Opice s kalkulatorji
Če v Google iskalnik slik (Google Images) vpišete frazo »monkey with a calculator« (opica s kalkulatorjem, op. p.) vas bo na prvi strani zadetkov med slikami opic s kalkulatorji presenetila slika temnopolte deklice, ki v rokah drži kalkulator. Nihče ne ve, kako se je znašla med rezultati iskanja.
Primer, na katerega so raziskovalci Google prvič opozorili leta 2016, že več let služi kot eden bolj plastičnih primerov problemov algoritemskega urejanja sveta okrog nas. Google namreč pri izračunavanju zadetkov, ki se ujemajo s pojmi uporabniškega iskanja, uporablja zapletene algoritemske enačbe, ki so poslovna skrivnost, a hkrati tudi za Googlove razvijalce zaradi svoje kompleksnosti predstavljajo črno škatlo, v katero nimajo popolnega vpogleda.
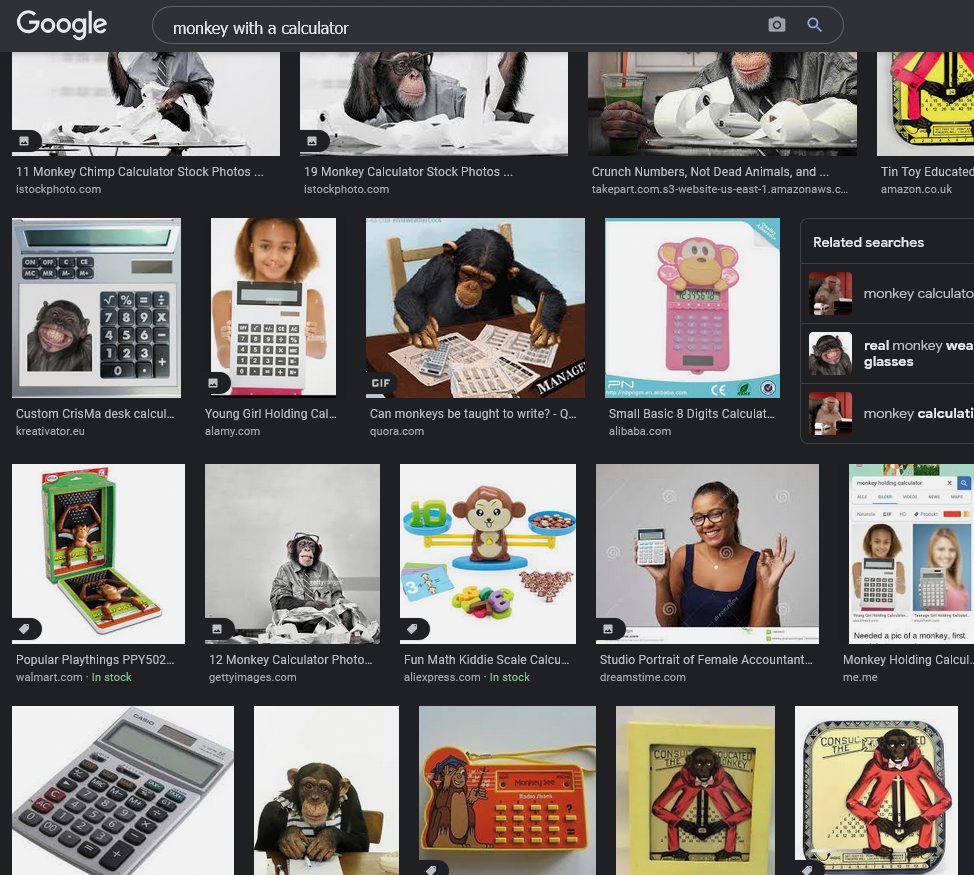
Še Google ne ve, zakaj se med slikami opic pojavljajo slike temnopoltih deklet. Menda je kriv algoritem.
Nemška nevladna organizacija Algorithmwatch, ki v Evropski uniji predstavlja eno vodilnih organizacij na področju kritične analize in beleženja algoritemskih praks, v svojih letnih poročilih Automating society (Avtomatizacija družbe, op. p.) že več let opozarja na nebrzdano in problematično uvajanje algoritmov na različna področja našega družabnega in zasebnega življenja, ki ima vedno bolj konkretne in vedno bolj negativne posledice za našo družbo.
