Čigava je pa tale?
Že kar nekaj časa so nam prihranjene tegobe ugotavljanja, kdo izvaja neko priljubljeno skladbo. Ko se kje predvaja, na telefonu zaženemo aplikacijo Shazam, posnamemo 10-sekundni izsek, pa aplikacija izpiše izvajalca in naslov. V ozadju čarovnije se skrivajo velikanske zbirke podatkov in veliko matematike.
Ko so leta 2010 Mirana Rudana spraševali, zakaj so Pop Design skladbo Na božično noč prekopirali z nemškega originala Man of the World zasedbe The Window Speaks, je tarnal, kako se je leta 1988 skladba vrtela na nemških radijskih postajah, a nikakor niso mogli najti avtorja. Da se danes to ne more več zgoditi, skrbi podjetje Shazam z istoimensko aplikacijo, ki je tako priljubljena, da je »shazam« v angleščini postal kar glagol, nekako kot »gugl«. Ko slišimo všečno skladbo, jo s telefonom poshazamamo, da se nam izpišeta naslov in izvajalec. Naloga je tako jasna, da jo razume vsakdo. S telefonom želimo posneti nekaj sekund skladbe, potem pa mora aplikacija kljub zelo nepredvidljivi kakovosti (različni mikrofoni v telefonih, hrup iz okolice, vir posnetka …) prepoznati, za katero pesem gre.
Uspešnost
Shazam je presenetljivo zanesljiv in hiter. Če neke skladbe ne prepozna v nekaj sekundah, je skoraj zagotovo nima v zbirki in ni problem v kakovosti posnetka ali algoritmu. Nastopov v živo pa ne prepoznava, ker skladbo vsakokrat odpojejo nekoliko drugače. Če vam na kakšnem koncertu vendarle s Shazamom uspe najti skladbo, ste izvajalca z veliko verjetnostjo razkrinkali, da uporablja playback.
Iz analognega v digitalno
Zvok je longitudinalno valovanje, ki se prenaša po zraku. Molekule zraka usklajeno nihajo v isti smeri, po kateri se širi mehanski val, zato se nekoliko spreminja krajevni zračni tlak. Sluh ni nič drugega kakor fiziološko zaznavanje nihanja zračnega tlaka v ušesu, ki se prek koščic in živčnega sistema prenaša v možgane. Anatomija ušesa je odgovorna, da je človeški sluh precej omejen. Slišimo frekvence med 20 in 20.000 Hz, najmanjša še zaznavna amplituda nihanja tlaka (pri 1 kHz) pa je 20 μPa. Običajni zračni tlak je 101 kPa, torej za slišni zvok zadostuje lokalna sprememba za pet milijardink!
