DNK namesto diskov
Evolucija je problem zapisa velike količine podatkov na majhen prostor že zelo učinkovito rešila. V skoraj vsaki človeški celici, ki meri do nekaj stotink milimetra, je zapisan celoten genski material, ki ga je za tri milijarde baznih parov ali kakšnih 750 megabajtov. Zakaj torej vztrajamo pri magnetnem zapisu ali siliciju? Biotehnologija že intenzivno raziskuje, kako bi enako shranjevali tudi računalniške podatke.

Današnji diski in ključki USB se zdijo s časovne distance osupljivi. V dlani z lahkoto nesemo 1 TB podatkov, kar predstavlja približno 500 milijonov strani besedila ali pa, recimo, pol milijona povsem solidnih fotografij. Pred leti je bilo to nepojmljivo. Toda ljudje smo nadvse podjetni pri ustvarjanju novih podatkov. Lani naj bi ustvarili 16 zetabajtov podatkov (to je 16 milijard terabajtov), do leta 2025 pa naj bi se letna produkcija podeseterila. Fotografij je čedalje več, filmom raste ločljivost, veliki brat polni zbirke podatkov, kopičijo se metapodatki itd. Kam bomo vse to shranili?
Ena izmed futurističnih možnosti je shranjevanj v DNK, ki jo poznamo iz celic. Narava je naletela na podoben problem, saj je morala v evoluciji v majhne celice stlačiti precej podatkov, zapis pa je moral biti zanesljiv. Človeški genski zapis vsebuje tri milijarde »črk«, pri rekorderki ribi pljučarici pa 133 milijard. In vse to je treba zapisati v (skoraj) vsako majceno celico. Narava je ta problem rešila tako učinkovito, da se zdi, kot da se kasneje sploh ni več ukvarjala s kompaktnostjo genskega zapisa. Še danes je več kot 80 odstotkov človeškega dednega zapisa brez jasne funkcije (junk DNA).
Kakorkoli obračamo, branje DNK je kemijski proces. V taki obliki je postopek seveda bistveno prepočasen za vse, razen za najdolgoročnejše shranjevanje.
Če torej lahko narava stlači petabajte podatkov v gram DNK, zakaj tega ne bi storili še mi? Tako bi lahko v majhno študentsko sobico shranili vse znanje in informacije tega sveta.
Zamisel pred svojim časom
Watson in Crick sta strukturo DNK razvozlala leta 1953 in že desetletje pozneje je Mikhail Neiman v sovjetski znanstveni reviji Radiotehnika objavil serijo člankov, kjer je špekuliral o umetnih informacijskih strojih, ki bi lahko informacije shranjevali na molekularni ravni, podobno kot DNK. Zamisel je bila preprosta in smiselna, a je bilo treba na praktično uporabnost počakati še pol stoletja. Tedaj tehnologije rekombinantne DNK sploh še ni bilo, biotehnologija pa fino manipulacijo DNK in celic omogoča šele od konca stoletja.
Umetniku Joeju Davisu in raziskovalcem s Harvarda je že leta 1988 uspelo v DNK bakterije E. coli shraniti 35 bitov podatkov. Organizirani so bili v matriko 5 × 7, kjer so enice kodirale temna področja in ničle svetla področja. V DNK so zapisali simbol stare germanske rune, ki je simbolizirala življenje in Zemljo. Ta dosežek je bil pionirski, a praktične uporabnosti še ni imel.
