Tezaver nove generacije in slovenskega porekla
Tezavri ali slovarji sopomenk so že stara orodja, kjer so zapisane bolj ali manj ustrezne sopomenke besed v jeziku. Klasični so nastajali počasi, ob pisanju slovarjev, moderna tehnologija pa omogoča uporabo računalniških jezikovnih modelov, ki funkcijo tezavrov še širijo.
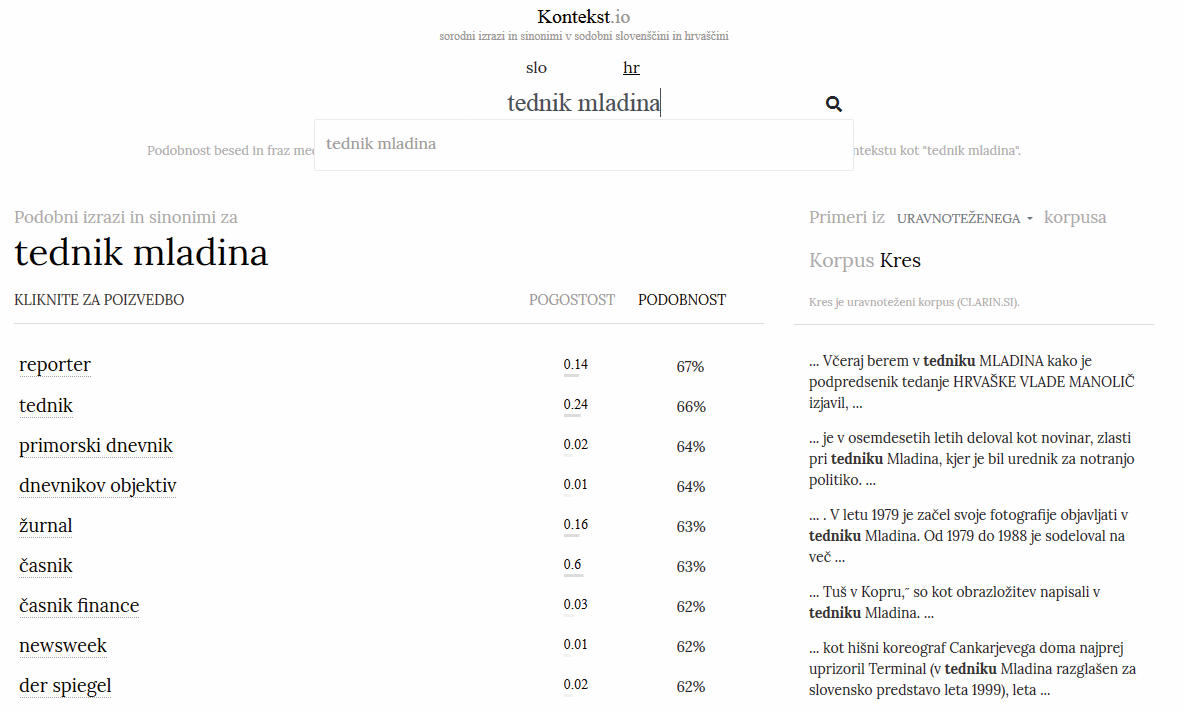
Medtem ko besedne zveze revija Monitor Kontekst.io še ne najde, so predlagani rezultati za tednik Mladina zelo relevantni.
Eden najbolj znanih prizorov iz serije Prijatelji je Joeyjeva uporaba tezavra, s katerim je tople, prijazne ljudi z velikim srcem prekrstil v vlažne, vabljive homo sapiense z aortnimi črpalkami naravne velikosti. Dasiravno komičen bi bil pred dvema desetletjema to povsem resničen prikaz uporabe računalniških tezavrov. Do danes pa sta računalniška analiza ter umetna inteligenca dovolj napredovali, da so novi modeli bistveno uporabnejši. Eden boljših je Kontekst.io, ki je dostopen na istoimenskem spletnem naslovu in je vse kaj več kakor tezaver.
Kontekst.io je plod dela Marka Plahute, znanega pod psevdonimom Virostatiq, v sodelovanju s Clarin.si (Slovenska raziskovalna infrastruktura za jezikovne vire in tehnologije) in z Založbo Eno. Na elegantno minimalistični spletni strani je osrednje iskalno polje, kamor vpišemo besedo ali besedno zvezo v slovenščini (ali hrvaščini, ker zna Kontekst.io oba jezika). Spletna stran vrne seznam podobnih izrazov in sinonimov, ki imajo pripisano pogostost in podobnost.
Že prvi primeri uporabe razkrijejo, da Kontekst.io ne vrača samo sinonimov, temveč izraze, ki imajo podoben pomen ali podobno polje uporabe. Za besedo »čebula« so prvi zadetki paprika (pogostost: 0,14, podobnost: 79 %), šalotka (0,01, 77 %), cvetača (0,05, 76 %) in špinača (0,08, 76 %). Za »miško« so zadetki še bolj zanimivi, in sicer: tipkovnica (0,27, 74 %), miš (0,24, 72 %), muca (0,17, 71 %) in veverica (0,06, 68 %). Niže na seznamu najdemo tudi izraze Logitechova, podgana, želva, sledilna ploščica, Sapra in tablica. Jasno je, da se miška uporablja v dveh zelo različnih pomenih, kar je tudi razlog za zelo zanimive rezultate. Mimogrede, iskalnik je hiter, saj v noben primeru na rezultat ni bilo treba opazno čakati.
