Čuda iz Nvidie
Preštejte, koliko procesorskih jeder imate v svojem računalniku. Dva, štiri, osem? Če imate grafično kartico, izdelano v zadnjih letih, jih imate v resnici nekaj sto. Večina teh jeder domuje na grafični kartici, a to ne pomeni, da znajo preračunavati samo grafiko. V zadnjih letih je nesluten razvoj doživela tehnologija GPGPU, ki omogoča izkoriščanje te množice jeder za raznovrstne operacije. Pohitritve so velikanske.

Nekatere grafične kartice Nvidia Tesla sploh nimajo priklopa za monitor, ker so namenjene izključno za GPGPU.
Tehnologija se imenuje GPGPU (general-purpose computing on graphics processing units) in pomeni uporabo grafičnih procesorjev za izvajanje izračunov, ki z izrisom grafike nimajo nobene zveze. Logika je preprosta: povprečna Nvidiina ali AMDjeva grafična kartica ima dandanes več sto jeder, ki lahko računajo neodvisno od drugih. Ker so zelo hitra in imajo precej pomnilnika, se tam skriva možnost za velikanske pohitritve programov, in to ne le doma.
Tudi najhitrejši superračunalniki na svetu čedalje pogosteje uporabljajo grafične procesorje, ker lahko tako na majhen prostor ob nizki porabi energije stlačijo zelo veliko računske moči. Drugi najzmogljivejši superračunalnik, Cray Titan, ima 18.688 16-jedrnih AMDjevih Opteronov in prav toliko grafičnih kartic Nvidia Tesla K20X, od katerih ima vsaka 2688 jeder. Ne zato, da bi na njem poganjali igre v ultravisoki ločljivosti, temveč ker je grafična kartica pri nekaterih izračunih bistveno hitrejša od centralnega procesorja in bi jih bilo neumno ne izkoristiti. Titan še zdaleč ni edini superračunalnik z grafičnimi karticami, le najhitrejši med njimi je.
Pohitritve, ki jih prinese uporaba grafičnih procesorjev za računanje, so lahko v idealnih primerih tudi 200-kratne v primerjavi s centralnim procesorjem.
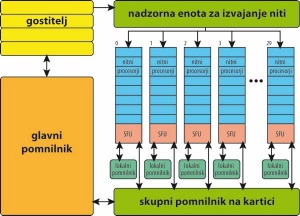
Zgradba grafične kartice Tesla. Vir: Portland Group.
Kaj potrebujemo?
• Nvidiino grafično kartico s podporo za CUDA (vse izdelane v zadnjih letih)
• gonilnike za kartico
• knjižice CUDA in prevajalnik (nvcc ali PGI CUDA Fortran)
Grafična kartica
Za to, da bi razumeli, kaj lahko pridobimo z računanjem na grafični kartici in zakaj, moramo poznati zgradbo grafične kartice. Tu se ne bomo poglabljali v fizično izvedbo, temveč zgolj tako podrobno, kolikor je nujno za razumevanje paralelizma. Opisana zgradba sicer velja za Nvidiine grafične kartice, kjer se detajli med karticami družin Fermi in Tesla nekoliko razlikujejo, a tudi pri AMDjevih ni bistvenih razlik, logika pa je ista.
Da so grafične kartice postale resni igralci, so se morale naučiti še nekaj zvijač, predvsem so morale izboljšati delo s pomnilnikom in zanesljivost (dobile so celo odpravo napak – ECC). Pri izrisu slike je popolnoma vseeno, če se zgodi kakšen preskok bita in je ena pika na zaslonu črna namesto siva. Pri obdelavi podatkov, ki jih nadalje uporabljamo, pa je to nesprejemljivo. Prav tako so se morale kartice naučiti naključnega dostopa do pomnilnika in hitrega prenosa podatkov s kartice nazaj v centralni pomnilnik, kar pri izrisu slike ni pomembno. Ko so grafične procesorje naučili izvajati tudi druge operacije, ki niso povezane z izrisom slike, je bil oder zanje pripravljen.
Grafična kartica ima več multiprocesorjev, ki delujejo popolnoma neodvisno drug od drugega, med seboj pa lahko komunicirajo prek globalnega pomnilnika ali skupnega pomnilnika na kartici. Tesla ima lahko 30 multiprocesorjev, Fermi pa 16. Vsak multiprocesor ima eno skupino po 8 (Tesla) ali dve skupini po 16 (Fermi) tokovnih procesorjev (stream processor), ki jim navadno rečemo kar jedro. To je tisto število jeder, ki ga preberemo ob nakupu kartice. Vsako jedro izvaja več niti po tehnologiji SIMT (Single Instruction, Multiple Thread), ki je podobna SIMD (Single Instruction, Multiple Data). Razlika nas na tem mestu ne bo zanimala; bistvo je, da niti vsebujejo različne podatke, na njih pa se izvajajo isti ukazi.