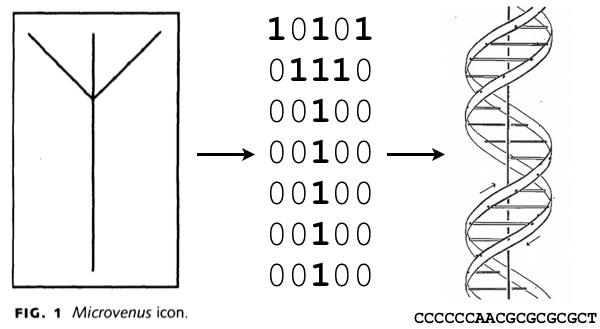
Leta 1988 so v DNK bakterije E. coli vstavili zelo kratko zaporedje, ki predstavlja germansko runo. Slika: Joe Davis
Tehnologija ujame domišljijo
Ker so imeli čedalje več podatkov za shranjevanje in nič večjih proračunov, so se znanstveniki iz biotehnoloških ved na konferencah šalili, kam bi to shranili. Pri branju DNK in genomov so nastajale gore podatkov. Kaj če bi podatke shranili kar nazaj v DNK, tako kakor v znanstvenofantastični literaturi, je nekoč predlagal Nick Goldman z Evropskega inštituta za bioinformatiko (EIB) v Veliki Britaniji. Kmalu so se nehali smejati, saj je bila to v resnici genialna zamisel. Vrgli so se na delo.
Leta 2013 so Goldman in sodelavci objavili rezultate eksperimenta, kako so v DNK shranili 154 Shakespearovih sonetov, 26-sekundni izsek iz Luthrovega govora, kopijo Watsonovega in Crickovega članka o strukturi DNK, fotografijo inštituta in seveda datoteko z navodili za dekodiranje. Skupno so v DNK shranili 5,2 megabita podatkov. Podatke so kodirali tako, da je vsak bajt zapisan kot kombinacija zaporedja petih črk A, C, G ali T (predstavljajo bazne pare, glej okvir o zgradbi DNK).
Podatki, ki jih zapišemo v DNK bakterije, tam ostanejo še generacije.
Približno obenem so na Harvardu v skupini raziskovalca Georgea Chrucha v DNK shranili knjigo s 53.000 besedami, 11 fotografijami in računalniškimi programi. S tem so dosežke iz preteklosti presegli za nekaj tisočkrat in prvikrat pokazali, da je shranjevanje podatkov v DNK tudi praktično mogoče. Po teh dveh pionirskih dosežkih je postalo jasno, da shranjevanje podatkov v DNK ni več znanstvena fantastika.
Za shranjevanje podatkov je ključnega pomena stabilnost. Za DNK vemo, da je zelo stabilna (glej okvir o stabilnosti), kaj pa, ko jo uporabimo za zapis podatkov? V naravi se namreč bazni pari A, C, G, T pojavljajo približno enakomerno in ni predolgih ponovitev iste črke, kar moramo zagotoviti tudi pri zapisu podatkov. Raziskovalci z ETH Zürich so pokazali, da lahko z ustreznim algoritmom (uporaba redundance) in hranjenjem DNK v suhem, temnem okolju pri 10° C pričakujemo, da bodo podatki berljivi brez napake še po 2000 letih. Pri -18° C se ta čas podaljša na milijon let.
Izbira algoritma
Ne glede na način in informacijo bomo imeli na koncu v DNK neko zaporedje baznih parov A, C, G, T. To pomeni, da moramo na začetku premisliti, kako bomo podatke zapisali v tej obliki. Ker znamo vse podatke predstaviti v binarni obliki za računalnike, jih bomo seveda tudi v štiričrkovno abecedo zlahka prevedli. Naivno bi pomislili, da bomo 00 pisali kot A, 01 kot C, 10 kot G in 11 kot T. To bi bil najgostejši zapis, a žal neuporaben. Pri tem početju velja biti pazljiv in poleg matematikov za pomoč povprašati še informatike in biokemike.