Poleg seznama spletna stran vrne še izpise iz korpusa (zbirka besedil), ki prikažejo uporabo vpisane besede v stavkih. Izbiramo lahko med desetimi korpusi, od uravnoteženega do znanstvenega ali pogovornega. Drugih javno dostopnih funkcij Kontekst.io nima, a jih niti ne potrebuje. Storitev je namenjena iskanju podobnih besed, kar tudi zelo dobro počne.
Kontekst.io ni tezaver. Kdor želi tezaver, ga najde na naslovu www.tezaver.si. Ta vé, da sta edina slovenska sinonima za monitor ekran in zaslon, medtem ko besedne zveze »ameriška administracija« seveda ne pozna. Kontekst.io pa na besede gleda širše in pozna tudi takšne fraze. Ker se je učil iz ogromne množice besedil v korpusih, je njegovih predlogov več: Busheva administracija, Obamova administracija, Bela hiša, mednarodna skupnost, vladajoča koalicija, zvezna vlada, vlada itd. To pa seveda niso sopomenke, temveč besede, ki jih uvrščamo v semantično polje ali leksikalno verigo. Gre za besede, ki imajo pomene, ki so smiselno povezani z danim leksemom.
To jasno piše tudi v navodilih za Kontekst.io. Išče fraze, ki se uporabljajo v podobnem kontekstu, kamor sodijo sinonimi (sopomenke), antonimi (nasprotja), hipernimi (nadpomenke), hiponimi (podpomenke) in ostali pomensko sorodni izrazi. V iskalniku je skoraj 600.000 izrazov (za ilustracijo: SSKJ vsebuje nekaj manj kot 100.000 besed). Našli bomo redke besede (zavržno), imena oseb (Luka Dončić), zdravila (lekadol), blagovne znamke, razvade in navade (pitje alkohola), mamila, geografske pojme itd. Kontekst.io je zato še bolj kot iskalnik sinonimov uporaben za osvetlitev pojmov, saj si lahko ustvarimo zelo dobro predstavimo o neznanih pojmih, če vidimo, v kakšnem kontekstu se pojavljajo. Ob besedi Tito se pojavijo: Stalin, Hitler, Josip Broz, Kardelj, Lenin, Kučan, Mussolini, Slobo itn. Z nekaj iznajdljivosti lahko s strani Kontekst.io izvlečemo marsikaj zanimivega. Ker se je model učil tudi iz forumov, lahko z iskanjem po besedi censored ugotovimo, katere slovenske žaljivke spletni moderatorji največkrat cenzurirajo.
Besede, ki jih izpiše Kontekst.io, so na seznamu, ker se uporabljajo na podoben način. Tako sta skupaj besedi pašnik in travnik, ker se njuna pomena v dobršni meri prekrivata in ker je porazdelitev besed v njuni okolici statistično zelo podobno. Prav tako pa bo Kontekst.io skupaj shranil tudi »toplo« in »hladno«, ki se uporabljata na podoben način. Čeprav imata nasprotni pomen, ju lahko v stavkih običajno zamenjamo, pa bo stavek še vedno smiseln. V praksi to pomeni, da se pojavljajo zelo podobne tvorbe z eno ali drugo besedo (Danes je toplo, Danes je hladno), torej Kontekst.io vidi, da je njuna okolica podobna.
Kontekst.io podatke črpa iz približno 20 gigabajtov slovenskih besedil, ki so jih pridobili iz knjig (založbi Beletrina in Eno), spletnih novic, komentarjev, objav na forumih, referenčnih korpusov (inštitut Jožef Stefan), prevajalskih korpusov (OPUS), slovenskih podnapisov, kuharskih receptov in drugih besedil. Skratka, Kontekst.io je zagotovo prebral vse vrste slovenščine, ki se danes uporablja.
Ta besedila so uporabili za matematični model jezika (word2vec). Tako se imenuje skupina modelov za numerično reprezentacijo besed (word embedding). Gre za nevronske mreže z nevroni v dveh ravneh, ki so naučene na velikem številu besedil. Rezultat je vektorski prostor, ki ima več sto dimenzij (od 100 do 1000), v katerem je vsaki besedi prirejen vektor. Besede s sorodnim pomenom ali uporabo ležijo blizu druga drugi. Te modele so prvi razvili v Googlu, kjer je Tomaš Mikolov vodil raziskovalno skupino Google Brain (danes Mikolov sicer dela pri Facebooku). V Googlu so word2vec razvili leta 2013 in je do danes postal najbolj priljubljen ter najhitrejši način za trening modelov na osnovi vektorskih prostorov.
Spletna stran Kontekst.io, ki omogoča ročni vnos terminov in pregled rezultatov, nima popolnoma nobenih omejitev. Za napredne namene, kamor bi sodili uporaba za izboljšanje spletnega iskanja, numerične reprezentacije (embedding), raziskovanje v jezikoslovju in kulturi itd., pa bi seveda potrebovali računski model ali dostop do storitve prek API. Če bi želeli matematični model jezika uporabljati na področjih, kjer je besedišče specifično, denimo v medicini ali farmaciji, ali pa na starejših besedil, bi morali model učiti zgolj na tovrstnih besedil. Za vse takšne želje pa bo treba stopiti v stik z avtorjem.
Kontekst.io
matematični model jezika za iskanje podobnih fraz
Kdo: Virostatiq
Kje: kontekst.io
Cena: brezplačno
Za: Enostavnost uporabe, preglednost, izpis korpusnih zgledov.
Proti: Samo spletna različica.