Nam je zavarovalnica dvignila premijo zaradi algoritemskega pregleda naših objav na družabnih omrežjih ali je premija višja zaradi inflacije? Ne gre za teoretični primer, leta 2020 je Zavarovalnica Triglav že iskala ustrezno programsko rešitev.
Čeprav je opica s kalkulatorjem komičen, a izredno plastičen primer problematične uporabe algoritemskega urednikovanja vsebin, lahko identičen način neučinkovite rabe algoritmov za reševanje človeških vprašanj in izzivov najdemo na veliko pomembnejših področjih, kot so javno zdravje, socialna politika, kriminaliteta. S pomembno razliko – napaka pri iskanju, ki prikaže sliko opice s kalkulatorjem, nas lahko užali, razburi oziroma nasmeji, napaka na področju podeljevanja socialne pomoči, odmerjanja odmerka zdravil oziroma povezovanja naše identitete s kriminalcem pa je lahko usodna.
Božji kompleks algoritmov
Približno ob istem času, ko je Googlov algoritem temnopolto deklico »videl« kot opico, je avtor, pravnik in raziskovalec Frank Pasquale v knjigi z istoimenskim naslovom definiral družbo črne škatle (Black Box Society, op. p.) in opozoril na vedno večje uporabo algoritemskih sistemov, ki povezujejo različne podatkovne točke, vezane na posameznika. Od rezultatov iskanja, objav na družabnih omrežjih, geolokacijskih podatkov, elektronskih sporočil do podatkov o spletnih nakupih – algoritmi vse bolj pomagajo pri sprejemanju odločitev, ki imajo pomemben vpliv na posameznikovo življenje.

Algoritmi so orodja, ki jih velikokrat ne razumejo niti njihovi proizvajalci.
Banke z algoritmi ocenjujejo kreditno sposobnost posameznic in posameznikov, zavarovalnice ocenjujejo zdravstvena in druga tveganja, ki bi lahko vplivala na višino zavarovalne premije, trgovine na podlagi naših nakupov, zabeleženih na karticah zvestobe, optimizirajo oglasne nagovore. Pasquale svari, da se vse to dogaja v ozadju in na prikrit način, tako da človek nikoli ni seznanjen z načinom sprejema neke odločitve. Nam je zavarovalnica dvignila premijo zaradi algoritemskega pregleda naših objav na družabnih omrežjih, kjer imamo objavljenih več slik s »plezarij v Grčiji«, ki so pospremljene z objavami, na katerih pijemo alkoholne pijače, ali je premija višja zaradi inflacije?
Ne gre za teoretični primer, leta 2020 je Zavarovalnica Triglav na hackatonu iskala programsko rešitev, s katero bi lahko identificirala stranko na več različnih komunikacijskih kanalih. V opisu izziva smo lahko prebrali, da »to lahko dosežemo z ustreznim povezovanjem naših obstoječih strank s profili, ki jih imajo le-te na družabnih omrežjih, kot so npr. Twitter, Facebook, Instagram, LinkedIn in drugi. Ob pomoči povezav z zunanjimi viri, kot so družabna omrežja, bomo na enem mestu še obogatili podatke naših strank in tako imeli še boljši vpogled na stranko kot celoto.«
In če mislite, da slovenske zavarovalnice na tem področju orjejo algoritemsko ledino, se motite. Ameriški zavarovalniški sektor že več let uporablja algoritemsko odločanje pri ocenjevanju tveganj, pri tem pa raziskovalci opozarjajo na več problemov rasističnega odločanja, problematičnih odločitev in tveganj, ki jih je izredno težko odpraviti oziroma premostiti.
Zavarovalnice pa niso edino področje, kjer se dogajajo take naravne katastrofe. Te dni razburja podatkovni škandal iz Nizozemske, kjer je davčna uprava leta 2012 z algoritmom »odkrivala« zlorabe socialne pomoči, v resnici pa je več socialno šibkih družin država kaznovala z več deset tisoč evri kazni, ker naj bi pri njih algoritem zaznal zlorabe socialne pomoči. Rezultat? Družine so morale razglasiti osebni bankrot, več tisoč otrok je končalo v rejniških družinah, zaradi davčnega dolga, »izračunanega« ob pomoči algoritmov, je več ljudi naredilo samomor. Edini problem? Zlorab socialne pomoči ni bilo.