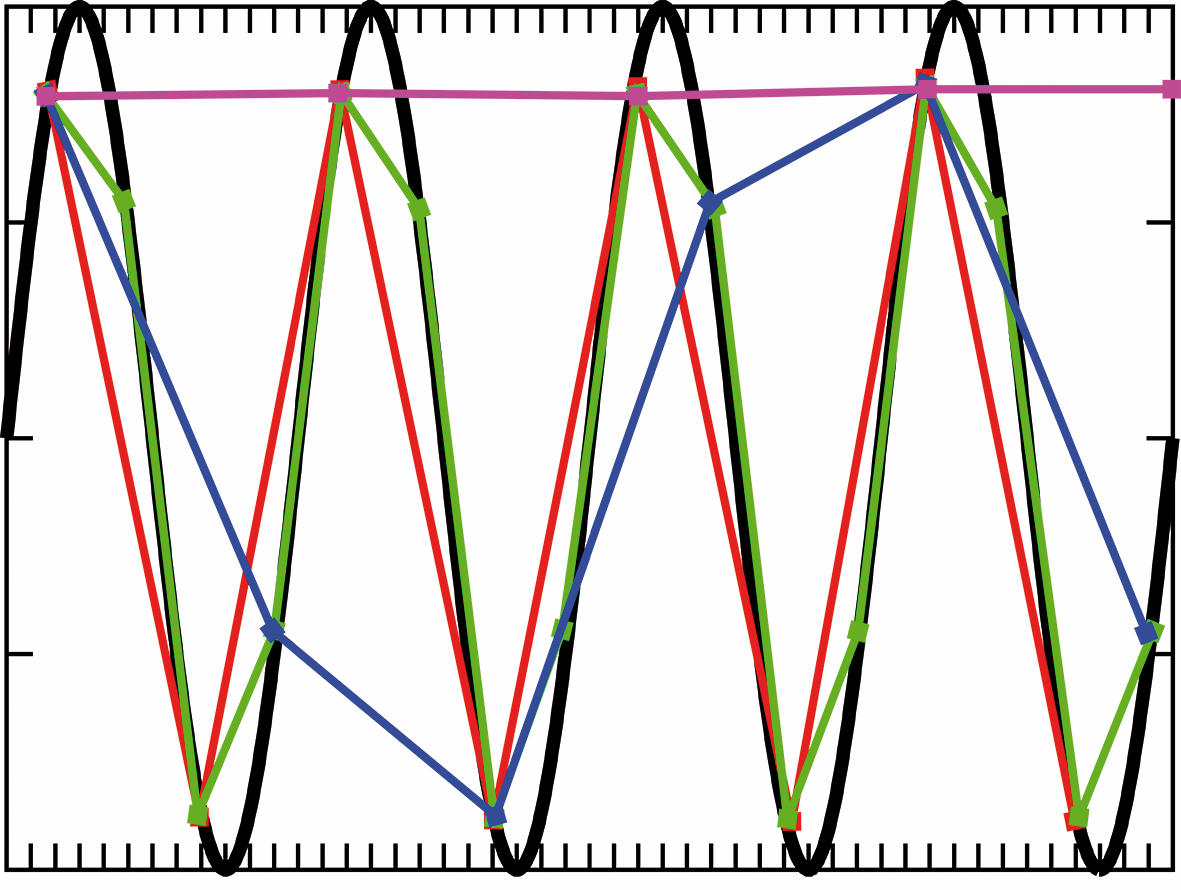
Če sinusni signal (črno) frekvence υ vzorčimo s frekvenco 4υ (zeleno) ali 2υ (rdeče), je rezultat pravilen. Vzorčenje s frekvenco 4/3 υ signal popolnoma popači, pri vzorčenju υ pa dobimo konstanten signal.
Če vam na kakšnem koncertu s Shazamom vendarle uspe najti skladbo, ste izvajalca z veliko verjetnostjo razkrinkali, da uporablja playback.
Če želimo zapisati zvok, moramo zgolj poznati, kako se s časom spreminja zvočni tlak. V analognih časih je res zadostovalo, da je mikrofon beležil zvok in ga pretvarjal v električni signal spreminjajoče se jakosti, ki smo ga zapisali na analogni medij. Tako zapisanega zvoka ni mogoče popolnoma zvesto kopirati in je neprimeren za obdelavo z računalniki. Zato se danes zajeti zvok digitalizira. Pri digitalizaciji se moramo odločiti, kako pogosto (frekvenca) in kako nadrobno (resolucija) bomo signal vzorčili. Iz fizioloških in zgodovinskih razlogov se uporablja 44,1 kHz in 16 bitov (216 stopenj). Nyquist–Shannonov izrek vzorčenja pravi, da moramo signal vzorčiti vsaj z dvakrat višjo frekvenco od najvišje frekvence, ki je prisotna v signalu. Zvočni signal moramo še prej poslati skozi filter, ki poreže vse frekvence nad 20 kHz. Višjih frekvenc ne slišimo, a bi pri vzorčenju s 44,1 kHz povzročile pojav nižjih slišnih frekvenc (aliasing).
Stari in novi izum
Za ključni izum za računalniško obdelovanje zvoka pa se moramo zahvaliti Josephu Fourieru, ki je pred dobrimi dvesto leti pokazal, da je mogoče vsako periodično funkcijo zapisati kot (neskončno) vsoto sinusnih in kosinusnih funkcij. Premislimo, kaj to pomeni za zvok. Vsak časovni zapis zvoka (odvisnost amplitude od časa) lahko pretvorimo v frekvenčni histogram (intenziteta pojavljenih frekvenc)! Ker je zvok zapisan digitalno (torej kvantizirano), potrebujemo diskretno Fourierovo transformacijo (DFT). Ta ima v naivni izvedbi računsko zahtevnost O(n2), kar je preveč. Zato ni presenetljivo, da je leta 1965 odkriti splošni algoritem za hitro Fourierovo transformacijo (FFT) z zahtevnostjo O(n log n) eden najpomembnejših dosežkov aplikativne matematike.