Kaj je DNK
Kratica DNK (v angleščini DNA) pomeni deoksiribonukleinska kislina in predstavlja molekulo, ki zapisuje dedne informacije vseh živih bitij. DNK sestavljata dve komplementarni verigi. Hrbtenico vsake verige tvorijo molekule deoksiriboze, ki so povezane s fosfatnimi skupinami. Deoksiriboza je ogljikov hidrat, torej jo podobno kot glukozo (in druge sladkorje) sestavljajo ogljikovi atomi, ki imajo nase vezane vodikove in kisikove atome. Fosfatna skupina pa je ostanek fosforne kisline, ki jo najdemo v številnih gaziranih pijačah in marmeladah. V DNK je na vsako molekulo deksiriboze v smeri prečno na verigo pripeta ena izmed štirih organskih baz – adenin (A), citozin (C), gvanin (G) in timin (T). Lepota molekule DNK je v njeni strukturi, saj se verigi orientirata v nasprotni smeri, imata komplementarni bazi (nasproti A je vedno T, nasproti C je G) in ju prek vodikovih vezi med nasprotnima bazama povežeta v dvojno vijačnico. Zaradi tega je DNK zelo stabilna. Podatki so v DNK zapisani s spreminjajočim se zaporedjem organskih baz (A, C, G, T).
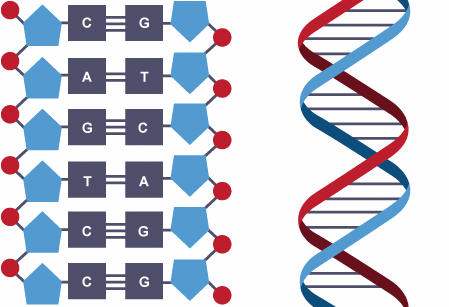
DNK gradi hrbtenica iz deoksiriboz (modro) in fosfatnih skupin (rdeče) ter bazni pari (A, C, G, T), ki zapisujejo informacije. Zavzame obliko dvojne vijačnice, v kateri verigi tečeta antiparalelno.
Zapis v DNK ni idealen, zato je treba uporabiti ustrezen kod z redundanco. Pisanje in branje imata sorazmerno pogoste napake. Po drugi strani pa DNK ni neskončno prilagodljiva in ekstremno dolge ponovitve ene baze (npr. dvajset A) niso stabilne. Še huje, trenutni sistemi za zapis in branje delujejo najbolje, če sploh nimamo zaporednih ponovitev baznih parov. Zato je treba podatke kodirati tako, da se temu izognemo.
Upoštevati je treba tudi omejitve metode, saj je daljše zapise DNK teže pripraviti brez napak. Tam nekje 200 baznih parov je zgornja meja zanesljivih sintez, zato moramo podatke razrezati v tako dolge bloke (nasproten problem bomo imeli pri branju). Ko je Goldmanova skupina pripravljala algoritem, so bili bloki dolgi 117 baznih parov. Od tega jih je sto predstavljalo dejansko vsebino, preostanek pa podatke za indeksiranje in kontrolo. Vidimo, da je izbira algoritma resnično daleč od trivialnega problema.
Ko smo se z upoštevanjem vseh zgornjih omejitev dogovorili za način zapisa podatkov, jih je treba nekako spremeniti v DNK.
Zapis
Pri »izdelavi« molekul DNK moramo ločiti med dvema zelo različnima procesoma, čeprav oba vodita do nastanke nove DNK. Pri normalnem deljenju celic, pri analizi DNK sledov ali pa pri vstavljanju tuje DNK v bakterije gre za podvojevanje ali kopiranje DNK. Na začetku je želena DNK že prisotna, izdelujejo se le njene kopije. To bomo uporabili, če bomo želeli izdelati varnostno kopijo podatkov DNK.
Ko pa želimo prvič zapisati podatke v DNK, moramo izdelati povsem novo DNK z zaporedjem, za katero nimamo matrice. Postopek se imenuje sinteza oligonukleotidov, ker se ti sorazmerno kratki koščki DNK (do 200 baznih parov) imenujejo oligonukleotidi. Načeloma bi jih lahko tudi zlepili skupaj, a za zapis podatkov v DNK to nima smisla.