Nizozemski informacijski pooblaščenec je davčno upravo kaznoval s 3,7 milijona evrov kazni po zakonodaji GDPR, ker je davčna uprava več let neupravičeno in brez pravne podlage zbirala in obdelovala podatke o državljankah in državljanih. Nato ji je naložil še 2,7 milijona evrov kazni za »nezakonito in diskriminatorno« uporabo podatkov ljudi z dvojnim državljanstvom. Kazni za krivične algoritme nimamo. Zakonodaja namreč za zdaj velja samo za ljudi, ne za stroje.
Na Nizozemskem je davčna uprava leta 2012 z algoritmom »odkrivala« zlorabe socialne pomoči. Družine so morale razglasiti osebni bankrot, več tisoč otrok je končalo v rejniških družinah, zaradi davčnega dolga, »izračunanega« ob pomoči algoritmov, je več ljudi naredilo samomor. Zlorab socialne pomoči v resnici ni bilo.
Pa tudi to ni edino področje, kjer lahko z grozo opazujemo vedno večje katastrofe, ki izvirajo iz avtomatiziranega urednikovanja vsebin in reševanja družbenih problemov. Pandemija koronavirusa je na področju širjenja laži in dezinformacij na široko razkrila pomanjkljivosti algoritmov družabnega spleta in spletnih iskalnikov, ki so ljudem stregli s popolnimi nesmisli ter tako pomagali pri prepričevanju, da je koronavirus posledica globalne zarote kuščarjev, ki jo širijo ob pomoči telefonov 5G. Kaj se torej dogaja?
Kako algoritem naredi napako
V računalniški znanosti je algoritem skupek navodil, ki temeljijo na matematičnemu modelu, s katerim programer stroju pove, kako naj izvede neki izračun. Matematični model je ponavadi sestavljen iz analize predhodnih odločitev in uporabe posameznih faktorjev, ki so vplivali na njih. Algoritem lahko nato avtomatizira sprejemanje odločitev, s tem pa lahko hitro in »učinkovito« obdela velike količine podatkov. Več kot ima algoritem na voljo podatkov, »boljše« so ponavadi odločitve.
Prvi problem je kakovost podatkov, na katerih programerji učijo algoritme. V ameriškem zdravstvenem sistemu so algoritmi izpeljali »napačne« odločitve, ker so bili podatki, na katerih so jih »učili«, napačni. Napačni v smislu, da so vsebovali podatke o belopoltih bolnikih, medtem ko so manjkale kartoteke temnopoltih, hispanskih in drugih. Zakaj? Zaradi nedosegljivosti storitev ameriškega zdravstvenega sistema, ki ni dostopen vsem državljankam in državljanom. Ko so torej temnopoltega bolnika postavili pred algoritem, ki naj bi izračunal pravilno dozo zdravil, ga je ta zaradi »napačne« rase skoraj ubil.
Na podoben način je »spodletelo« nizozemskemu algoritmu za ugotavljanje davčnih prevar. Algoritem so »naučili«, da so pripadniki manjšin bolj nagnjeni h kriminalu. Kako so prišli do te ugotovitve? Iz podatkov nizozemske policije. Kako je policija zbrala te podatke? Na podlagi aretacij. Kako je izvedla aretacije? Več raziskav iz vsega sveta opozarja, da se policisti drugače obnašajo do različnih osumljencev, odvisno od starosti, spola, rase osumljenca. Skratka, napake policijskih podatkovnih zbirk so se prenesle v podatkovne zbire davčne uprave, ki je nato napačne sklepe uporabila za ugotavljanje neobstoječih prevar.

Za algoritmi se skoraj vedno skrivajo slabo plačani sužnji.
Identične težave lahko vidimo tudi na področju avtomatiziranega biometričnega nadzora, kjer se algoritmi učijo na zbirkah obrazov problematičnega izvora. Problematičnega v smislu, da so zbirke pomanjkljive s področja obrazov različnih ras, spolov, starosti in drugih demografskih značilnosti, kar se kaže v slabši sposobnosti algoritma za prepoznavanje obrazov. Rezultat? Tehnologije slabše prepoznavajo temnopolte, ženske in druge družbene skupine. Koga algoritmi običajno prepoznajo brez težav? Starejše bele moške.
O problemih pomanjkljivo zastavljenih podatkovnih zbirk se načelno ne pogovarjamo, saj gre za sistemski in »dolgočasen« problem. Zbiranje podatkov je v podatkovni ekonomiji namreč ena od osnovnih funkcij, ki predpostavlja vse ostalo. Če bi odločevalci resno jemali svarila raziskovalcev, ki že več kot deset let opozarjajo na identičen problem podatkovnih zbirk, na katerih še vedno učijo algoritme, bi se ta del informacijske družbe sesul kot piramida iz kart.
