Jaz nisem robot
Na številnih spletnih straneh moramo dokazati, da smo človek, ne robot. Razlogi so najrazličnejši, v glavnem pa gre za omejitve zlorab. Včasih smo v ta namen prepisovali popačene besede, danes pa pogosto zadostuje, da prepoznamo prometni znak na fotografiji ali da preprosto kliknemo napis Jaz nisem robot. Preizkus CAPTCHA je v dveh desetletjih naredil dolgo pot.

Besedilne CAPTCHA se pojavljajo v najrazličnejših oblikah. Slika: Vicarious
V internetu je dostopna slovenska zemljiška knjiga, tako da lahko vsakdo preveri, kdo je lastnik katere nepremičnine. Zaradi zaščite osebnih podatkov pa nasprotnega poizvedovanja ne dovolijo, torej ne moremo ugotoviti, katere nepremičnine vse ima kdo v lasti. In da tega ne bi kdo počel doma, moramo preprečiti, da bi si kdo iz interneta snel celotno zbirko. Trivialno bi bilo namreč napisati program, ki bi prečesal vse parcele, iz strežnika snel podatke za vsako in jih uredil v lično zbirko.
To je le eden izmed primerov, ko moramo zagotoviti, da je na drugi strani človek, in ne avtomatiziran program. Podobno je to nujno pri registraciji v forume in internetne storitve, glasovanju, preprečevanju obiska spletnih pajkov, zakrivanju elektronskih naslovov in brzdanju nezaželene pošte itd.
V ta namen se uporablja katera izmed izpeljank testa CAPTCHA, ki so jo daljnega leta 1997 izumili pri iskalniku Alta Vista. Tedaj so ljudje lahko v iskalnikovo zbirko ročno dodali povezavo do svoje spletne strani, »spamerji« pa so to hitro začeli izkoriščati. Andrei Broder je s sodelavci razvil preizkus, ki so ga lahko opravili le ljudje. Prepoznati so morali popačene znake in jih vpisati, da jim je sistem dovolil dodati vnos. Leta 2001 je bil podeljen tudi patent za ta izum.
Ime CAPTCHA pa smo dobili šele leta 2003, ko so izpopolnjeni sistem tako poimenovali na Carnegie Mellon University (CMU). CAPTCHA pomeni popolnoma avtomatiziran javni Turingov test za razlikovanje računalnikov in ljudi (Completely Automated Public Turing Test To Tell Computers and Humans Apart). Na CMU so ga izpopolnili Luis von Ahn, Manuel Blum in Nicholas Hopper, sodeloval je še John Langford iz IBM.
CAPTCHA
Trenutno so aktualni trije načini CAPTCHA. Najstarejši, ki se venomer razvija, je prepoznavanje črk in številk. Te so popačene različno, da onemogočajo optično prepoznavanje (OCR), ljudje pa z razvozlavanjem načeloma nimamo težav. Drug pogost način je skupina fotografij, izmed katerih moramo izbrati tiste, ki vsebujejo kak predmet ali osebo. Izbrati moramo vse fotografije vhodov v trgovino ali Alberta Einsteina, na primer. Tretji način je podoben drugemu, imamo na polja razrezano fotografijo. Potem moramo pokazati, v katerih poljih so vozila, prometni znaki ali kaj drugega, kar zlahka opazimo.
Manj pogoste različice so zvočne, pri čemer moramo prepoznati izgovorjene črke ali kak napis v videoposnetku oziroma reklami. Lahko se tudi zgodi, da moramo rešiti kakšno lažjo nalogo, denimo sešteti dve števili, poiskati prvo črko v besedi ali ugotoviti, kateri dan sledi torku.
reCAPTCHA
Milijoni ljudi, ki vsak rešujejo izzive CAPTCHA, predstavljajo tudi znatno računsko moč, ki je zaradi narave preizkusa od računalnikov ne moremo dobiti. Eden prvih načinov za izkoriščanje tega je reCAPTCHA, ki jo je razvil Luis von Ahn in leta 2009 kupil Google. Obiskovalcu pokažemo dve besedi, kjer rešitev za eno poznamo, saj je bila generirana, za drugo pa ne.