Superračunalnik Cray Titan s teoretično zmogljivostjo 27 petaFLOPS ima 18.688 kartic Nvidia Tesla K20X, ki ima vsaka 2688 jeder.
Dostop do skupnega pomnilnika na kartici je zelo počasna operacija, ki lahko traja tudi sto procesorskih ciklov. Zato so jedra na grafični kartici namenjena sekvenčni obdelavi velikih količin podatkov z istimi ukazi. Kljub temu vse ni tako črno. Vsak multiprocesor ima nekaj lastnega pomnilnika, do katerega dostopajo vsa njegova jedra, dostopni čas pa je bistveno nižji. Multiprocesor je tudi tako pameten, da v času, ko neka nit čaka na podatek iz glavnega pomnilnika, kartica izvaja druge niti. To je mogoče, ker je običajno niti bistveno več kakor jeder, preklapljanje med njimi pa je tako hitro, da je poganjanje več niti, kot je jeder, v resnici zaželeno.
Pozor!
Grafični procesorji so namenjeni računanju omejenega nabora ukazov na velikem številu podatkov (SIMD), centralni procesorji pa so bistveno boljši, kadar imamo malo podatkov, na katerih je treba izvesti različne operacije (SISD).
Žal ni mogoče dati pavšalne ocene, kolikokrat hitreje se bo program izvajal na grafični kartici, ker je to odvisno od množice dejavnikov in narave problema. V idealnih primerih so pohitritve tudi 200-kratne.
Programski jeziki
Poznamo več programskih jezikov, vmesnikov oziroma tehnologij, ki so namenjene pisanju aplikacij, ki bodo tekle na grafičnih procesorjih. Microsoft je predstavil svoje knjižice z imenom DirectCompute, ki žal podpirajo le Windows 7 in novejše, drugače pa sodijo v družino DirectX in si delijo številne funkcionalnosti z OpenCL in Cudo. To pomeni, da razvoj programov zanje ni težak, a je omejitev na Windows resna pomanjkljivost.
OpenCL je odprtokodni programski jezik za programe, ki tečejo na najrazličnejših procesorjih. Tako na centralnih procesorjih kakor tudi na grafičnih jedrih, FPGAjih, DSPjih in drugod. Nastal je iz jezika C99, s katerim si deli osnovno sintakso, česar bo vesela nepregledna množica programerjev, ki že uporabljajo C. OpenCL je napisan tako, da je kar najširše prenosljiv; to mu včasih ponagaja pri hitrosti izvajanja.
Nvidia je pripravila tudi svojo lastniško rešitev Cuda, ki je namenjena pisanju aplikacij, ki bodo tekle na Nvidiinih grafičnih karticah. Nvidia je namreč zelo hitro spoznala, da je v GPGPU prihodnost, zato je že leta 2007 pripravila razvojni komplet (SDK) Cuda za Windows in Linux, kasneje še Mac, ter začela intenzivno marketinško kampanjo. Zato je danes Cuda bistveno bolj razširjena od AMDjeve platforme Stream, ki načeloma počne isto, le za AMDjeve grafične čipe. Poleg teh so še številne druge, na primer OpenACC, a mi smo pristali pri Cudi, saj imamo v našem strežniku Nvidiini kartici Tesla.
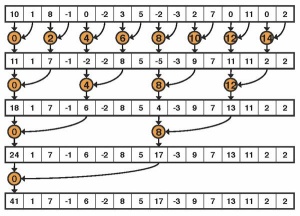
Seštevanje je problem, ki ga je mogoče s pametnim vrstnim redom (redukcija drevesa) do neke mere paralelizirati. V vsakem ciklu seštejemo sosednja elementa.
Nvidia Cuda
Nvidia je zgodaj ugotovila, da mora za uspešen razmah tehnologije Cuda osvojiti znanstvenoraziskovalno srenjo in domače uporabnike. Zato ni presenetljivo, da so hitro pripravili prevajalnike, ki omogočajo pisanje Cjevske, C++ovske ali fortranske kode in prevajanje s podporo GPGPU. Iz C in C++ se prevaja z brezplačnim Nvidiinim prevajalnikom nvcc, fortranska koda pa se prevede s prevajalnikom PGI Cuda Fortran, ki ni zastonj. Presenečeni bi bili, koliko kode za znanstvene aplikacije se še vedno piše in poganja v fortranu, zato podpora temu jeziku ni nič nenavadnega.