DNK je stabilna
DNK je zaradi svoje zgradbe ena najstabilnejših kompleksnih organskih molekul. To seveda ne pomeni, da je DNK stabilnejša od kakšnega trdovratnega priona ali teflona, je pa glede na svojo kompleksnost presenetljivo stabilna. Medtem ko razni proteini in encimi hitro izgubijo strukturo, če se malce spremeni temperatura, DNK vse to preživi. Razlog so dvojna vijačnica in močne vodikove vezi med komplementarnimi organskimi bazami.
DNK tudi pri krajšem segrevanju do 90° C ne izgubi strukture. Po drugi strani je še danes mogoče iz več tisoč let starih zamrznjenih ostankov izolirati dele DNK. Še najbolj občutljiv je DNK na nekatere kemikalije in na sevanje. Če DNK hranimo v optimalnih razmerah, pa je praktično neuničljiva.
Kljub temu ima DNK nekaj problemov. Medtem ko molekula sama od sebe ne bo kar razpadla, se sčasoma lahko dogajajo posamične menjave baznih parov. V biologiji tem pravimo točkovne mutacije, pri zapisu podatkov pa bi jih imenovali preskok bita (bit flip). V živih sistemih jih popravljalni mehanizmi nenehno lovijo, pri shranjevanju podatkov v mrtvi DNK pa ne.
Natančen postopek njihove sinteze presega okvire tega sestavka, zato povejmo le, da gre za stopenjsko reakcijo. Korakoma drugega za drugim na fosfatne skupine pripenjamo riboze, ki imajo ustrezen bazni par (A, C, G, T). Postopek nima stoodstotnega izkoristka, prav tako ima težave, če bi želeli zapisati več ponovitev iste črke. Mimogrede, če bi bil postopek 99-odstotno učinkovit, bi po 100. koraku imeli le 36,6 odstotka želenega produkta, po 200. koraku pa 13,4 odstotka! Druga težava je počasnost, o čemer več v nadaljevanju. Seveda ne smemo pozabiti, da delamo z milijoni kopij, med katerimi defektne niso redke.

Naprava za sintezo oligonukleotidov (zapis informacij v DNK)
Goldmanova ekipa je tako sintetizirala milijone kopij želenih oligonukleotidov, ki so vsebovali zapisane informacije. Ti so v vodni raztopini, zato jo za hranjenje ali transport liofilizirajo – to pomeni, da previdno odstranijo vodo. Po domače si lahko to predstavljamo takole: goro podatkov nekako oblikujemo in zapišemo na liste papirja, ki so označeni. Potem te liste papirja prefotokopiramo milijonkrat, vsak ima kakšno črko zamazano, in jih pomešane vržemo v vrečo ter jo pošljemo prejemniku.
Nihče pri zdravi pameti ne bo danes komercialno shranjeval podatkov v DNK, a z vsako novo tehnologijo je na začetku tako.
Branje
Zdaj bi želeli prebrati, kaj piše v nekem vzorcu, polnem DNK. Postopek določanja zaporedja baznih parov v vzorcu DNK se imenuje sekvenciranje. Žal to ne gre tako, da bi program prebral poljubno dolgo DNK in izpisal zaporedje. Metod sekvenciranja je več, večini pa je skupno to, da dobimo koščke, ki so v najboljšem primeru dolgi nekaj tisoč baznih parov. K sreči naši oligonukleotidi niso daljši. Pri daljših vzorcih je treba te znati zložiti nazaj skupaj. Za to poskrbi programska oprema. Ko smo prebrali vse nukleotide, jih računalniški algoritem zloži nazaj v izvorno informacijo glede na algoritem, s katerim so bili zapisani.

Moderna naprava za sekvenciranje DNK stane 750.000 dolarjev.
In tu trčimo ob problem te tehnike. Da lahko karkoli pametnega rečemo o podatkih, moramo najprej prebrati vse zapisano. Pozabimo za trenutek na to, da še vedno potrebujemo bistveno več zmogljivosti na diskih, kot imamo podatkov v analizirani DNK, saj beremo kopije. Milijone kopij. Postopek je zelo zamuden, saj sekvenciranje vseh kosov traja od nekaj ur do nekaj dni, odvisno od metode in naprave. Kakorkoli obračamo, branje je kemijski proces. V taki obliki je postopek seveda bistveno prepočasen za vse, razen za najdolgoročnejše shranjevanje.