Algoritmi in skrito delo
Eden od večjih problemov na področju umetne inteligence in algoritemskega opravljanja nalog je pomanjkanje zavedanja, da večino dela opravijo slabo plačani mezdni delavci. Ne glede na to, ali govorimo o algoritemskem odstranjevanju problematičnih vsebin z družabnega spleta, algoritemskem prepisovanju zvočnih in video posnetkov, analiziranju zadetkov spletnega iskalnika, ugotavljanju vzorcev na področju e-zdravja in ekonomije ali drugih področjih (prepoznavanje oblik človeških teles ob cesti za samovozeča vozila), povsod lahko v ozadju najdemo podjetja in celo industrijo slabo plačanih sužnjev, ki opravljajo skrito delo ter omogočajo »umetno inteligenco«.
Kazni za krivične algoritme nimamo. Zakonodaja namreč za zdaj velja samo za ljudi, ne za stroje.
Ena od držav, ki trenutno predstavlja središče skritega dela, s katerim se napaja industrija umetne inteligence, je Venezuela. Ekonomska kriza, pandemija koronavirusa, politična nestabilnost, vse to so bili razlogi, da so lahko korporacije dobesedno ugrabile in raztrgale to državo, uvedle nečloveške pogoje dela in pod takimi pogoji na izredno poceni način prišle do izredno dragocene surovine – obdelanih podatkovnih zbirk za algoritme.
Največji sužnjelastniki? Veliki avtomobilski koncerni (Volkswagen, BMW), ki so se ustrašili novih konkurentov na domačem dvorišču (Uber, Tesla) in pospešeno razvijajo sisteme za avtomatizirano vožnjo, ki potrebuje ogromne količine označenih podatkov. Je tista senca na levi pešec ali drevo? Je pred avto skočila srna ali metulj? Na semaforju gori rdeča luč ali zelena?
Podobne centre za sortiranje podatkov poznajo tudi druge južnoameriške in afriške države, kjer podjetja že več deset let vzpostavljajo industrijo predelovanja in označevanja podatkovnih zbirk, s katero se napaja večina industrije informacijske družbe. Vedno ceneje in vedno bolj prikrito.
Algoritmi so seksi
Da se o problemu avtomatiziranih sistemov podatkovne ekonomije ne znamo resno pogovarjati, del krivde leži tudi v ugotovitvi, da se omemba algoritmov danes dobro sliši. Tehnodeterminističen način razmišljanja, kjer je več tehnologije avtomatično nekaj boljšega, namreč sili v vse pore družbenega življenja in nam z obljubami boljše uporabniške izkušnje, prihranka časa in drugih superlativov vsiljuje nedelujočo, nevarno in nenadzorovano tehnologijo, ki služi samo svojim lastnikom na škodo družbe.
Naredite enostaven preizkus in poskusite danes kupiti »neumen« televizijski sprejemnik, torej sprejemnik, ki v sebi ne skriva algoritmov za optimizacijo gledalčeve izkušnje, ki ne vsebuje algoritmov za preprodajo vaših podatkov oglaševalcem oziroma ki čez vsebino ne lepi oglasov. Izredno težka, če ne celo nemogoča naloga. Televizorji so danes pač »pametni«.
Ali pa pojdite v avtomobilski salon in poskusite kupiti osebni avtomobil, ki v sebi ne skriva sistemov za avtomatizacijo posameznih funkcij, od klimatske naprave in ogledal do drugih sistemov. Tudi avtomobilska industrija se namreč vedno bolj ogreva za algoritemsko reševanje problemov in za zdaj še uspešno ignorira probleme, ko algoritem »spregleda« pešca, ker je ta »napačnega« spola. Ali pa ko algoritem ne »prepozna« voznika, ker ima »napačno« barvo polti.
Algoritme danes najdemo dobesedno v vseh glavnih gospodarskih sektorjih. Med glavne razloge, da je navdušenje nad umetno inteligenco in razširjeno rabo v zadnjih letih dobesedno eksplodiralo, lahko vključimo pandemijo koronavirusa, ki je spremenila način dela, prisilila delodajalce v iskanje nove delovne sile ter novih načinov za ustvarjanje prihrankov v proizvodnji.