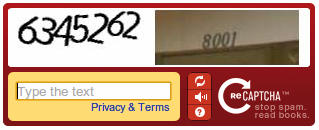
Googlova reCAPTCHA je sčasoma začela prepoznavati tudi hišne številke.
Druga beseda je navadno iz kakšne skenirane knjige, kjer zaradi popačenja OCR ni našel ujemanja. Če tako sliko pokažemo tisoč ljudem in jih večina odgovori enako, smo zastonj ugotovili, kaj je zapisano. Google zato reCAPTCHA izdatno uporablja v projektu skeniranja in digitalizacije knjig.
Projekt je od leta 2009, ko ga je Google kupil, pošteno napredoval. Zdaj tako prepoznavamo tudi hišne številke (uporabno za Google Street View) in sploh vsebino fotografij (uporabno za urjenje nevronskih mrež).
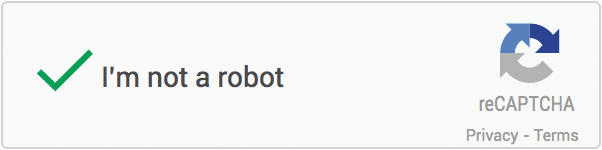
Googlova noCAPTCHA zahteva zgolj, da odkljukamo, da nismo robot. Pri tem analizira naša dejanja.
Nevronske mreže
Razvijalci CAPTCHA so v nehvaležnem položaju, saj poizkušajo vzdrževati razliko, ki jo na tisoče najpametnejših raziskovalcev na svetu želi premostiti. Enotne definicije umetne inteligence sicer ni, a končni cilj je razviti inteligenco, ki bo vsaj tako pametna kakor človek. Ne za reševanje CAPTCHA, temveč za povsem druge namene. Toda to seveda pomeni, da bo znala opravljati iste naloge, med katerimi je tudi CAPTCHA. Ko postaja umetna inteligenca čedalje boljša, postajajo nove različice CAPTCHA čedalje bolj dovršene.
Trenutno so največja »nevarnost« nevronske mreže in strojno učenje, ki uspešno prepoznavajo tudi grafično CAPTCHA. Uspešno ne pomeni, da mora prepoznati vsako CAPTCHA vedno in brez napake. Ker so računalniki hitri in jih prav nič ne moti ponavljanje, zadostujejo že nepričakovano nizki odstotki. Če lahko neko CAPTCHA zlomimo v enem odstotku primerov, je neuporabna. Računalnik bo pač poizkusil stokrat.
Najdlje so na tem področju prišli v podjetju Vicarious, ki sta ga leta 2011 ustanovila Scott Phoenix in Dileep George. Vicarious se ne ukvarja z lomljenjem CAPTCHA, temveč z razvojem umetne inteligence. Lomljenje CAPTCHA je zgolj stranski produkt. Že leta 2013 so iz Vicariousa sporočili, da so tedanji CAPTCHA premagali, letos pa so o lomljenju CAPTCHA objavili članek v reviji Science (A generative vision model that trains with high data efficiency and breaks text-based CAPTCHAs).
Ključ so nevronske mreže, katerih izvedbo so poimenovali RCN (recursive cortical network). Ta je namenjena lomljenju vseh vrst CAPTCHA, od preprostih popačenih besed do kompleksnih fotografij. RCN besede v reCAPTCHA prepoznava s 67-odstotno uspešnostjo, BotDetect (konkurent reCAPTCHA) v 57 odstotkih, Facebookov sistem v 83 odstotkih. Tudi pri prepoznavanju fotografij je RCN boljši od konkurence, pa čeprav se je učil (nevronske mreže moramo izuriti) na dobrih 1400 posnetkih, konkurenca pa na milijonih. Manjša zbirka za učenje je poglavitna prednost. Ključ je, da RCN deluje podobno kot skorja (korteks) človeških možganov. RCN prepoznava obrise in površine, potem pa hierarhično ugotavlja, kaj je na fotografiji.