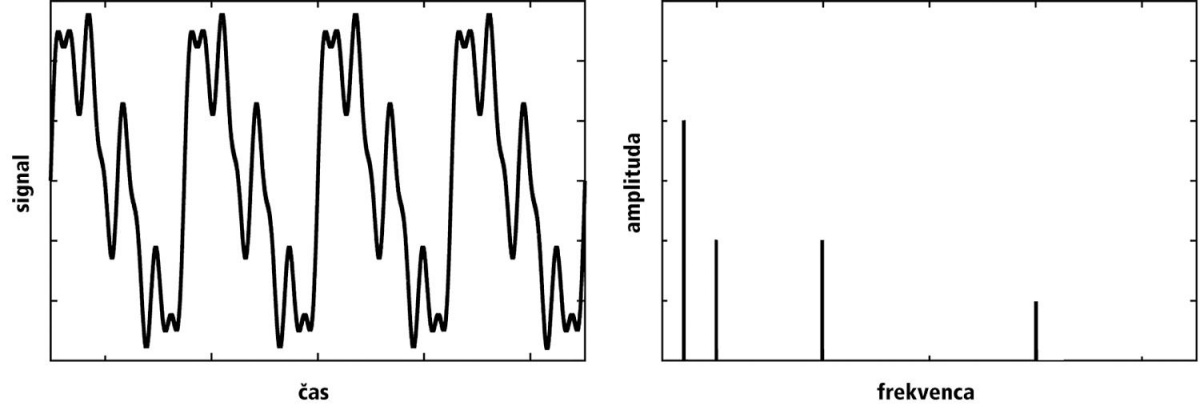
Fourierova transformacija omogoča signal iz časovne domene preslikati v frekvenčno domeno, kar bistveno olajša manipulacijo zvoka.
S FFT lahko vsak posnetek zvoka razstavimo v spektrogram. Upoštevati moramo še to, da je dogajanje v skladbah lokalizirano – trenutni zvok nima nikakršnega vpliva na dogajanje čez 10 sekund. FFT torej ne bomo izvajali na celotnem posnetku, temveč na kratkih koščkih. V ta namen uporabljamo okenske funkcije, ki odrežejo le en kos posnetka, ter potem na kompozitumu okenske funkcije in signala izvedemo FFT. Podrobnosti izbire okenske funkcije presegajo okvire tega pisanja, zato povejmo le, da smo omejeni tudi s frekvenco vzorčenja (44,1 kHz). Rezultat FFT je vedno porazdelitev po frekvenčnih razredih – frekvenc, ki se razlikujejo za manj od širine razreda, ne razlikujemo. Čim ožji so frekvenčni razredi, tem daljše časovno okno moramo vzeti. V praksi: pri frekvenčni ločljivosti 10,7 Hz je časovna ločljivost 0,1 sekunde (hitrejših sprememb ne zaznamo), pri frekvenčni ločljivosti 2,7 Hz pa že 0,37 sekunde. Zato iščemo kompromis.
Prstni odtis skladbe
Zdaj smo opremljeni z vsemi potrebnimi orodji. Za vsako skladbo lahko zapišemo spektrogram, ki je v resnici tridimenzionalni graf dogajanja v njej. Na eni osi je čas v skladbi, na drugi osi so tedaj prisotne frekvence, na tretji osi (na sliki je prikazana
kot barvna vrednost) pa njihova intenziteta. To je popoln opis dogajanja v skladbi.
Tu se konča splošna teorija diskretne obdelave signalov in prične Shazamova genialnost. Iz spektrograma pesmi je treba izdelati prstni odtis, ki bo primeren za prepoznavanje skladb. Odtis mora biti časovno lokaliziran (izračunan iz dogajanja blizu izbrane točke v času, saj časovno oddaljeni dogodki nanj ne smejo vplivati), neobčutljiv za premik (skladbo lahko začnemo poslušati kjerkoli), robusten (slaba kakovost posnetka ga ne sme spremeniti) in z dovolj visoko entropijo (različni skladbi morata imeti dovolj različna podpisa, da ni lažnih pozitivnih zadetkov). Sliši se kot nemogoča naloga, pa ni tako.