Poleg tega se je treba zavedati, da so skladi tveganega kapitala v zadnjih desetih letih povsem svetu za več kot dvajsetkrat (s treh na 70 milijard evrov) povečali investicije v ta sektor. In končno, tehnološki napredek na področju strojne opreme in vedno nižjih stroškov podatkovne hrambe je na široko odprl vrata razvijalkam in razvijalcev iz vsega sveta.
A navkljub opozorilom in vedno večjemu številu algoritemskih katastrof se je do zdaj industrija na tem področju uspešno branila posegov od zunaj, ki bi pomagali preprečevati zlorabe in povzročeno škodo. Navkljub večjemu številu globalnih afer so odločevalci to področje do zdaj prepuščali razvijalcem in tržnikom ter samo šteli trupla.
Prihaja regulacijska palica
Na področju Evropske unije zakonodajalci razvijajo več zakonodajnih predlogov, ki se lotevajo največjih požarov na področju podatkovne ekonomije in informacijske družbe, od digitalnih storitev (Uredba o enotnem trgu digitalnih storitev) do velikih podatkovnih sistemov (Uredba o tekmovalnih in pravičnih trgih v digitalnem sektorju) ter umetne inteligence in algoritmov (Uredba o določitvi harmoniziranih pravil o umetni inteligenci).
Še vedno ne vemo, zakaj Google med zadetke iskanj opic s kalkulatorjem uvršča temnopolto deklico, in še vedno ni jasno, zakaj Google tega problema ne zna odpraviti. Še huje, več kot očitno je, da tega ne ve niti sam Google.
Na področju umetne inteligence poskuša Evropska komisija z zakonodajnim predlogom preprečiti scenarije kitajske informacijske družbe in sistema družbenega kredita (social credit system, op. p.), kritiki pa opozarjajo, da predlog preveč upanja polaga prav v samoregulacijski mehanizem industrije in prostovoljnih zavez spoštovanju etičnih standardov pri razvoju sistemov.

Lovk družbe nadzora, ki zbira in preprodaja naše podatke, je vedno več.
Dodaten problem predstavlja tudi problematična definicija sistemov, ki bi jih zajela Uredba o umetni inteligenci, saj naj bi bila po mnenju več držav preširoka in preohlapna, to pa bi lahko pomenilo, da bi trpela industrija, ki te problematične rešitve že uporablja oziroma jih poskuša uvesti na širokem področju.
Hkrati poskušajo industrija informacijske tehnologije in spletni velikani na več različnih načinov doseči, da bi zakonodajalcem palico prelomili še pred dejansko uporabo in bi pravila oblikovali okrog praks največjih podjetij (Google, Facebook, Amazon) na tem področju. Kritiki opozarjajo, da bi to dejansko pomenilo, da bi Evropski uniji spodletelo zamejiti razvoj problematičnih sistemov umetne inteligence, kot jih pozna Kitajska, hkrati bi regulacija spet prizadela manjše domače razvijalce na tem področju.
A tudi v Združenih državah Amerike in celo na Kitajskem oblasti napovedujejo večjo vpetost zakonodajalcev na področje algoritemskega odločanja. Presenetljivo gre Kitajska na področju algoritmov, s katerimi podjetja »optimizirajo« uporabniško izkušnjo, označujejo posameznega uporabnika in ga na podlagi zbranih podatkov lahko tudi izkoriščajo (Kitajska s tem rešuje velik problem digitalne zasvojenosti), od vseh treh gospodarskih con najdlje, njene poteze pa budno spremljajo tako v Združenih državah Amerike kot tudi v Evropski uniji.
Prakse so na tem področju namreč izredno koristne zaradi globalnega dosega največjih podjetij, ki vladajo v digitalni ekonomiji. Tako bi bila lahko harmonizacija pravil in omejitev enostavnejša, saj bi si lahko politični sistemi med seboj podajali preverjene rešitve, ki že delujejo.
Težavo poleg vedno večjega pomanjkanja politične volje še vedno predstavljata pomanjkanje tehničnega znanja in prevelik vpliv predstavnikov največjih podjetij informacijske družbe na odločevalce, ki z lobističnimi pritiski rišejo sebi ugodne meje digitalnega sveta, tako kot se je to že dogajalo na področju zakonodaje GDPR.