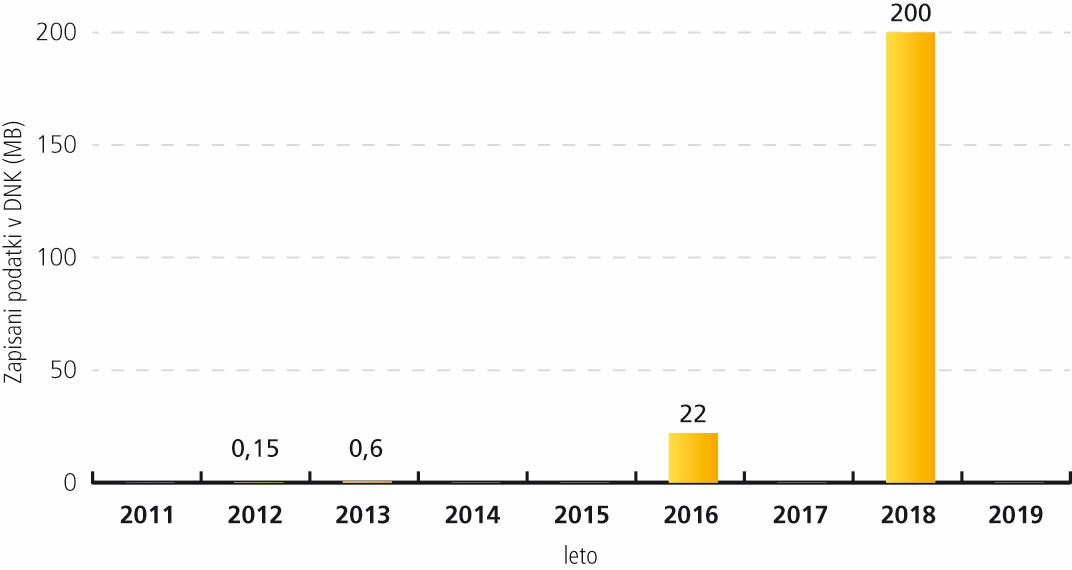
Količina zapisanih podatkov v DNK se hitro povečuje.
Microsoft zna hitreje
Da bi bilo shranjevanje podatkov v DNK vsaj načeloma uporabno tudi v praksi, je treba izdelati sistem za naključen dostop do podatkov. To sta letos pokazala Microsoft in univerza v zvezni državi Washington. Obenem jim je v DNK uspelo zapisati 200 megabajtov podatkov. Za to so potrebovali 13 milijonov baznih parov. To je bil tedaj tudi aktualni svetovni rekord, trenutno pa so že pri 400 MB. Zapisali so skupno 35 datotek različnih velikosti in to tako, da so lahko po želji prebrali katerokoli.
Še vedno niso mogli mimo osnovnega problema, to je zapisa kratkih oligonukleotidov. Podatke so zapisali v 13,4 milijona kratkih blokov, ki so bili dolgi od 150 do 154 baznih parov. Kodiranje podatkov so izvedli drugače kot predhodniki, kar kaže, da bo postavitev enotnega algoritma za zapis podatkov kot A,C,G,T verjetno eden pomembnejših korakov na poti k standardizaciji zapisovanja v DNK. Trenutno si vsak izmisli algoritem, ki je optimalen glede na uporabljeno opremo za zapis DNK in njegovo branje. Obe metodi sta pač podvrženi napakam (z verjetnostjo okrog 1 : 100), zato mora biti algoritem robusten.