Izkazalo se je, da je najboljša rešitev prav najpreprostejša. V spektrogramu zanemarimo popolnoma vso vsebino razen vrhov, ki predstavljajo najmočnejše intenzitete. Kandidati za izbrane vrhove so točke, ki imajo višjo intenziteto od vseh okoliških, dejansko izbrane pa so potem tiste, ki poskrbijo za enakomerno vzorčenje po celotnem časovno-frekvenčnem prostoru. Iz spektrograma dobimo množico točk, ki se imenuje ozvezdje (constellation map), ker spominja na nebesni svod. Zanemari se tudi intenziteta vrhov, ostanejo le njihove lokacije (čas in frekvenca). Tako preprosta rešitev s tako velikansko količino zanemarjenih informacij deluje zato, ker prav vrhovi z največjo verjetnostjo preživijo vse popačitve, ki se zgodijo na poti do aplikacije Shazam, in ker je že sama porazdelitev vrhov v časovno-frekvenčnem prostoru unikatna za pesmi (če niso plagiat). Celo različne priredbe iste pesmi imajo različen prstni odtis.
Primerjava odtisov
Od tod do končnega cilja je le še korak. Shazam ima v svoji zbirki kup skladb, za katere izdela prstne odtise. Aplikacija na telefonu za vsak izsek, ki ga poslušamo, izdela svoj prstni odtis. Zdaj je treba samo še pametno primerjati tako izdelan prstni odtis z zbirko podatkov, da bomo zadetek našli dovolj hitro in z dovolj visoko zanesljivostjo. Iskanje zadetka si lahko vizualiziramo takole. Prstni odtis skladbe v zbirki podatkov in prstni odtis poslušane skladbe sta enaka, le da sta po časovni osi zamaknjena, ker skladbe nismo začeli snemati na začetku. Če ju primerno premaknemo, se bosta prekrila.
Zato iz prstnih odtisov v zbirki izračunamo zgoščene vrednosti (hash). V ozvezdju izberemo sidrne točke, potem pa vsaki pripišemo območje vpliva v časovno-frekvenčnem prostoru. Za povezavo med sidrno točko in vsako točko v območju vpliva izračunano zgoščeno vrednost iz frekvenc obeh točk (ν1, ν2) in relativne časovne razdalje (time offset) med njima (t2-t1) ter jo shranimo kot funkcijo časovne razdalje sidrne točke od začetka skladbe (t1). Za vsako skladbo se izdela seznam tako definiranih zgoščenih vrednosti (hash[ν1,ν2,t2-t1];t1). Metoda zgoščenih vrednosti namesto primerjave celotnih ozvezdij se uporablja zaradi izjemnega časovnega prihranka – v zameno za nekajkrat več podatkov (parov točk je več kot točk) je iskanje 10.000-krat hitrejše.