Titaniki informacijske družbe
Zgodovina uči, da so se Združene države Amerike odločile za regulacijo radijskih valov po potopitvi Titanika. Klici na pomoč s te domnevno nepotopljive ladje namreč niso dosegli drugih ladij oziroma kopnega, saj so radijske valove »mašili« radioamaterji. To je poleg katastrofalne razporeditve reševalnih jopičev in prepričanja, da se Titaniku ne more nič zgoditi, pripomoglo h katastrofi, ki je zahtevala dobrih 1.500 življenj.
Dejansko lahko na področju informacijske družbe govorimo o podobni katastrofi, s pomembno razliko – Titanik ni eden, ampak jih je več, in sicer na področju zbiranja in analiziranja (osebnih) podatkov, vedno večjega števila biometričnih zbirk, v katerih so zapisani podatki, ki jih ni mogoče »ponastaviti«, vse bolj invazivne industrije umetne inteligence, ki jo (ironično!) poganjajo neznanje odločevalcev ter pritiski industrijskih velikanov … V morju podatkov je tako trupel vedno več.
Od odtekanja podatkovnih zbirk uporabnikov najrazličnejših storitev, ki je povzročilo porast zlorab osebnih podatkov, večji uspeh pri vdiranju v uporabniške račune in druge oblike kibernetskega kriminala, do neuspešnega odstranjevanja vsebin, ki je vodilo v cenzuro, od spodletele implementacije algoritma za izbiro primernih kandidatov na delovno mesto, za katerega se je izkazalo, da dobesedno sovraži ženske, do algoritmov za prepoznavanje obrazov, ki so v ameriških kongresnikih napačno prepoznali obsojene zločince (brez šal, prosim!) ... Vedno znova se na področju naprednih tehnologij ukvarjamo z vse bolj smrtonosnimi problemi.
In vedno znova gre »reševanje« Titanika po isti poti – podjetje se posipa s pepelom, uporabniki preklinjamo lastno naivnost in nemoč, regulator na podlagi kršitev v najboljšem primeru napiše kazen, ki jo, spet v najboljšem primeru, nato dejansko izterja, nato pa podjetje na pot pošlje novo različico Titanika. In krog se ponovi.
Kako je torej z opicami s kalkulatorji?
Rešitev več kot očitno ne bo prišla od informacijske industrije, ki je bolj zaposlena z inoviranjem novih problemov, ki iščejo rešitve, prav tako ne bo od regulatorjev, ki poskušajo na podlagi najočitnejših avtomobilskih nesreč napisati pravila vožnje in jih nato dopolnjevati z novimi primeri, ko se ti dejansko zgodijo.
Tudi vloga izobraženega in izkušenega potrošnika, ki s svojo denarnico nagrajuje dobre prakse in kaznuje slabe, se običajno zelo slabo obnese, saj trg ni uravnotežen, hkrati pa informacijske tehnologije in umetna inteligenca postajajo tako vseprisotne, da se jim je pravzaprav nemogoče izogniti.
In če računate, da vam bodo na pomoč priskočili razvijalci umetne inteligence, izpod prstov katerih prihajajo nove pošasti informacijske družbe, potem lahko kar nehate računati – vedno znova se namreč izkaže, da so programerji izredno slabi pri ocenjevanju širšega vpliva svojih izdelkov. In če so za te nevarne igrače še nagrajeni z borznim uspehom … No, potem je tukaj vse v redu, mar ne?
Rešitev bi se lahko skrivala v spremembi mišljenja, s katerim iščemo rešitve. Postopno vpeljevanje tehnologij in storitev, ki bi bile podprte s transparentnim dokaznim gradivom, s katerim bi lahko na omejenem področju ugotavljali primernost in neprimernost tehnoloških rešitev, žrtvovanje hitrosti za uporabnost in sprotno zagotavljanje varovalk bi sicer uničili poslovni model, ki trenutno prinaša največje dobičke, a bi hkrati zavarovali naše podatke in omejili širino katastrof na tem področju.
Igranje roparjev in žandarjev, kjer industrija stroške kazni že vračuna v razvojne investicije in kjer borze ter skladi tveganega kapitala nagrajujejo uničevalne pohode in zlorabe osebnih ter biometričnih podatkov, namreč več kot očitno ne prinaša želenih rezultatov. Še vedno namreč ne vemo, zakaj Google med zadetke iskanj opic s kalkulatorjem uvršča temnopolto deklico in še vedno ni jasno, zakaj Google tega problema ne zna odpraviti. Še huje – več kot očitno je, da tega ne ve niti sam Google.