Razlog, da je Cudi tako uspelo, je poleg hitrosti tudi preprosto pisanje programov. Raziskovalci se ne marajo ukvarjati s sintakso in optimizacijo programov, temveč želijo kar najbolj uporabiti že obstoječo kodo. Cuda omogoča prav to. Z nvcc lahko prevedemo obstoječ Cjevski program in ta bo prav lepo deloval, pri tem pa se bo seveda v celoti izvajal na centralnem procesorju in hitrostnih pospeškov ne bo. Spremembe (dodatni ukazi in kvalifikatorji), s katerimi ga prisilimo v izvajanje na grafičnih procesorjev, niso prevelike, vsi potrebni ukazi (npr. za prenos podatkov v pomnilnik na kartici in nazaj) pa so že izdelani in jih preprosto uporabimo.
Pri pisanju programov za grafične procesorje moramo poznati terminologijo. Centralni procesor in njegov pomnilnik, kjer se program začne izvajati, se imenujeta gostitelj (host). Grafični procesor in njegov pomnilnik se imenujeta naprava (device), funkcija ali podprogram, ki tam teče, pa jedro (kernel). Kasneje je treba za vsako spremenljivko in vsako funkcijo v programu definirati njeno vidnost. Ta je lahko dostopna tako z gostitelja kakor naprave (global) ali pa le iz enega.

Izris Mandelbrotove množice je primer operacije, ki jo lahko neomejeno paraleliziramo, zato je idealna za uporabo GPGPU.
Funkcijo, ki se bo izvajala na grafičnem procesorju, definiramo povsem običajno, le da jo začnemo s kvalifikatorjem __global__, ki določa vidnost tudi z naprave. Kot argument lahko s funkcijo na napravo pošljemo skalarne količine, vektorje pa moramo poprej v pomnilnik na napravo prekopirati z ločenim ukazom, prav tako jih moramo od tam po koncu izvajanja programa prebrati. Da se bo funkcija izvajala na grafični kartici, jo moramo poklicati s posebnimi oklepaji.
Oglejmo si izsek enostavne funkcije, ki sešteje dva vektorja, a in b.
__global__ void add( int *a, int *b,
int *c ) {
int tid = blockIdx.x;
if (tid < N)
c[tid] = a[tid] + b[tid];
}
Od vsakdanje Cjevske kode se razlikuje po kvalifikatorju global in po rezervirani spremenljivki blockIdx.x, ki jo bomo opisali kmalu. Omenjeno funkcijo bi v glavnem programu poklicali takole:
add<<<1,N>>> ( dev_a, dev_b, dev_c );
Trojni oklepaji prevajalniku povedo, da jo mora izvajati na napravi in ne gostitelju. Ob tem moramo poskrbeti, da imamo spremenljivke dev_a, dev_b in dev_c deklarirane na napravi in da smo poprej v prvi dve prekopirali želene vrednosti, potem pa vrednosti zadnje prekopirali nazaj v pomnilnik na gostitelju. Medtem ko bi jo morali pri izvajanju na centralnem procesorju poklicati N-krat, jo na grafičnem procesorju pokličemo samo enkrat, potem pa vsaka nit sešteje svojo komponento vektorja.
Povedati moramo še, kaj so 1, N in blockIdx.x.
Niti, bloki, mreža
Nit (thread) je programski tok in predstavlja zaporedje ukazov, ki se izvajajo. Če želimo vzporedno na enak način obdelati več podatkov, jih je smiselno razdeliti v več niti. Niti se združujejo v bloke (block), ti pa v mrežo (grid). Vse niti, ki so v istem bloku, se bodo izvajale na istem multiprocesorju in bodo imele dostop do istih podatkov v krajevnem predpomnilniku. To pomeni, da so lahko sinhronizirane med seboj. Kaj se zgodi z nitmi v različnih blokih, je odvisno od prevajalnika, kartice in krajevnih pogojev. Lahko prebivajo na istem multiprocesorju ali pa ne, lahko se tudi malo selijo sem in tja, logično pa se med seboj ne vidijo.