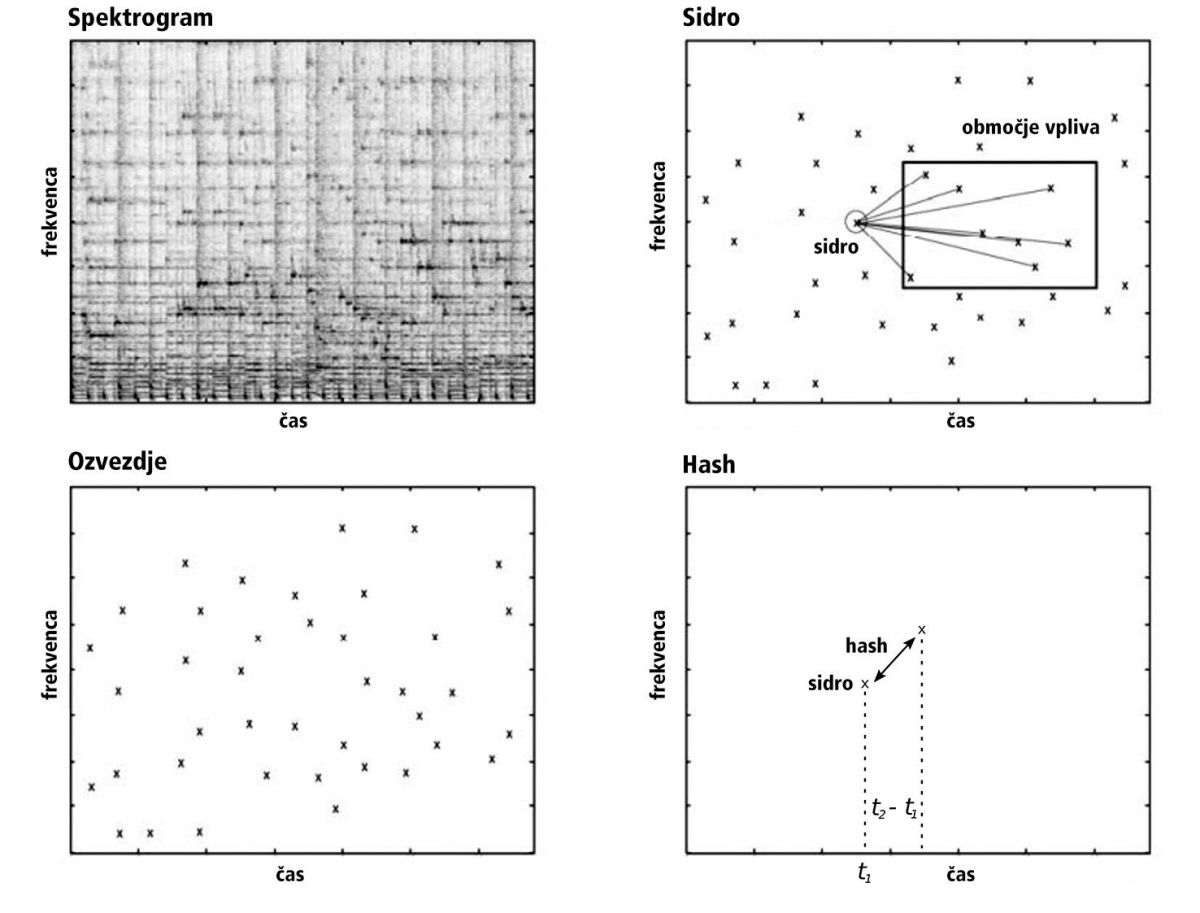
V spektrogramu skladbe zavržemo vse informacije, razen pozicije vrhov, da dobimo ozvezdje. Izberemo nekaj sidrnih točk in jim priredimo območje vpliva ter iz razdalje med sidrno točko in vsako točko v območju vpliva izračunamo zgoščeno vrednost (hash). Vir: Avery Li-Chun Wang, An Industrial-Strength Audio Search Algorithm.
Ugotavljanje ujemanja je zdaj zelo preprosto. Vsako zgoščeno vrednost iz izseka, ki ga želimo prepoznati, iščemo tudi v zbirki vseh skladb. Če najdemo ujemanje, na grafu ujemanja narišemo točko. Na eni osi je čas t1, ko se ta zgoščena vrednost pojavi v izseku, na drugi osi pa čas t1', ko se pojavi v skladbi iz zbirke. Če gre za različni skladbi, je rezultat raztreseni graf brez korelacije, saj se iste zgoščene vrednosti (ne pozabimo, da vsaka predstavlja en par točk) pojavljajo na različnih mestih. Če pa je skladba ista, bomo veliko točk zagledali na premici iz očitnega razloga. Iste zgoščene vrednosti se v obeh posnetkih pojavljajo v enakem časovnem zaporedju, le začetek je zamaknjen, ker skladbe ne poslušamo od začetka.
