafične čipe MI250X.
Na drugi strani ne počiva niti Nvidia, ki ima podobne načrte. Težko pričakovana novost tega leta bodo superčipi Grace Hopper, ki bodo združevali procesorje Grace in grafične čipe Hopper (GH100) v enem modulu s povezavo s prepustnostjo 900 GB/s. Imeli bodo še 512 MB hitrega LPDDR5X in 80 GB počasnejšega pomnilnika HBM3. Deklarirana poraba celotnega modula je 1.000 W. Pričakujemo jih šele v drugi polovici leta, saj mora Nvidia najprej izdati procesorje Grace. Ti bodo zgrajeni na arhitekturi ARM, kar dokazuje Nvidijino stavo na varčnost.
Za konec poglejmo še Intel, ki je zadnji spoznal uporabnost GPGPU. Konec leta so napovedali preimenovanje novih izdelkov, ki bodo vsi del serije Max. Novi procesorji Xeon z delovnim imenom Sapphire Rapids bodo Intel Xeon CPU Max Series, novi grafični čipi z delovnim imenom Ponte Vecchio pa Intel Data Center GPU Max Series. Od teh Max Series 1100 GPU sede v PCIe, Max Series 1350 ali 1550 GPU pa v OAM, so povedali na predstavitvi januarja letos. Ponte Vecchio bodo letos nadomestili čipi Rialto Bridge. V nekoliko bolj oddaljeni prihodnosti, predvidoma prihodnje leto, bodo predstavili module z imenom Falcon Shores, ki bodo združevali CPU in GPU del.
Prihodnost je torej videti bistveno bolj optimistično kot pred petimi leti. Namesto monopola smo dobili zdravo konkurenco treh močnih igralcev, ki inovirajo in v nekaterih primerih celo prehitevajo Moorov zakon. Zdi se, da bo pri razvoju umetne inteligence vsaj za zdaj ozko grlo programski del in ne strojni.