Bistveni napredek Microsoftove rešitve pa je pametna uporaba začetnih oligonukleotidov (primers). Bloki DNK, ki vsebujejo podatke iste datoteke, imajo na začetku enako in unikatno zaporedje baznih parov. Čeprav se zdi to trivialno, je zelo pomembno pri branju. Pri sekvenciranju DNK uporabimo začetne oligonukleotide in tako beremo le tiste kose DNK, ki se začnejo s točno takim zaporedjem. Na ta način lahko beremo le datoteko, ki nas zanima. Problem naključnega dostopa je – čeprav zelo okorno – rešen.
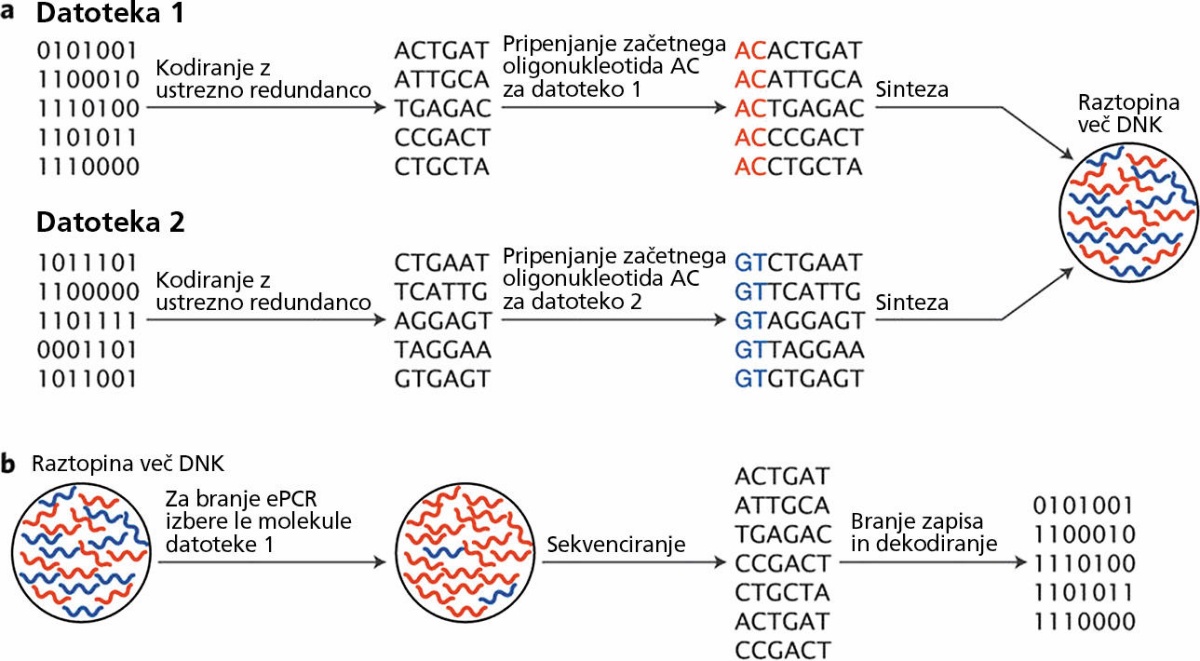
Shema zapisa in branja podatkov v DNK po Microsoftovi metodi. Slika: Heckel, R. Nature 36 (3), 2018
Shranjevanje v bakterije
Doslej zapisano govori o shranjevanju podatkov v prosto DNK, ki jo moramo primerno skladiščiti in paziti, da je kakšne kemikalije, encimi ali drugi vplivi okolja ne uničijo. Če pa bi nam uspelo podatke zapisati v DNK in jo potem vgraditi v živo bakterijo, bi bil zapis bistveno trajnejši.