Algoritem mora le še ugotoviti, ali se je pojavila množica točk, ki ustvarjajo diagonalo. To je preprost problem s številnimi rešitvami (npr. s Houghovo transformacijo), a ga je treba izvesti dovolj hitro, da je metoda praktično uporabna. Spet se izkaže, da so najboljše rešitve najpreprostejše. Ker iščemo premico, za vsak par točk izračunamo razliko med koordinatama (t1'‑t1). Rezultate prikažemo kot histogram teh razlik. Če točke niso korelirane, bo histogram vseboval vse vrednosti s podobnimi pogostnostmi. Če pa imamo na grafu več točk, ki tvorijo premico, bodo imele vse enako razliko med koordinatama (δt , ker je enačba premice te t1 = t1' + δt). V histogramu bomo videli natanko en vrh, ki bo vsaj za velikostni razred prekašal vse druge. Našli smo iskano skladbo.
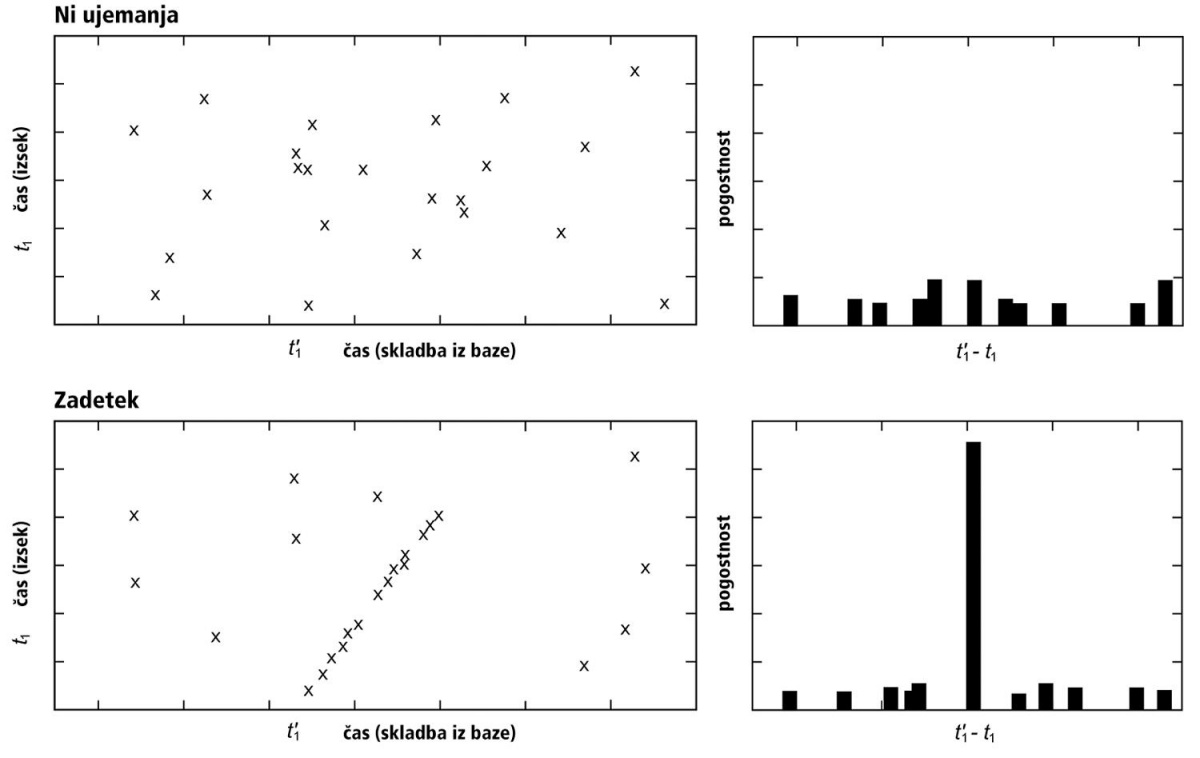
Graf ujemanja zgoščenih vrednostih v izseku in skladbi iz zbirke. Če imamo zadetek, vidimo veliko točk na diagonali. Slednjo algoritemsko najlaže prepoznamo tako, da narišemo histogram razlik koordinat vseh parov točk. Vir: Avery Li-Chun Wang, An Industrial-Strength Audio Search Algorithm.
Več podrobnosti o delovanju Shazama je njegov soustanovitelj prikazal v članku An Industrial-Strength Audio Search Algorithm. Detajle o predstavitvi in obdelavi zvoka v računalniku pa najdete v vsakem učbeniku ali skriptih iz Analize signalov.