To ni prvi primer, ko je bila vrsta CAPTCHA uspešno zlomljena. Že leta 2011 so raziskovalci s Stanforda ugnali zvočne preizkuse, kjer je črke bral sintetiziran glas. Leta 2014 je padel Snapchatov preizkus, v katerem so morali ljudje pri registraciji poiskati slike z obrisom duhca. Googlova prvotna različica CAPTCHA je prav tako propadla leta 2014.
Kaj pa ljudje
Poznamo še en način lomljenja CAPTCHA – človeški način. Že pred desetimi leti smo brali o indijskih farmah, kjer vam reševanje CAPTCHA zaračunajo le 2 dolarja. Za 1000 primerkov! Podobno se je ponavljalo tudi v kasnejših letih, zgodbo pa je raziskoval tudi varnostni strokovnjak Brian Krebs. Zlasti v revnejših državah so cele skupine ljudi, ki za borno plačilo rešujejo CAPTCHA, kar lahko kupimo v paketih po zgoraj omenjeni ceni. »Zaposleni« prejmejo od nekaj deset centov do enega dolarja za 1000 rešitev. To pomeni, da v enem dnevu ne morejo zbrati več kot treh dolarjev, če delajo osem ur. Sliši se obupno malo, a to so ljudje iz držav, kjer je tri dolarje na dan nadpovprečen zaslužek.
Kaj nam ostane?
Presenetljivo je, da najbolje delujejo nekatere najenostavnejše rešitve. Ko je Google leta 2014 upokojil prvo različico CAPTCHA, je namesto nje na spletno stran dodal napis Jaz nisem robot, pred njim pa je kvadrat, ki ga je treba odkljukati. Sliši se neumno, a deluje. Trik se skriva v nepopolnosti ljudi, saj miške ne bomo zapeljali neposredno do polja po premici, temveč vsaj malo naokoli. Googlovi napredni algoritmi so sposobni analizirati gibanje in z visoko verjetnostjo ugotoviti, ali se na drugi strani skriva človek. Na mobilnih telefonih nam Google pogosto servira več fotografij, med katerimi moramo na primer poiskati tiste z mačkami ali kaj podobnega.
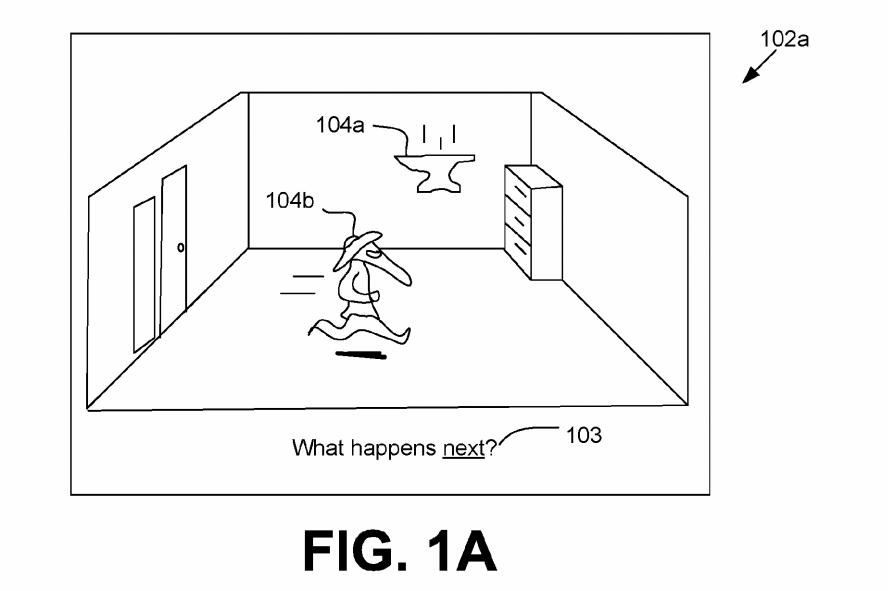
Amazon je patentiral CAPTCHA, kjer moramo poznati osnove fizike.