Leta 2016 je to Churchevi ekipi s Harvarda uspelo z nesmiselnimi podatki, leto pozneje pa so v bakterijo shranili primitivno animacijo jezdeca. Skrivnost se skriva v moderni tehniki CRISPR, ki jo bolje poznamo iz obljub, da bo kmalu omogočila zdravljenje genskih bolezni in manipulacijo genoma živih organizmov. Leta 1993 so na Univerzi v Alicanteju odkrili, da imajo arheje in bakterije v genomu zanimiva ponavljajoča zaporedja (CRISPR), ki so prekinjena s sekvencami, ki imajo očitno neko informacijo. Izkazalo se je, da gre za ostanke okužb z bakteriofagi (virusi, ki napadajo bakterije). Ko so jih bakterije premagale, so dele njihove DNK zapisale v svoj genom, da so jih naslednjič laže premagale. Imunost so si zapisale kar v DNK! Do danes so se znanstveniki naučili, kako lahko v bakterijah izkoristijo mehanizem za CRISPR in bakteriji v genom podtaknejo poljuben DNK. Še več, leta 2013 so pokazali, da gre tako tudi z miškami in načeloma bi moralo celo z ljudmi!
Zakaj je DNK prostorna
V primerjavi s silicijem ali magnetnimi nosilci podatkov lahko DNK shrani od nekaj tisoč do milijonkrat več podatkov v enaki prostornini. Razloga sta dva. Osnovni nosilec bita je organska baza, ki meri zgolj kakšen nanometer. Poleg tega se DNK zvije v tridimenzionalno strukturo okrog posebnih proteinov histonov, pri branju (npr. podvojevanju zaradi delitve celice) pa se brez težav razvije tam, kjer branje poteka. Tranzistorje smo se sicer naučili postavljati navpično, a smo omejeni s toploto. DNK nima teh težav. Čeprav umetna DNK nima histonov, zapolni celoten prostor.
Goldmanovi ekipi je uspelo v 337 pikogramov DNK shraniti 757.051 bajtov podatkov. Če to preračunamo, dobimo gostoto zapisa 2,2 PB/ g. Eden največjih »izdelovalcev« podatkov na svetu je CERN, ki je lani presegel mejo 200 PB. CERN ima toliko podatkov shranjenih na tračnih enotah v svojem arhivu. Z DNK bi to teoretično lahko shranili v manj kot 100 gramih.
Neposredna primerjava s to številko je seveda enako neumna, kot če bi stehtali samo magnetne trakove. Nikjer ne bomo imeli shranjene stogramske kocke DNK. Vzorci bi morali biti ločeni, označeni, shranjeni v posebnih posodah in v ustreznih razmerah. Toda kljub temu bi bil prihranek prostora velikanski.
Skratka, Churcheva ekipa je pripravila DNK, ki je imel shranjeno informacijo, ki je opisovala animacijo jezdeca, ter jo s CRISPR vgradila v bakterijo E. coli. Preroško so izbrali pionirske posnetke Eadwearda Muybridgea iz leta 1879, ki je eksperimentiral s fotografijo. Resda so v E. coli shranili vsega 2,6 kilobajta, saj ima animacija pet sličic z ločljivostjo 36 × 26, torej je podatkov precej manj od megabitov, ki smo jih sposobni shraniti v DNK zunaj živih bitij. A gre za prvi korak v smer, ki obeta veliko. Podatki, ki jih zapišemo v DNK bakterije, namreč tam ostanejo še generacije.
Na Harvardu jim je v bakterijo s CRIPS uspelo shraniti animacijo. Slika: Shipman, S. L. et al. Nature 547, 345-349, 2017
Pogled od daleč
Da se ne bi izgubili v vseh podrobnostih nedvomno fascinantne tehnologije, stopimo korak nazaj in ocenimo, kaj je danes možno in kaj lahko pričakujemo v prihodnosti. Megabajt podatkov lahko na tračnih enotah shranimo za 0,01 centa, zapis v DNK pa stane več sto dolarjev. Nihče pri zdravi pameti ne bo danes komercialno shranjeval podatkov v DNK, a z vsako novo tehnologijo je na začetku tako. Cena zapisa v DNK je odvisna od razvoja dveh tehnologij – sinteze DNK in sekvenciranja DNK – in bo zagotovo upadla za več velikostnih razredov. Sekvenciranje genoma človeka je prvikrat stalo 2,7 milijarde dolarjev, danes pa ga komercialno ponujajo za 500 evrov. Zato nas tudi nekaj tisoč evrov po megabajtu zapisanih podatkov v DNK ne sme prestrašiti.