Arhitektura postavlja zgornjo omejitev števila niti v bloku, in sicer na 512 za Tesla in 1024 za Fermi, lahko pa uporabimo tudi manjšo vrednost. Nujno je, da je to število večkratnik števila 32 zaradi zgradbe in načina dodeljevanja niti na multiprocesorje, sicer pa je treba za optimalno vrednost nekoliko poizkušati, saj je odvisna od kode, pomnilniške požrešnosti in drugih parametrov. Druga vrednost v trojnih oklepajih (N) torej predstavlja število teh niti v bloku. Vse to so razlogi, da je treba kodo prilagoditi vsaki seriji kartic posebej, zato Cuda ni primerna za pisanje programov, ki bodo tekli na zelo različnih platformah.
Vrednost 1 v zgornjem zgledu pa predstavlja število blokov. Teh je lahko toliko, kot je multiprocesorjev, ali pa več, ker so grafične kartice odlične pri preklapljanju. Za čim boljše rezultate je celo zaželeno, da je blokov več kakor multiprocesorjev.
Spremenljivke predstavljajo: blockIdx.x – zaporedna številka bloka, blockDim.x – število niti v bloku (dimenzija), threadIdx.x – zaporedna številka niti v bloku, gridDim.x – število blokov v mreži (dimenzija). Indeksi x pomenijo, da gre za enodimenzionalne količine, saj kartice podpirajo tudi dvodimenzionalne (in v prihodnosti tridimenzionalne).
Zato če imamo problem, ki terja večje število niti, to ni problem. Obdržati moramo število niti na multiprocesor, na kartici pa obdelujemo več blokov, kot je multiprocesorjev, ker je preklapljanje med njimi hitro in ne vpliva bistveno na hitrost izvajanja.
Zdaj si oglejmo kodo, ki j-krat (samo zato, da bi razlika v časovni potratnosti očitnejša) izračuna produkt istoležnih komponent vektorjev a in b, ki imata dimenzijo 409.600.000, in jo shrani v vektor c. Vsote komponent vektorja c, da bi res dobili skalarni produkt, zaradi enostavnosti nismo izračunali.
Koda, ki se izvaja na centralnem procesorju.
#include
#define N (400000 * 1024)
int main( void ) {
int *a, *b, *c;
//alokacija pomnilnika na CPU
a = (int*)malloc( N * sizeof(int) );
b = (int*)malloc( N * sizeof(int) );
c = (int*)malloc( N * sizeof(int) );
//izmislimo si komponente vektorjev
for (int i=0; i<N; i++) {
a[i] = i;
b[i] = 2 * i;
}
//izracun produkta komponent
for (int i=0; i<N; i++) {
for (int j=0 ;j < 100; j++) {
c[i] = (a[i]*b[i]);
}
}
return 0;
}
Koda, ki se izvaja tudi na grafičnem procesorju.
#include
#define N (400000 * 1024)
//izracun produkta komponent
__global__ void add( int *a, int *b,
int *c ) {
int tid = threadIdx.x + blockIdx.x *
blockDim.x;
while (tid < N) {
for (int j = 0; j < 100; j++) {
c[tid] = a[tid]*b[tid];
tid += blockDim.x * gridDim.x;
}
}
int main( void ) {
int *a, *b, *c;
int *dev_a, *dev_b, *dev_c;
//alokacija pomnilnika na CPU
a = (int*)malloc( N * sizeof(int) );
b = (int*)malloc( N * sizeof(int) );
c = (int*)malloc( N * sizeof(int) );
//alokacija pomnilnika na GPU
cudaMalloc( (void**)&dev_a, N *
sizeof(int) ) ;
cudaMalloc( (void**)&dev_b, N *
sizeof(int) ) ;
cudaMalloc( (void**)&dev_c, N *
sizeof(int) ) ;
//izmislimo si komponente vektorjev
for (int i=0; i<N; i++) {
a[i] = i;
b[i] = 2 * i;
}
//prenos podatkov iz pomnilnika CPU v GPU
cudaMemcpy( dev_a, a, N * sizeof(int),
cudaMemcpyHostToDevice ) ;
cudaMemcpy( dev_b, b, N * sizeof(int),
cudaMemcpyHostToDevice ) ;
add<<<128,128>>>( dev_a, dev_b, dev_c );
//prenos podatkov iz pomnilnika GPU v CPU
cudaMemcpy( c, dev_c, N * sizeof(int),
cudaMemcpyDeviceToHost ) ;
return 0;
}
Poleg nekoliko več vrstic kode, ki so potrebne za alokacijo pomnilnika na grafični kartici in kopiranje podatkov nanjo iz z nje, je glavna razlika v štetju komponent oziroma v teku indeksa. Indeks i pri klasičnem programu za CPU teče od 0 do N-1, torej preteče vsako komponento, kot je običajno. Za hitro izvajanje na grafičnem procesorju pa moramo operacijo paralelizirati. Zato kličemo funkcijo add samo enkrat, kjer sta <<<128,128>> parametra, ki poskrbita za optimalno izvajanje konkretnega programa na naši grafični kartici, ki je bila Nvidia Tesla C2070. Ključ se skriva v spremenljivki tid, ki ves čas poganjanja programa raste, vsakokrat pa jo izračunamo iz zaporedne številke niti v bloku (threadIdx.x), zaporedne številke bloka (blockIdx.x) in števila niti v bloku oziroma njegove dimenzije (blockDim.x). Ker je dimenzija vektorja večja od največjega števila niti, ki jih na ta način lahko hkrati spravimo v grafično kartico, moramo na koncu indeks zamakniti za dimenzijo mreže (gridDim.x). Paralelizacija je izvedena s samo arhitekturo grafične kartice.