Računalniki tudi ne obvladajo dobro fizike na intuitivni ravni. Znajo reševati diferencialne enačbe, a iz popačene skice klade na klancu ne bodo prepoznali, da bo ta verjetno oddrsela k dnu. Amazon je patentiral takšno vrsto preizkusa. Najprej vidimo tridimenzionalno shemo nekega prostora, denimo sobe z nakovalom v zraku in človekom pod njim, potem pa moramo izbrati shemo, ki prikazuje pravilno nadaljevanje. Nakovalo bo torej padlo proti tlom na človeka.
Podoben je tudi TAPCHA, ki ga od leta 2012 razvijajo na Univerzi Bournemouth. Gre za kombinacijo prepoznavanja črk, razumevanja besedila in premikanja miške. V popačenih znakih se izpiše Premaknite kvadratni predmet z leve, potem pa moramo v spodnjem polje prijeti kvadrat in ga pomakniti.
Teoretično pa bi lahko šli tudi v drugo smer, kar opisuje še en Amazonov patent. Pri nekaterih opravilih pa so računalniki tako boljši od ljudi, da lahko izkoriščamo tudi to. Amazon je patentiral preizkus, ki ga bodo ljudje zamočili pogosteje od računalnikov. Taki primeri so štetje črk v besedilu, besedne uganke (leko, leko, leko, krava pije mleko … vodo!). Amazon računa, da bodo računalniki to znali vedno, ljudje pa se bodo motili. Toda kot velja za vsak patent, ni rečeno, da bo iz tega dejansko nastal kak izdelek.
Kritike
Da je potreba pri ločevanju med ljudmi in računalniki, ni sporno. Kljub temu ima sistem CAPTCHA nekaj pomanjkljivosti. Prva je očitno diskriminiranje slabovidnih in slepih, saj ti ne morejo reševati teh ugank. Resnici na ljubo imajo nekatere izvedenke možnost preklopa na slušno različico, kjer nam računalniški glas recitira črke, a to ni rešitev. Morda smo na napravi, ki nima možnosti predvajanja zvoka (za slabovidne je to mogoče, saj z ustrezno programsko opremo še vedo lahko berejo povečano besedilo).
To je povezano tudi z drugo kulturno težavo – ves svet vendarle ne zna angleško. Razumevanje angleške izgovarjave črk v abecedi ni samoumevno. Še težji zalogaj so moderne različice, kjer v besedilu piše, da moramo označiti vse fotografije prometnega znaka, ali so navodila še kompleksnejša, kot na primer pri TAPCHA.

Sistem TAPCHA nam v popačenem besedilu naroči, kaj moramo storiti.
Ko CAPTCHA več ne bo
Boj med razvijalci CAPTCHA in spamerji, ki imajo največ interesa za lomljenje, spominja na vojno bakterij in antibiotikov. Oboji se nenehno izboljšujejo, cilj pa je ostati korak pred zasledovalci. Dokler bodo opravila, v katerih se ljudje razlikujemo (kot kaže Amazonov patent, ni treba biti boljši) od računalnikov, bo CAPTCHA obstajal.
Vse pa kaže, da preprosti testi, kot so prepoznavanje znakov, poslušanje zvokov in analiz fotografij, ne bodo zadostovali. Google je to že spoznal, zato je uvedel analizo vseh možnih namigov, ki jih puščamo na spletni strani. Gibanje miške, prestavljanje fokusa na druga okna, časovni razmiki med pritiski na tipke in podobno so značilnosti, po katerih lahko prepozna človeka iz mesa in krvi. Lahko pa nam tudi CIA vključi spletno kamero in nas pogleda …