Drugi problem je hitrost, kjer nam nasproti ne bo stala ekonomija temveč kemija. DNK se ne bo uporabljal za podatke, do katerih dostopamo vsak dan, zato milisekundnih dostopnih časov ne potrebujemo. Branje je mogoče paralelizirati preprosto tako, da več enakih vzorcev sekvenciramo hkrati. Ozko grlo pa je sinteza DNK, ki jo sicer tudi lahko paraleliziramo, a je postopek še vedno zelo počasen. Za ponazoritev: če zmore disk nekaj milijonov bajtov na sekundo, jih zmore DNK nekaj na sekundo. Brez milijonov.
Analogija zapisovanja v DNK: goro podatkov nekako kodiramo in zapišemo na liste papirja. Potem te liste papirja prefotokopiramo milijonkrat, vsak ima kakšno črko zamazano, in jih pomešane vržemo v vrečo, ki jo pošljemo prejemniku. K sreči so ti listi zelo majhni.
DNK je stabilna, ni pa večna. Če jo pustimo v neoptimalnih razmerah, nabira točkovne napake, kar je za zapis podatkov problem. Trenutno se vse nezanesljivosti rešujejo tako, da imamo milijone kopij DNK in pametne algoritme, kar odpravlja tudi težave z branjem in pisanjem. Toda če počakamo dovolj dolgo, bo vseh milijon kopij pokvarjenih. V resnici ni treba čakati tako dolgo, saj je dovolj že, da ni več ene prevladujoče različice, pa ne bomo vedeli, kaj je prav in kaj ni. Toda če DNK shranimo v suhem, hladnem in temnem prostoru, po možnosti enkapsulirano v siliki, lahko zdrži tisočletja, kažejo raziskave.
Klasični disk ima magnetno ploščo in pisalno-bralno glavo, ki jo krmili nekaj elektronike. Samostojna naprava za zapis in branje podatkov v DNK bi morala imeti tehnologijo za sintezo DNK, opremo za sekvenciranje DNK, skladišče za DNK v stabilnih razmerah, ustrezno količino pomnilnika in računske moči za analizo, dostop do potrebnih kemikalij in še kaj. Nikjer ne piše, da to ni mogoče, bo pa še trajalo. A enako je bilo tudi z umetnim inzulinom, vesoljsko tehnologijo in jedrskim reaktorjem.
Bitcoin v DNK
Nick Goldman z EBI je leta 2015 pripravil zanimivo uganko. S sodelavci je v DNK zapisal podatke, ki so omogočili dostop do ene bitcoinske denarnice, ki je vsebovala 1 bitcoin (tedaj 200–300 evrov, letos že tudi prek 10.000). Na srečanju ekonomskega foruma v Davosu je 21. januarja 2015 razdelil vzorce DNK in komur bi uspelo prebrati informacije iz DNK, bi si lahko izplačal ta bitcoin. Natečaj je trajal tri leta, znane pa so bile osnovne informacije, kako so podatki v DNK kodirani.

Takole je bila videti centrifugirka z vzorcem DNK, ki je vseboval ključ do enega bitcoina.
Ko je že kazalo, da bo nagrada ostala nepodeljena, se je je decembra lani lotil doktorski študent Sander Wuyts s Katoliške univerze Leuven. Prepričal je Goldmana, da mu je poslal en vzorec, in se lotil dela. Po mesecu dni mu je skupaj s sodelavci uspelo dekodirati zapis v DNK in tik pred rokom dobiti bitcoin. Podroben zapis je v njegovem blogu.
Sander Wuyts je po skoraj treh letih prvi rešil uganko in iz DNK izluščil zasebni ključ denarnice z enim bitcoinom.