Ekstremna uporaba GPGPU s sedmimi karticami GeForce 9600 GT. Vir: Bit-tech.net
Hitrostna pohitritev
Ko smo program pognali prvikrat, se je različica GPU izvajala enako hitro kot CPUjevska. Kaj pa je zdaj to? Hitro smo ugotovili, da je ozko grlo v tem primeru hitrost kopiranja podatkov na grafično kartico in z nje. Če je računski del kratek, se vse pohitritve izgubijo zaradi počasnega prenosa podatkov. Malo smo pomislili in na silo poskrbeli, da je računanja več, prenosa podatkov pa ne. Zato sta v obeh primerih indeksa j, ki štejeta ponovitve zunanje zanke, ki pravzaprav že prvikrat naredi vse prav in se potem samo ponavlja. Maksimalno vrednost j smo spreminjali od 1 do 10.000. Tako smo regulirali količino računanja.
Rezultati prepričljivo govorijo v prid računanja na GPU. Naš računalnik ima posebej za GPGPU narejeno grafično kartico Nvidia Tesla C2070, procesor Intel Xeon E5440 (2,83 GHz) s 16 GB pomnilnika ECC, vse skupaj pa poganja Ubuntu 10.4 LTS. Hitrost računanja na GPU je približno 235-krat hitrejša od računanja na CPU (glej tabelo).
Različice Cude
Sposobnosti kartic se sčasoma razvijajo in danes omogočajo že bistveno več svobode kot ob sramežljivih začetkih Cude. Nvidia zato kartice deli glede na sposobnost uporabe Cude v verzije 1.0, 1.1, 1.2, 1.3, 2.0, 2.1, 3.0 in 3.5. Kam sodi katera kartica, lahko preverite na spletnih straneh proizvajalca. V splošnem ima vsaka naslednja verzija podporo za več ukazov, kar pohitriti njihovo izvajanje, ker jih ni treba sestavljati iz osnovnih ukazov v naboru, in večje registre, pomnilnike, več jeder, dodatne enote itn. Na primer Cuda 1.3 je prinesla operacije na številih s plavajočo vejico z dvojno natančnostjo.
Ista koda bo tekla na vseh karticah, a različno hitro. Priporočljivo je, da jo v finesah na koncu prilagodimo točno določeni kartici, s tem pa seveda tudi verziji Cuda.
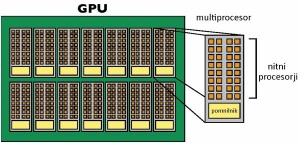
Shema zgradbe grafične kartice, ki podpira GPGPU.
Fantastično, jaz to hočem!
Ni vse zlato, kar se sveti, in tudi Cuda (ter GPGPU nasploh) ima slabe lastnosti. Prva je tu že po definiciji: gre za zaprto, čeprav brezplačno platformo, ki vas učinkovito priklene na Nvidiine kartice.
Druga pomanjkljivost same arhitekture pa je ta, da vseh izračunov ne moremo paralelizirati. Grafične kartice delujejo na arhitekturni zamisli SIMD (single instruction, multiple data), kar pomeni, da lahko hitro izvajajo isto operacijo na množici različnih podatkov. Če imamo problem, ki to terja, bomo z uporabo GPGPU dobili izjemne pohitritve. Po drugi strani pa ta možnost ni več tako privlačna, kadar imamo podatke, ki so odvisni drug od drugega in potrebujemo med računanjem komunikacijo. V tem primeru bistvenih pohitritev z uporabo GPGPU ni mogoče pričakovati. To je tudi razlog, da smo v zgornjem zgledu računali le produkte istoležnih komponent, ker je to problem, ki ga je mogoče enostavno paralelizirati. Če bi jih želeli na koncu še sešteti, bi ta del bistveno manj pridobil z rabo GPGPU. Seštevanje se namreč najhitreje izvede v več ciklih tako, da se vsakokrat seštejeta sosednja elementa, tako da imamo vsakokrat pol manj komponent.
Razlika med grafičnim procesorjem in centralnim procesorjem je v pristopu. Grafični procesorji so namenjeni računanju omejenega nabora ukazov na velikem številu podatkov (SIMD), centralni procesorji pa so bistveno boljši, kadar imamo malo podatkov, na katerih je treba izvesti različne operacije (SISD, single instruction, single data).
To med drugim pomeni, da je paralelizacija za grafična jedra drugačna kot tista za centralne procesorje (npr. OpenMP). Bistvena razlika so sorazmerno toga pravilna glede števila niti, ki je po določitvi nespremenljivo. Jedro (kernel) med delovanjem ne more tvoriti novih niti, prav tako je zelo zaželeno, da nima preveč razvejitev, ki bi povzročile, da se različni podatki kljub enaki funkciji potem obdelujejo po različnih poteh.
Žal ni mogoče dati pavšalne ocene, kolikokrat hitreje se bo program izvajal na grafični kartici, ker je to odvisno od množice dejavnikov in narave problema.
Glavne smernice pri programiranju za grafična jedra
• Čim večja paralelizacija zaporedne kode
• Čim manj prenosov podatkov med kartico in centralnim procesorjem
• Optimizacija kode za vsako kartico posebej
• Zagotavljanje, da je pomnilnik alociran zaporedno brez vrzeli (coalesced)
• Čim manj dostopov do centralnega pomnilnika iz procesov na kartici
Sklep
Zdi se, da bo Moorov zakon preživel. Ko so inženirji pri sestavljanju centralnih procesorjev začeli trkati ob zgornjo mejo dvigovanja takta, je bila podvojitev hitrosti računalnikov vsaki dve leti ogrožena. Tudi miniaturizacija počasi prihaja do konca, saj tranzistorji ne morejo biti manjši od deset atomov, pa že tu so kvantni učinki (recimo tuneliranje elektronov od vira na ponor kljub izključenim vratom) opazni. Intel in AMD sta zagato začela reševati z dodajanjem jeder v procesor, kar je dokončno prisililo pisce programske opreme, da so jo začeli prilagajati na vzporedno delovanje. Grafični procesorji iz Nvidie in AMDja to povečevanje števila jeder in masovno paralelizacijo dvignejo na novo raven.
Enega izmed preprostejših in zmogljivih načinov, kako lahko to silovito moč vzporednega računanja na grafičnih jedrih izkoristimo sami, prinaša Cuda. Seveda je treba vedeti, čemu je Cuda namenjena. Pisanju komercialnih aplikacij, ki bi jih uporabniki poganjali na vseh mogočih grafičnih procesorjih, vsekakor ne. Tudi te lahko veliko pridobijo z GPGPU. Nekaj smo jih že preizkusili v prejšnjih številkah, in sicer v Monitorju 01/09 in 10/12, kjer smo ugotovili, da so pohitritve očitne. Danes pa smo si ogledali, kako lahko zmogljivosti grafičnih procesorjev izkoristimo sami pri pisanju lastne kode. In to je namen Cude.
Intelov odgovor na GPGPU je več Xeonov

Intelov odgovor na GPGPU je na kartico spraviti čim več Xeonov, lahko tudi nekaj deset.
Moč paralelizacije je spoznal tudi Intel, zato je pripravil platformo MIC (Many Integrated Core), ki tekmuje z Nvidio Cuda. Kartice Xeon Phi so na prvi pogled podobne grafičnim karticam, a gre za drugačen pristop. Intel nanje stlači čim več klasičnih centralnih procesorjev Xeon, zato je pisanje programov, ki izkoriščajo Phi, nekoliko drugačno. Xeoni uporabljajo MIMD (multiple instruction, multiple data), grafična jedra pa SIMD.
Reference za nadaljnje branje
• CUDA by Example, An Introduction to General-Purpose GPU Programming
• CUDA Fortran for Scientists and Engineers
• CUDA Handbook: A Comprehensive Guide to GPU Programming